Presto is an open-source distributed SQL query engine, developed by Facebook. Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses. Qubole started its Presto-as-a-Service program a few weeks ago to make it easily accessible with a single click for its users. A good subset of Big Data analytics involves interactive, exploratory queries which can be expressed in ANSI-SQL – and Presto targets this use-case. As a PaaS provider, we want to provide multiple options to our users so they may evaluate these and other tools like Pig and MR without a lot of effort and choose the tool that works best for them. We present Presto performance numbers in this post.
We compared Hive 0.11 and Presto 0.60 using a few TPC-H* queries. Hive used Qubole’s Hadoop which contains a number of cloud-related optimizations (How does Qubole improve S3 performance?). Typically, Qubole’s Hive/Hadoop runs much faster than other Hadoop in the cloud (A Performance Comparison of Qubole and Amazon’s Elastic MapReduce). This will bias the numbers somewhat. We’ve also plugged in Qubole’s Hadoop into Presto – but not all optimizations kick in yet for Presto (this is a WIP). Presto uses Hadoop’s FileSystem implementations to access data in S3 or HDFS.
The queries used here are modified forms of TPC-H queries 1,2,4,5,6. The queries were modified keeping Hive and Presto’s limitations in mind. We had to rewrite the queries to have a “good” join order since Presto doesn’t do join ordering at this point in time. The data was generated using TPC-H dbgen and was of scale 75GB. The data was transformed to RCFile format. We used 10 m1.xlarge nodes to run the queries in Amazon EC2. We also have data points where the data resides in HDFS instead of S3.
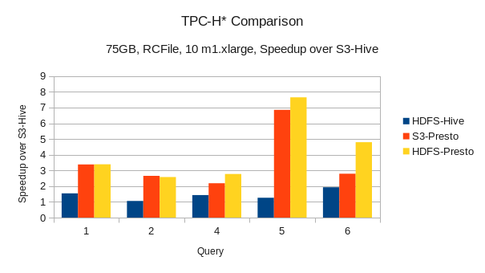
The numbers presented above are speedups over Hive where the data resides in S3. Presto showed a speedup of 2-7.5x over Hive for these queries. This is a pretty reasonable improvement for this class of queries. However, it was cumbersome to rewrite the queries with the right join order. A bad join order can slow down a query as the hash table is created on the bigger table or, when the bigger table does not fit in memory, cause out-of-memory exceptions. It also remains to be seen how both these systems will compare over ORC files. We think the next big push in performance will come via improvements in the optimizer to produce better query plans.
Presto provides an interesting middle ground between Hive and MPP databases in terms of performance and cost. We frequently see users use Hive for the heavy-duty crunching of 100s of TB to produce summary tables that are a fraction of the original size and load them into Redshift or other databases. User-facing reporting and viz tools connect to these databases. The downside of this approach is that this often involves a loading step into the database which can take a few hours. Hence the database contains data that is stale. Furthermore, MPP DBs tend to be more expensive. Presto is an interesting alternative to this as it can provide interactive performance over data that lives in S3 or HDFS, eliminating the additional load step and costs involved in running an MPP database.
As always, benchmarks hide as much as they reveal and the proof of the pudding is in the eating. Qubole encourages you to evaluate and determine the right tools for your use case. You can sign up for a free trial and run your own experiments!



