DATA SCIENCE
- Home >
- DATA LAKE SOLUTIONS >
- DATA SCIENCE
Data Science and Analysis are critical components for success for any company in today’s competitive environment. We empower Data Scientists and Analysts by providing them with the pioneering Autonomous Data Platform. This innovative platform liberates them, enabling them to concentrate on addressing the most pressing challenges posed by extensive datasets, without the frustration and wasted time often required by the day-to-day management of the underlying platform.
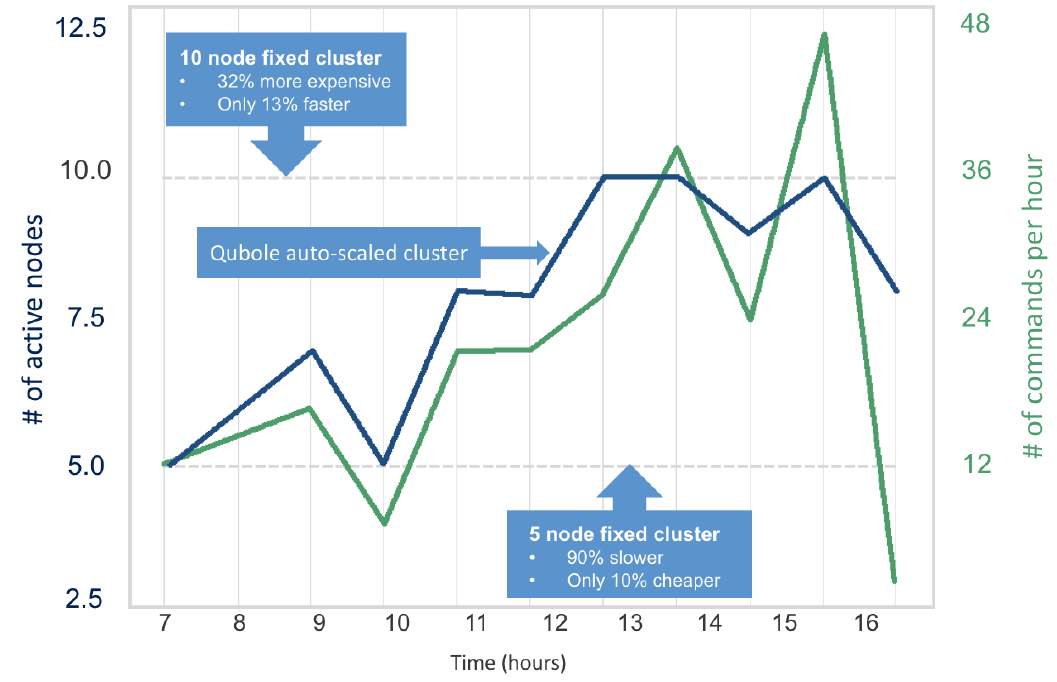
Through Qubole, the reliance of Data Analysts and Scientists on Data Administrators or Data Architects for the provisioning of computing clusters and resources becomes a thing of the past. Once the phase of exploratory data analysis and/or model development is completed, Data Scientists can seamlessly transition to productizing their notebooks using the notebook API, a process facilitated by just a few effortless clicks.
Data Analysis
Create an architecture that encompasses all forms of analytical data for any type of analysis with seamless accessibility and shareability by all those with a need for it. Leverage Qubole’s Data Fabric for data democratization, data integration, and data governance bolstered by Advanced Analytics and Data Science, enabling insights cost-effectively.
Spark Batch Processing
Data Scientists are transitioning to distributed engines to develop Machine Learning models and achieve a data-driven approach.
However, when moving to enterprise data science on a distributed Spark architecture, data scientists find it challenging to manage package dependencies for multiple dialects like Python & R, which increases time to market and can lead to abandoning the distributed framework.
Spark offers a frictionless experience with easy access to cluster computing resources through multiple interfaces and the flexibility to choose Scala, Java, Python, or R.


