The Definitive Guide to Data Lakes
Introduction
Let’s start by asking the most basic questions – What is a data lake?
A data lake is a central repository that allows you to store all data sources – unstructured and semi-structured – in a volume. Data lakes are usually built on low-cost commodity hardware, making it economically viable to store terabytes and petabytes of data.
Data is typically stored in a raw format without first being fine-tuned or structured. From there, it can be scrubbed and optimized for the purpose at hand, be it a dashboard for interactive analytics, downstream machine learning, or analytics applications. Ultimately, the data lake infrastructure provides users and developers with self-service access to siloed information. It also enables your data team to work collectively on the same information, which can be curated and secured for the right team or operation. Today, it has become a core component for companies moving to modern data platforms to scale their data operations and machine learning initiatives.
On-premises vs Cloud
Enterprise’s data lakes are split into two industry trends – on-premises data lakes and cloud-based data lakes. Although initially data lakes were created on-premises, the movement to the cloud is accelerating. In fact, the cloud market for data lakes is growing two to three times faster than the on-premises data lake market. In an on-premises data lake, enterprises manage both software and hardware assets that house their data. If their data volume grows beyond the hardware’s capacity, they have no other choice but to buy more computing themselves.
In cloud data lakes, enterprises pay as they use the storage and compute they need, which means they can scale up and down as their data requires. This scalability has been a huge breakthrough in Big Data adoption, driving the increased popularity of data lakes. Adopting the cloud as the preferred infrastructure for building data lakes is being driven by businesses that are new to data lakes and adopting the cloud for the first time and enterprises that had built data lakes on-premises but now want to move their infrastructure to the cloud.
Big Data vs Data Lake
Big data, by definition, describes three different types of data: structured, semi-structured, and unstructured. From all the promise that big data holds, very few companies have been able to extract the full potential from the data they collect and store these days. With the increase in connectivity and proliferation of data-producing devices — the internet of things (IoT), mobile, social media, application, and machine logs — enterprises are capturing and processing unprecedented amounts of data globally.
An IBM report estimated we generate 2.5 quintillion bytes of data each day (one quintillion is one thousand quadrillions, which is one thousand trillion). McKinsey estimates that more than 70 percent of the potential value of all data is unrealized, and only one percent of big data captured in an unstructured format is analyzed or put to use. In short, we are getting good at capturing a lot of data. However, ensuring this data is available to users to inform business decisions usually reveals big problems with the economics of scaling and making data available across all consumption points.
To expand from a few focused projects and transition to a truly data-driven business — where data informs every business decision — organizations need to focus on a cloud-first data lake. The cloud data lake has shaped into a market-changer today as businesses can instantly access infrastructure and advanced technologies with a few clicks. This has allowed the data team to be the entire platform’s enabler and no longer a bottleneck. Read more on why you need a cloud-native platform to succeed with Big Data
At the Data Lake Summit, Siddhant Srivastava, Principal Software Engineer at Swiggy, took a deep dive into how Swiggy is leveraging insights to make hyper-fast, hyper-local and real-world decisions in his session titled Powering Real-time decisions with Big Data and Microservices
Data Lake Analytics
Data Lakes are a core pillar in an organization’s data strategy. Data lakes make organizational data from different sources accessible to various end-users like business analysts, data engineers, data scientists, product managers, executives, etc. In turn, these personas leverage insights from this data in a cost-effective manner for improved business performance. In fact, many forms of advanced analytics are currently possible only in data lakes. For example, one can store vast amounts of (unstructured) text and run State-of-the-art Natural Language Processing on it. Along similar lines, one can store video data for Data Science usage.
Whether you are starting your Data Lake journey, or already operating a data lake, be sure to check this excellent primer on Data Lake Essentials before continuing. We have outlined the strategies for ingesting data into the Lake in these three-part blogs:
- Part 1: Ingestion to the Data Lake
- Part 2: Optimizing the ingestion pipelines
- Part 3: Advances in ingestion – Transactions on the Data Lake
Check out Jorge A. Lopez, Global Segment Lead, Analytics, AWS presentation on ‘Data Lakes and Machine Learning: Driving innovation with your data’ to understand some of the key trends in analytics and how customers are using these trends to fuel innovation.
Case for Building Data Lakes in Cloud
Cloud data lakes are enabling new business models and near real-time analytics to support better decision-making. With the cloud come the following key benefits:
- Scalability: With a cloud data lake, you can analyze, process, and store unlimited amounts of data. By scaling up resources when you need them, you can minimize costs by paying only for the computing and storage you need. This helps enterprises with financial governance to ensure that they stay within assigned budgets.
- High-performance: The resources available from cloud providers are virtually infinite, giving you the ability to scale out performance as well as a broad range of configurations for memory, processors, and storage options.
- Built-in-security: When it comes to security, cloud providers have gathered knowledge and best practices from all their customers and have learned from the trials and errors of thousands of other companies. The cloud providers have dedicated security professionals working on continually improving the security of their platforms.
- Cost-efficiencies: With the cloud, you reap cost efficiencies on two levels. First, you’re paying only for the compute you need, and the tools you use are explicitly built for the cloud architecture. Automation technologies like Qubole prevent failure and lower the risks of operating on big data at a scale, which offers a huge value for the DevOps team. Second, your operational costs are much lower because the cloud boosts the productivity of your IT personnel. They don’t spend time managing hardware or software for infrastructure, which includes never again having to perform an upgrade. All of which are taken care of by cloud providers.
A lot of these benefits come without having to reinvent and maintain the wheel when it comes to your infrastructure. A cloud-based data lake enables you to operationalize the data lakes at an enterprise scale and at a fraction of the cost, all while taking advantage of the latest innovations.
Interested to learn more about the domain-driven data architecture and how it aligns data and product source or target experts? Check out The Walt Disney Company Senior Software Architect Caleb Jones’s Data Lake Summit on-demand session on Domain-driven Architecture.
Building a Data Lake the Right Way
Data-driven companies are driving rapid business transformation with cloud data lakes. As the number of workloads migrating to the cloud data lakes increase, companies are compelled to address data management issues. The combination of data privacy regulations and the need for data freshness with data integrity is creating a need for cloud data lakes to support ACID transactions when updating, deleting, or merging data. Take a look at the architectural considerations for building cloud data lakes to address this requirement.
Also, check out this on-demand session by Prabhu Prakash Ganesh, Chief Technology Officer at MiQ to understand how MiQ is building and scaling a data and analytics ecosystem.
Qubole Data Service on AWS Cloud
Qubole’s Platform provides end-to-end data lake services such as cloud infrastructure management, data management, continuous data engineering, analytics, and machine learning with near-zero administration.
Get started with Qubole on AWS Cloud in three simple steps. However, we recommend you check the complete user guide here.
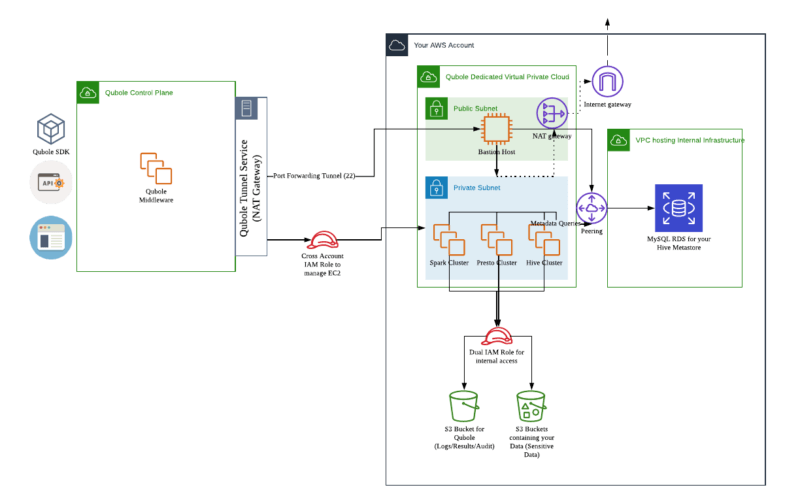
- Account Integration: Authorize Qubole to orchestrate the open data lake in your AWS cloud account. This entails setting up IAM Roles and creating an S3 bucket for use by Qubole.
- Network Integration: Setup the required networking infrastructure. To process the data in the data lake, Qubole orchestrates big data engines in your cloud account. This requires a VPC, Subnets, Endpoints, Security Groups, Route Tables, NAT Gateways, Internet Gateways, and a Bastion Host for secure access.
- Hive Metastore Integration: A data lake’s central source of truth is a metastore. Qubole advocates the use of the Hive Metastore. Qubole provides one out of the box. However, it is recommended that a self-hosted metastore be used. This entails creating VPC, RDS, DB Subnets, and DB Subnet Security Groups. It further requires initializing the RDS with the Hive Metastore Schema and peering at the RDS with the Data Lake’s Network Infrastructure for secure access.
Here’s a reference architecture of what a fully integrated Qubole environment looks like on AWS Cloud:
AWS Terraform
We have created Terraform Scripts that allow DevOps teams to define the Qubole Open Data Lake Infrastructure setup as code for easy versioning, provisioning, and reuse. The above-mentioned steps are defined as independent modules in this Terraform Repository. They can all be used in one go, or one by one. Learn how Terraform can be used to instantiate the Qubole Open Data Lake on AWS Cloud.
AWS PrivateLink on Qubole
Furthermore, Qubole enhanced its platform security by supporting AWS PrivateLink in 2019. Qubole with AWS PrivateLink makes it easy to connect services across different AWS accounts and VPCs, and significantly simplifies network architecture. When a customer configures the Qubole Platform through AWS’s PrivateLink connectivity, the traffic between Qubole VPC and the customer’s VPC does not traverse through the public internet. Here’s how you can enhance network security with AWS PrivateLink on Qubole.
Qubole Data Service on Google Cloud
Qubole Data Platform on GCP offers data science and data engineering teams a rich and unified experience with built-in notebooks, dashboards, and an integrated workbench to execute any command, all available right within the platform.
Qubole’s data platform is built on a modern scalable control plane using Kubernetes and hosted natively in Google Cloud. The control plane authenticates users into the service using their Google Cloud account and provides access via a User Interface (UI), APIs, or SDK. Its provisions and orchestrates big data clusters within a VPC in the customer’s GCP project, and fully handles autoscaling of these clusters and their access to data stored in Google Cloud Storage and BigQuery storage.
Follow these three modules to implement Qubole on Google Cloud:
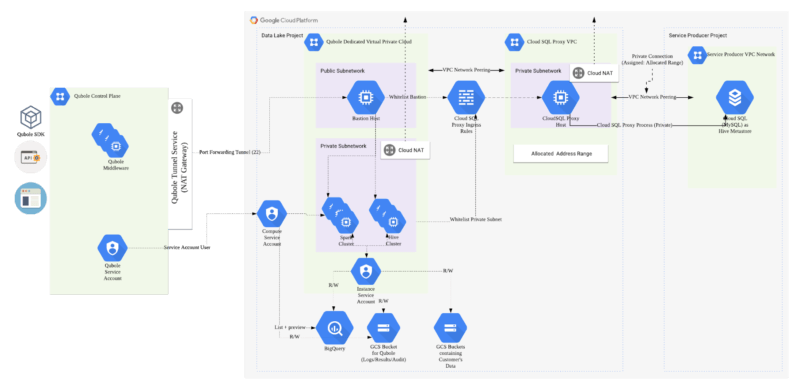
- Account Configuration: This module will create Instance service accounts and Compute Service which will be used to provide access to Cloud Storage and BigQuery and orchestrate the compute managed by Qubole.
- Network Infrastructure: This will implement the security controls necessary for a Data Lake architecture which includes VPC, subnets firewall rules, and Bastion host.
- Hive Metastore: This module will implement the CloudSQL (MySQL) instance and enable access to it via cloud SQL proxy
Here is a reference architecture of what a fully integrated Qubole Environment looks like:
Discover what makes for a Modern Data Architecture and how to build a modern data platform on Google Cloud. Click here to view the webinar.
Cloud Data Lake – Best Practices
Nowadays, gaining a competitive advantage from data goes beyond BI to applications ranging from interactive, streaming, and clickstream analytics to machine learning, deep learning, and more. For these applications, data lakes provide optimal architecture. Data arrives from multiple sources in different forms and velocities and gets staged and cataloged into a central repository. It is then made available for any type of analytics or machine learning at any scale in a cost-efficient manner.
A cloud data lake can break down data silos and facilitate multiple analytics workloads at scale and at lower costs. There are three broad areas that the data teams need to pay attention to building effective data lakes – Data Ingestion, Data Layout, and Data Governance. Let’s take look at the best practices in setting up and managing data lakes across three dimensions
- Data Ingestion Best Practices:
Data ingestion can be in both batch and streaming format. For batch ingestion of transactional data, the data lake must support UPSERT – row-level inserts and updates — to datasets in the lake. UPSERT capability with snapshot isolation and ACID semantics simplifies the task, as opposed to rewriting data partitions or entire datasets. ACID semantics ensures concurrent writes and reads are on a data lake without issues with data integrity issues or reduction in reading performance.
For streaming data, the data lake must guarantee that data is written exactly once or at least once. A recommended combination is Spark Structured Streaming in conjunction with streaming data arriving at variable velocity from message queues such as Kafka and Amazon Kinesis. A data lake solution for stream processing should integrate with the schema registry in message queues and must support replay capability to keep up with business evolution on stream processing and reprocess or reinstate outdated events.
- Data Layout Best Practices:
Inspecting, exploring, and analyzing large sets of semi-structured and unstructured datasets in their raw format is tedious because the analytical engines scan the entire dataset across multiple files. Here are five ways to reduce data scanned and reduce query overheads:
- Columnar data formats for read analytics: Use open-source columnar formats such as ORC and Parquet to reduce data scans and avoid queries that need to parse JSON by using json_parse and json_extract.
- Partition data: Use the time, geo, and lob to reduce data scans, and tune partition granularity based on the data set under consideration (by hour vs. by second)
- Compaction to chunk up small files: Chunk up small files into bigger ones asynchronously to reduce network overheads
- Perform stats-based cost-based optimization: Collect dataset stats like file size, rows, and histogram of values to optimize queries with join reordering.
- Use Z-order indexed Materialized views for cost-based optimization: A z-order index serves queries with multiple columns in any combination and not just data sorted on a single column.
- Data Governance Best Practices:
With data lakes, multiple teams have access to the data. However, there is a need for a strong focus on oversight, regulatory compliance, and role-based access control along with delivering meaningful experiences. A single interface for configuration management, auditing, obtaining job reports, and exercising cost control is key. Here are three recommendations for data governance:
- Discover Your Data: Having a data catalog helps users discover and profile datasets for integrity by enriching metadata through different mechanisms, documenting datasets, and supporting a search interface.
- Regulatory and Compliance Needs: The data privacy regulations, such as GDPR and CCPA, have created new requirements around the Right to Erasure and Right to Be Forgotten. Therefore, the ability to delete specific subsets of data without disrupting a data management process is essential. In addition to the throughput of DELETE itself, you need support for special handling of PCI/PII data and auditability.
- Permissioning and Financial Governance: Using the Apache Ranger open-source framework that facilitates table, row, and column level granular access, architects can grant permissions against already-defined user roles in the Identity and Access Management (IAM) access solutions of cloud service providers. With wide-ranging usage, monitoring and audit capabilities are essential to detect access violations and flag adversarial queries. To give P&L owners and architects a bird’s eye view of usage, they need cost attribution and exploration capabilities at the cluster – job- and user-level from a single interface.
Data Lake As a Service
As machine learning initiatives grow more widespread, the data kept in a data lake are becoming increasingly valuable to larger portions of a company. It is becoming imperative that businesses eliminate the data accessibility bottleneck — for the success of their data-related projects and the broader organization. Self-service analytics alleviate many of the pain points that naturally occur with a data lake, giving control back to the individual user and increasing productivity across the organization. With self-service, data users gain the ability to analyze predetermined data sets and discover, query, and visualize virtually any type of data. Through self-service, users can also perform four steps that traditional Business Intelligence (BI) and analytics tools may lack: discovery, ad hoc querying, visualization, and collaboration. Read the four key characteristics of self-service analytics.
Data Lake Technologies
The big data ecosystem is extremely complex – just making sense of the right tools and technologies can be more complicated than data mining. Embracing choice and picking the right engine at each step of the analytics pipeline is critical to ensuring success.
These tools – in various combinations – can be used with your cloud-based data lake. And Qubole allows you to use these tools at will depending on your team’s skills and your particular use cases.
Apache Spark
Spark is an in-memory cluster computing framework originally developed at the University of California, Berkeley’s AMPLab. It excels in use cases like continuous applications that require streaming data to be processed, analyzed, and stored. Spark is also used for batch or streaming ETL and is very robust at scale, but using and practicing Spark requires an entirely different skill set above and beyond SQL.
At Qubole, we’ve made significant progress on our adoption of Spark on QDS with new features and scalability. To accommodate growing demands and leverage technological advancements made by the Apache Spark community, we at Qubole continue to release complimentary enhancements and optimizations pertaining to Apache Spark offered as a service on Qubole – the leading Big Data platform in the Cloud. Here are some of the highlights:
- Spark 3.0 support: The new updates on Spark 3.0 include Adaptive Query Execution, Dynamic Partition Pruning, and Disk-persisted RDD blocks served by shuffle service. There are also significant improvements in pandas API and up to 40X speedups in invoking R user-defined functions. Scala 2.12 is generally available, while Scala 2.11 has been removed from the latest version. In this blog, we take a deep dive into some of the supported functionality
- GitHub Integration for Spark Notebooks: With our GitHub integration, the power of collaboration and version control are integrated into Qubole’s Spark Notebooks. Once a Notebook is linked to a GitHub account and repository, data team members will be able to start saving their work on GitHub without leaving the Qubole Notebook interface. All queries, commands, and results for Spark, SparkSQL, Scala, and Python will be saved to the configured GitHub repository. For configuration and setup details, click here.
- Optimized Split Computation for SparkSQL: We’ve implemented optimization with regards to AWS S3 listings, which enables split computations to run significantly faster on SparkSQL queries. As a result, when there are a large number of partitions in Hive tables, we’ve recorded up to 6X and 81X improvements on query execution and AWS S3 listings, respectively. For more details, click here.
- Auto-scaling in Spark: In the open-source version of auto-scaling in Apache Spark, the required number of executors for completing a task is added in multiples of two. In Qubole, we’ve enhanced the auto-scaling feature to add the required number of executors based on configurable SLA. In addition, Qubole’s auto-scaler can add and remove nodes based on the resource requirements in the cluster. With Qubole’s auto-scaling, cluster utilization is matched precisely to the workloads, so there are no wasted compute resources, and it also leads to lowered TCO. Click here for more details.
- Heterogeneous Spark Clusters: Qubole supports heterogeneous Spark clusters for both on-demand and Spot instances. This means that the slave nodes in Spark clusters may be of any 40+ AWS instance types. For more details, click here.
Learn about the proven tuning technique for Apache Spark that lowers job costs on AWS while maximizing performance in this Data Lake on-demand session presented by Brad Caffey, Staff Data Engineer, Expedia Group.
Presto
Presto is an open-source SQL query engine built for running fast, large-scale analytics workloads distributed across multiple servers. It supports standard ANSI SQL and has enterprise-ready distributions made available by services such as Qubole, AWS Athena, GE Digital Predix, and HDInsight. This helps companies on other data warehouses like Redshift, Vertica, and Greenplum to move legacy workloads to Presto. Presto can plug in several storage systems such as HDFS, S3, and others. This layer of Presto has an API that allows users to author and use their storage options.
Our benchmarking results show that Presto on Qubole is 2.6x faster than ABC Presto in terms of overall Geomean of the 100 TPC-DS queries for the no-stats run. More importantly, 94 percent of queries were faster on Presto on Qubole, with 41 percent of the queries being more than 3x faster and another 23 percent of the queries being 2x-3x faster. Even when Hive metastore statistics are available, Presto on Qubole is 1.6x faster than ABC Presto in terms of overall Geomean of the 100 TPC-DS queries. For more details on Presto’s performance, click here.
Presto on Qubole also differentiates itself via value additions that handle Spot interruptions without sacrificing reliability.
There are a few recent changes implemented in Presto for better user experiences. Watch this on-demand session on ‘State and future of the Presto Project’ presented by David Phillips and Martin Traverso, Co-founders of Presto, to learn more.
Hive
Hive is a Big data warehouse framework that supports the analysis of large datasets stored in Hadoop’s HDFS and compatible file systems such as Amazon S3, Azure Blob, and Azure Data Lake Store File systems. Hive is full of unique tools that allow users to quickly and efficiently perform data queries and analysis. In order to make full use of all these tools, it’s important for users to use best practices for Hive implementation. If you’re wondering how to scale Apache Hive, here are ten ways to make the most of Hive performance.
Qubole provides a managed and cloud-optimized implementation of Hive on AWS, Azure, and GCP. Hive in Qubole Data Service improves overall query performance in cloud storage I/O by eliminating the data copy steps required with open-source Hive. Hive in QDS comes with specialized performance optimizations for Amazon S3. This is accomplished by improving Hive’s split computation by optimizing Amazon S3 bulk listing APIs, and refined implementation on the open-source S3 read logic.
Read more on how to increase the scalability of HiveServer2 with Qubole
Data Lake – Use Cases
Qubole is useful at any scale because the technology operates on the notion of separating storage from computing, and furthermore having managed autoscaling for Apache Hadoop, Apache Spark, Presto, and TensorFlow. The software automates cloud infrastructure provisioning, which saves a ton of time from data teams getting bogged down in administrative tasks such as cluster configuration and workload monitoring.
- ETL: Build and schedule pipelines for recurring data transformations
- Data Science and Machine Learning: Explore, develop and test models at scale before putting them into production
- Interactive Analytics: Enable data teams and less technical users to analyze less structured or raw data that otherwise can’t fit in a data warehouse
- Data Visualization: Format and present analytics for business insight and intuitive dashboards.
Data Lake Access Control
Many enterprises attempt to secure data through encryption and perimeter control — but without a comprehensive, granular data-access control strategy. Such an approach is crucial because multiple employees with different authority levels, responsibilities, and competencies run different jobs on the platform. When hundreds or thousands of employees need access to data for many other uses, coarse-grained permissions that give users “all or nothing” access are no longer sufficient. Instead, you need a set of scalable, consistent, and fine-grained control capabilities that prevent unnecessary access to sensitive information at every stage of processing. This post outlines the general best practices for granular access controls and the security features that Qubole provides.
Data Lake Security
Once all the data is gathered in one place, data security becomes critical. It is recommended that data lake security be deployed and managed within the enterprise’s overall security infrastructure and controls. Broadly, there are five primary security domains relevant to a data lake deployment: Platform, Encryption, Network Level Security, Access Control, and Governance.
When securing a data lake in the cloud for the first time, security needs to:
- Understand the different parties in cloud security
- Expect a lot of noise from your security tools as well as the big data frameworks and solutions that your team needs to use
- Carefully establish privileges and policies on your data based on what you are trying to protect and from whom.
- Use big data analytics internally to inform and improve your organization’s security capabilities and decision-making.
Explore these considerations in detail here.
Learn more about the various aspects of governance, extending to accommodate the growing compliance and regulatory requirements, and suggested architectural approaches in this Data Lake Summit on-demand session titled – ‘Data Governance and Multi-tenancy – A Tech Perspective’ presented by Satish KS, VP – Engineering at ZeoTap.
Data Lake TCO Optimization Capabilities
Cloud data lakes provide significant cost advantages, agility, and scale from the get-go. Proof of Concepts (POCs) for data-driven initiatives starts easily and without any huge upfront bill. But over time, as project mature or ad hoc queries take longer or the model iteration cycle increases, the seemingly endless supply of underlying resources leads to wasteful expenditure on computing and resources.
However, in the cloud, rising costs are not necessarily bad; it means that the data team is efficiently using the platform to deliver business value. TCO optimization makes sure that wasteful spending is detected and eventually eliminated. The Cloud data lake platform can help enterprises keep a check on this wasteful spending to lower TCO. With Qubole, enterprises should be able to address all the key requirements for optimizing TCO. Read the four must-have TCO optimization capabilities.
Reducing cloud infrastructure costs is one of the significant benefits of using the Qubole platform — and another way to do it seamlessly is by incorporating Spot instances available in AWS into our cluster management technology. This blog covers a recent analysis of the Spot market and advancements in our product that reduce the odds of Spot instance losses in Qubole-managed clusters. The recommendations and changes covered in this post allow our customers to realize the benefits of cheaper Spot instance types with higher reliability.
Still, wondering how to optimize costs in a changing world? Watch this webinar on how to optimize cloud costs associated with Data Analytics and Machine Learning during the current business climate.


