This blog post is part one of an upcoming series about the unique benefits provided by Qubole when leveraging Spot instances.
AWS Spot Instance
Reducing cloud infrastructure costs is one of the significant benefits of using the Qubole platform — and one of the primary ways we do this is by seamlessly incorporating Spot instances available in AWS into our cluster management technology. This blog post covers a recent analysis of the Spot market and advancements in our product that reduce the odds of Spot instance losses in Qubole-managed clusters. The recommendations and changes covered in this post allow our customers to realize the benefits of cheaper Spot instance types with higher reliability.
One of the ways Qubole reduces cloud infrastructure costs is by efficiently utilizing cheaper hardware — like Spot instances provided by AWS — that are significantly cheaper than their on-demand counterparts (by almost 70 percent).
However, Spot instances can be lost with only two minutes of notice and can cause workloads to fail. One of the ways we increase the reliability of workloads is by handling Spot losses gracefully. For example, Qubole clusters can replicate data across Spot and regular instances, handle Spot loss notifications to stop task scheduling, and copy data out and retry queries affected by Spot losses. In spite of this, it is always best to avoid Spot losses in the first place.
Also Read: How to exploit AWS Spot Instance Termination Notifications in Qubole
Due to recent changes in the AWS Spot marketplace, the probability of a Spot loss is no longer dependent on the bid price. As a result, earlier techniques of using the bid price to reduce Spot losses have been rendered ineffective — and new strategies are required. This blog post describes the following new strategies:
- Reducing Spot request timeout
- Using multiple instance families for worker nodes
- Leveraging past Spot loss data to alter cluster composition dynamically
While the first two are recommendations for users, the last is a recent product enhancement in Qubole.
AWS Timeout
Qubole issues asynchronous Spot requests to AWS that are configured with a Request Timeout. This is the maximum time Qubole waits for the Spot request to return successfully. We analyzed close to 50 million Spot instances launched via Qubole as part of our customers’ workloads and we recommend users set Request Timeout to the minimum time possible (one minute right now) due to the following reasons:
Spot Nodes
The longer it takes to acquire Spot nodes, the higher the chances of such nodes being lost:
The following graph plots the probability of a Spot instance being lost versus the time taken to acquire it. The probability is the lifetime probability of the instance being lost (as opposed to being terminated normally by Qubole, usually due to downscaling or termination of clusters).
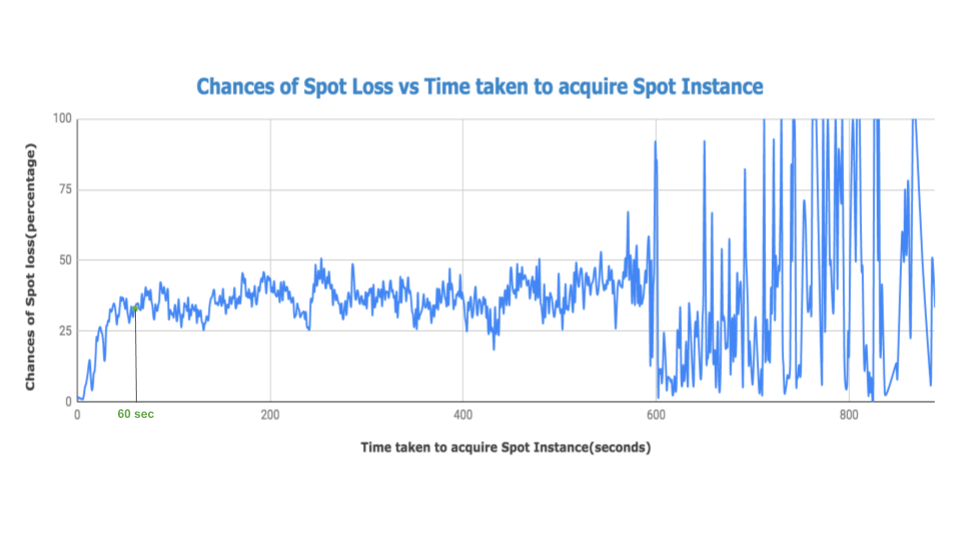
- In greater detail: 1.6 percent of nodes were abruptly terminated due to AWS Spot interruptions if they were acquired within one minute, whereas close to 35 percent of nodes were abruptly terminated if they were acquired in more than 10 minutes. We can also conclude that after 600 seconds, Spot loss is unpredictable and very irregular.
Most of the Spot nodes are acquired within a minute:
The graph below represents the percentage of Spot requests fulfilled versus the time taken (or the time after which the Spot request timed out).
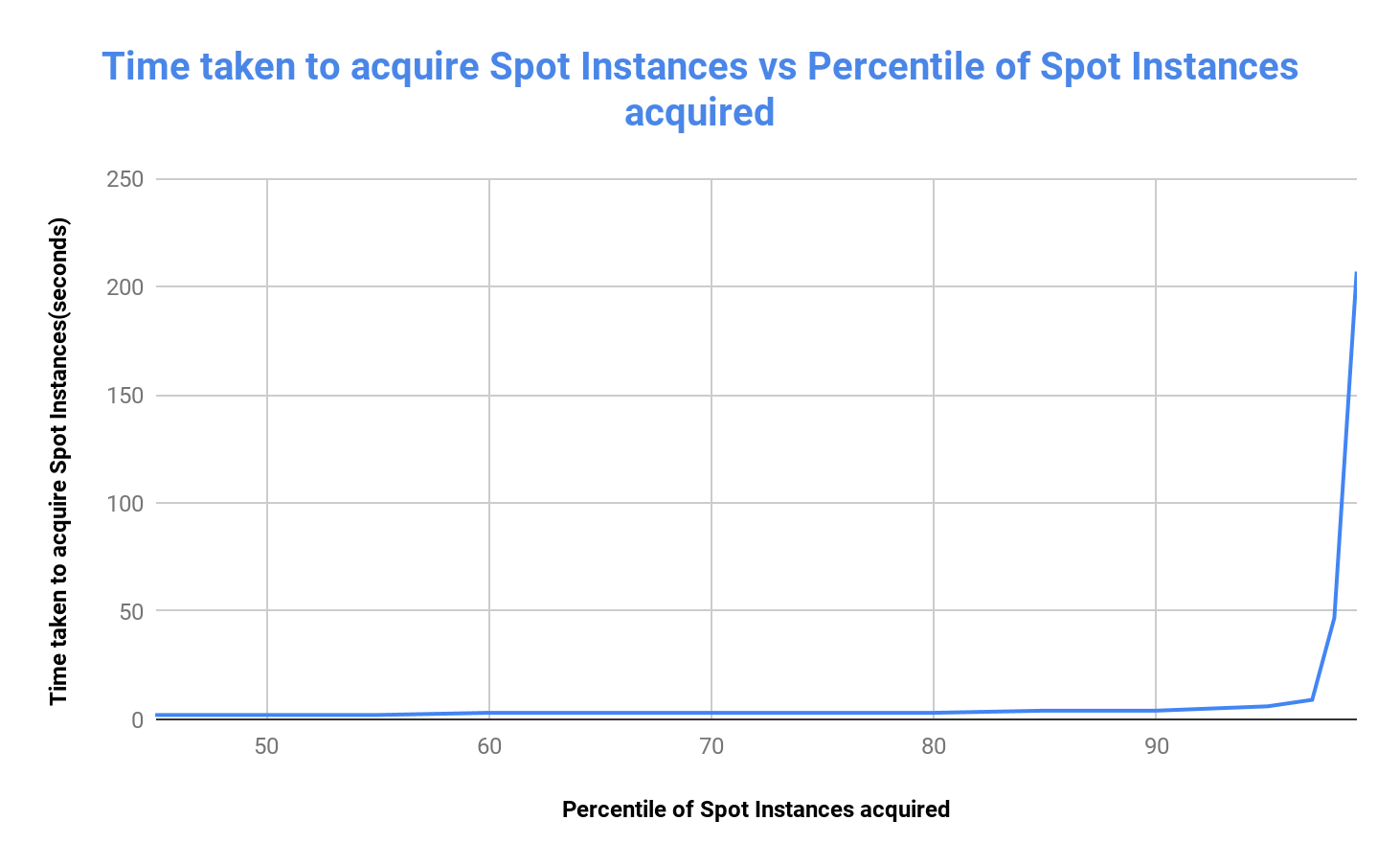
The above graph shows that 90 percent of Spot nodes were acquired within four seconds and 98 percent of Spot nodes were acquired within 47 seconds. This indicates that the vast majority of Spot nodes are acquired in very little time.
Currently, Qubole supports a minimum ‘Spot Request Timeout’ of one minute. Because almost all successful Spot requests are satisfied within one minute and the average probability of losing instances acquired in this time period is very small, selecting this option will increase reliability without significantly affecting costs. We will be adding the ability to set the Spot Request Timeout at a granularity level of seconds in the future.
Worker Nodes
Qubole strongly recommends configuring multiple instance types for worker nodes (also commonly referred to as Heterogeneous Clusters) for the following reasons:
- One reason is, of course, to maximize the Spot fulfillment rate and be able to use the cheapest Spot instances. This factor becomes even more important given the discussion in the previous section, as lowering Spot Request Timeouts too much could result in a lower Spot fulfillment rate in some cases.
- However, increasingly Qubole will be adding mechanisms to mitigate Spot losses that are dependent on the configuration of multiple worker node types. A good example is a mechanism to mitigate Spot losses which will be discussed in the next section.
The screenshot below shows how one can configure multiple instance types for worker nodes via cluster configuration:
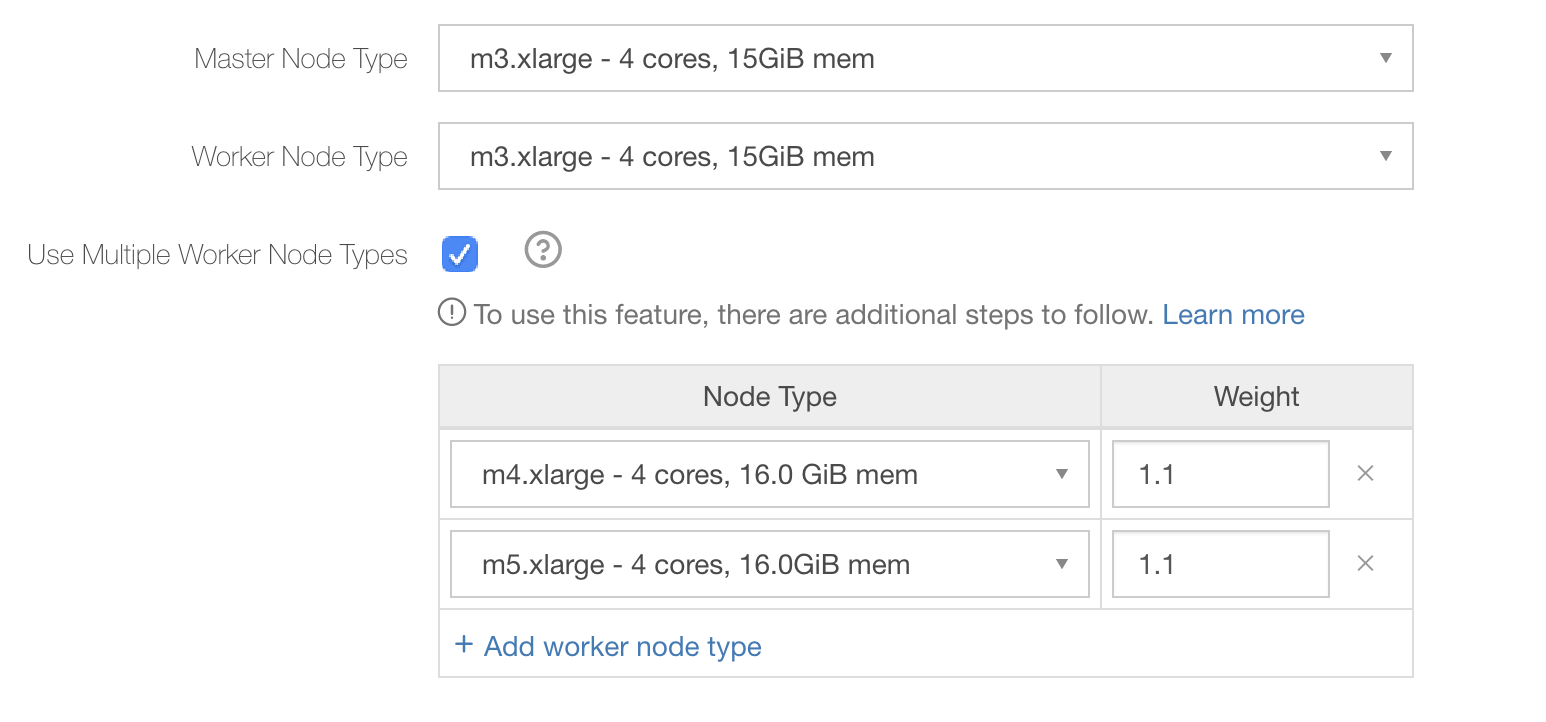
Qubole recommends using different instance families when selecting the multiple worker node types options, i.e. using m4.xlarge and m5.xlarge instead of m4.xlarge and m4.2xlarge. While Qubole is functional with either combination, data from AWS (see https://aws.amazon.com/ec2/spot/instance-advisor/) suggests that instance availability within a family is correlated, and it is best to diversify across families to maximize Spot availability. Of course, as many instance types and families as desired can be configured.
AWS has added a lot of different instance families of late with similar CPU/memory configurations, and we would suggest using a multitude of these. For example:
- M3
- M4
- M5
- M5a
- M5d
These are different instance families with similar computing resources and can be combined easily. In a recent analysis, we found that AMD-based instance types (5a family) were very close to Intel-based instances (5 family) in price and performance, and were good choices to pair up in heterogeneous clusters.
Spot Loss
Qubole mitigates Spot loss and reduces the autoscaling wait time for YARN-based clusters (Hadoop/Hive/Spark). Whenever a node is lost due to Spot loss, YARN captures this information at the cluster level. We can leverage this information to optimize our requests for Spot instances. We apply the below optimizations while placing Spot instance requests:
- If there is a Spot loss in a specified time window (by default in the last 15 minutes), the corresponding instance family is classified as Unstable.
- Subsequently, when there are Spot provisioning requests:
- Instance types belonging to unstable instance families are removed from the list of worker node types.
- If the remaining list of worker node types is not empty, then Qubole issues asynchronous AWS Fleet Spot requests for this remaining list of instance types and waits for the configured Spot Request Timeout.
- If the remaining list of worker node types is empty, then Qubole issues a synchronous Fleet Spot API request for the original worker node types (i.e. without filtering for unstable instance families). Synchronous requests return instantly and the Spot Request Timeout is not applicable.
- If the capacity is still not fulfilled, Qubole would fall back to on-demand nodes if it is configured (this behavior is unchanged). However, the extra on-demand nodes launched as a result of fallback would be replaced with Spot nodes during rebalancing.
The protocol above ensures that Qubole either does not get unstable instance types that are likely to be lost soon or that we only get them if the odds of the Spot loss have gone down (because data from prior analysis tells us that instance types provisioned by synchronous Fleet Spot API requests have low Spot loss probability). Soon we will be extending this enhancement to Presto clusters as well.
This feature is not enabled by default yet. Please contact Qubole Support to enable this in your account or cluster.
Spot Instance with Qubole
Spot instances are significantly cheaper than on-demand instances but are not that reliable. AWS can take them away at will with very short notice. So, we need to be smart while using them and aim to reduce the impact of Spot losses. Relatively easy configuration changes and improvements can help us utilize these cheaper instances more efficiently and save us a lot of money. This post is just scratching the surface of things we are doing here at Qubole for Spot loss mitigation. Expect more such updates from us in the near future.



