Data Lakes Explained
Data Lakes have become a core component for companies moving to modern data platforms as they scale their data operations and Machine Learning initiatives. Data lake infrastructures provide users and developers with self-service access to what was traditionally disparate or siloed information.
Today, with developments in cloud computing, companies and data teams can measure new projects according to the ROI and cost of an individual workload in order to determine if the project should be scaled out. The production-readiness and security of cloud computing are one of the largest breakthroughs for enterprises today. This model provides near-unlimited capabilities for companies’ analytics lifecycles:
Ingest – Data arrives in any raw format and is stored for future analysis or disaster recovery. Companies typically segment out several data lakes depending on privacy, production access, as well as the teams that will be leveraging the incoming information.

Store – Data lakes allow businesses to manage and organize nearly infinite amounts of information. Cloud object stores (AWS S3, Azure Blob, Google Cloud Storage, etc.) offer high availability access for big data computing, at an extremely low cost.

Process – With cloud computing, infrastructure is now simply an API call away. This is when data is taken from its raw state in the data lake and formatted to be used with other information. This data is also often aggregated, joined, or analyzed with advanced algorithms. Then the data is pushed back into the data lake for storage and further consumption by business intelligence or other applications.

Consume – When companies talk about having a self-service data lake, Consume is typically the stage in the life cycle they are referencing. At this point, data is made available to the business and customers for analytics as their needs require. Depending on the type of complex use cases, end-users may also indirectly or directly by using the data in the form of predictions (forecasting weather, financials, sports performance, etc) or perceptive analytics (recommendation engines, fraud detection, genome sequencing, etc).
On-Premise Data Lake vs Cloud Data Lakes
Data lakes are most commonly split into two general industry trends: on-premise data lakes and cloud-based data lakes.
In an on-prem data lake, companies must manage both the software and the hardware assets that house their data. If their data volumes grow beyond the capacity of the hardware they’ve purchased, then companies have no choice but to buy more computing power themselves.
In cloud data lakes, companies are able to pay for only the data storage and computing they need. This means they are able to scale up or down as their data requires. This scalability has been a huge breakthrough in Big Data’s adoption, driving the increased popularity of data lakes.
Data Lake Definition
By definition, a data lake is an operation for collecting and storing data in its original format, and in a system or repository that can handle various schemas and structures until the data is needed by later downstream processes.
The primary utility of a data lake is to have a single source for all data in a company — ranging from raw data, prepared data, and 3rd party data assets. Each of these is used to fuel various operations including data transformations, reporting, interactive analytics, and machine learning. Managing an effective production data lake also requires organization, governance, and servicing of the data.
Data Lake Architecture
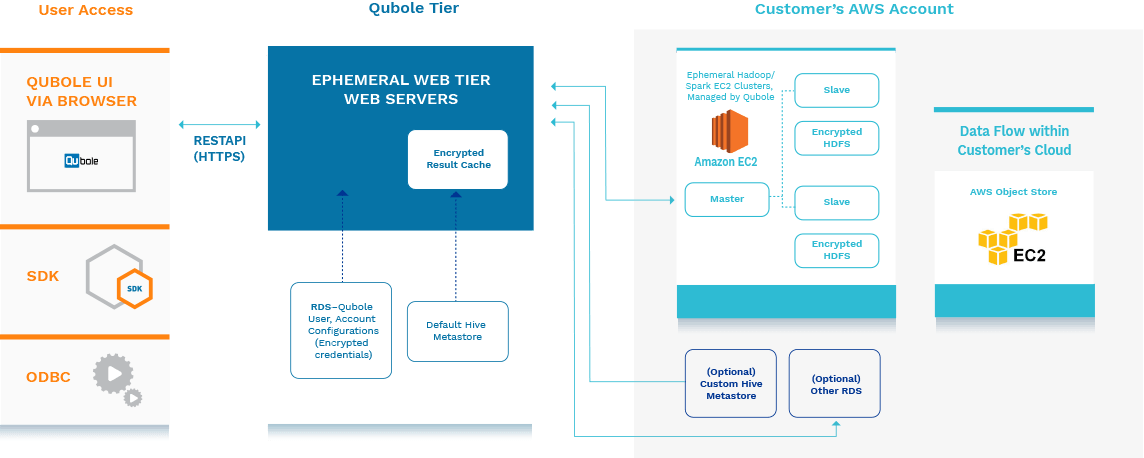
The cloud data lake is a centralized data store (typically referred to as object storage) that allows for highly scalable data storing capabilities, and high availability for quick access by cloud computing servers or other applications. Commonly a data lake is set up with layers of object stores: ones that are the source of truth for gathering all ingested files, raw data that can be used for DR (Disaster Recovery); and another that is optimized for analytics and other downstream processes.
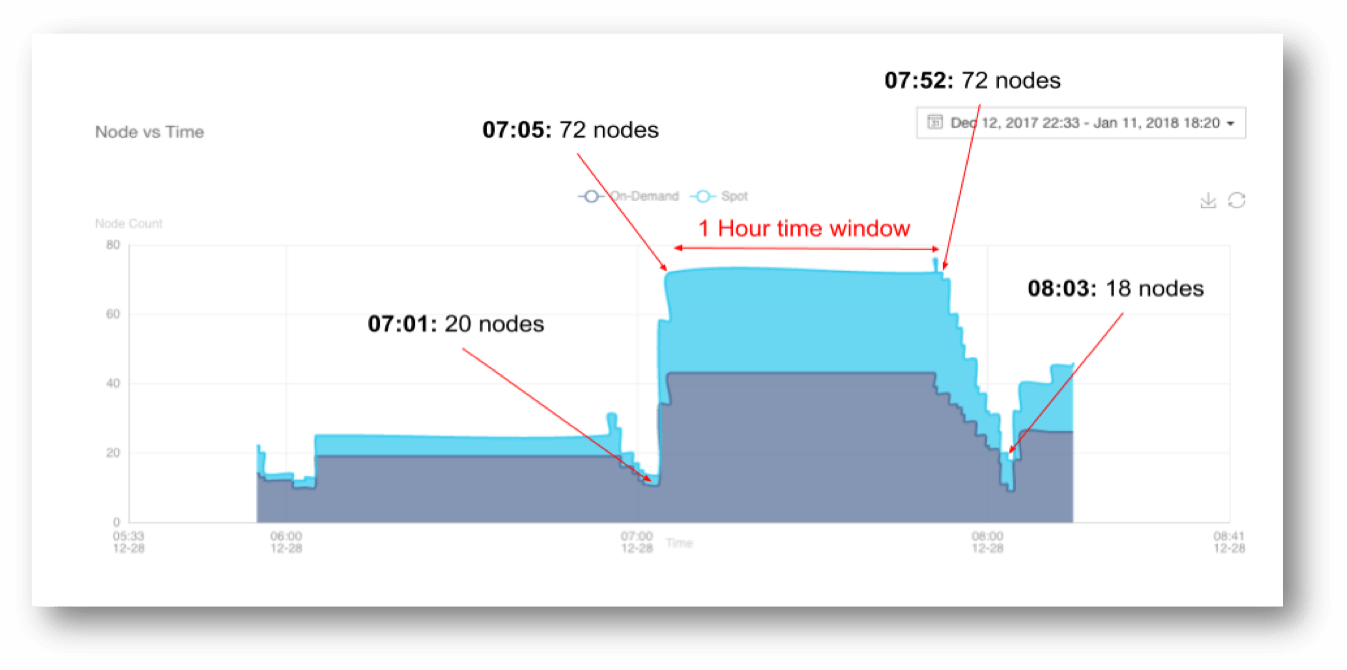
In order to fully realize the cost advantages of a cloud data lake, the big data workflow needs to be architected to take advantage of the separation of compute and storage. However, the challenge is having a system that can help different big data workloads autoscale according to the nature of their workloads (whether bursty or steady stream).
Qubole Specific Features

Multiple Storage options
- AWS S3 Object Store, Azure data lake and Blog, Google Cloud Storage
- Connect Data Warehouses and NoSQL databases (on-premise or in the cloud)

Autoscaling
- Automated cluster management for ease of administration and enabling self-service access to users through various interfaces.
- Managed autoscaling for Spark, Hadoop, and Presto workloads (from development to production)

Data Lake Monitoring and Data Lake Governance
- Performance and stability monitoring of pipelines and jobs.
- Alerting on production jobs to ensure consistent uptime
- Insights on how your teams are working with your data and tables to figure out where to optimize processes
- Recommendations to improve performance of existing workloads and table formats for analytics


