Data Lake Essentials, Part 2 – File Formats, Compression, and Security
In this multi-part series, we will take you through the architecture of a Data Lake. We can explore data lake architecture across three dimensions
- Part I – Storage and Data Processing
- Introduction
- Physical Storage
- Data Processing ETL/ELT
- Part II – File Formats, Compression, and Security
- File Formats and Data Compression
- Design Security
- Part III – Data Catalog and Data Mining
- Data Catalog, Metadata, and Search
- Access and Mine the Lake
In this edition, we look at file formats, compression, and security
Data Lake Storage – File Formats and Data Compression
The two primary operations in the Big data ecosystem are “READ” and “WRITE”; let’s compare all the formats for these two operations.
Factors to consider while choosing a storage format for WRITE:
- The data format of the application must be compatible with the querying format
- Observe for schemas that may change over time(eg., clickstream/event data format generally changes)
- Files size and the frequency of writing; for eg., if you dump each clickstream event, then the file size is very small and you must merge them for better performance.
- Desired speed.
Factors to consider while choosing a storage format for READ:
- Types of queries – if queries need to retrieve a few or a group of column users then either Parquet or ORC can be used, which are very good for reading with the penalty that is paid for WRITE. In simple words, if applications are read-heavy, one can use Parquet/ORC.
- Snappy and LZO have commonly used compression technologies that enable efficient block storage and processing. It’s best to choose an efficient combination of support; such as parquet with Snappy compression that works best in Spark.
People from a traditional RDBMS background are often surprised at the extraordinary amount of control that data lake architects have over how datasets can be stored. Data Lake Architects, as opposed to Relational Database Administrators, get to determine an array of elements such as file sizes, type of storage (row vs. columnar), degrees of compression, indexing, schemas, and block sizes. These are related to the big data-oriented ecosystem of formats commonly used for storing and accessing information in a data lake.
Default Block Size
Files smaller than the Hadoop File System (HDFS) default block size — which is 128 MB — are considered small. Using small files, given the large data volumes generally found in data lakes, results in a very large number of files. Every file is represented as an object in the cluster name node memory, each individual file occupies 150 bytes, as a rule of thumb. So 100 million files, each using a block, would use multiple gigabytes of memory. The takeaway here is that Hadoop ecosystem tools are not optimized for efficiently accessing small files. They are primarily designed for large files, typically an even multiplier of the block size.
In the case of object storage (s3, blob, etc.), engines like Spark and Presto don’t perform well with smaller files because of many internal API calls.
ORC Columnar File Format
ORC is a prominent columnar file format designed for Hadoop workloads. The ability to read, decompress, and process only the values that are required for the current query is made possible by columnar file formatting. While there are multiple columnar formats available, many large Hadoop users have adopted ORC. For instance, Facebook uses ORC to save tens of petabytes in their data warehouse. They have also demonstrated that ORC is significantly faster than RC File or Parquet. Yahoo also uses ORC to store its production data and has likewise released some of its benchmark results.
Apache Parquet
Another columnar file format has been getting a lot of traction in the community. It is mainly used for nested data structures or scenarios where few columns require projection.
Formatting Data Sets
It is quite possible that one type of storage structure and file format is optimized for a particular workload but not quite suitable for another. In situations like these, given the low cost of storage, it is suitable to create multiple copies of the same data set with different underlying storage structures (partitions, folders) and file formats (e.g. ORC vs Parquet)
Data Lake Security
Once all the data is gathered in one place, data security becomes critical. It is recommended that data lake security is deployed and managed from within the framework of the enterprise’s overall security infrastructure and controls. Broadly, there are five primary domains of security that are relevant to a data lake deployment: Platform, Encryption, Network Level Security, Access Control, and Governance.
Platform
This provides the components to store data, execute jobs, tools to manage the system and the repositories, etc. Security for each type or even each component varies from one to another.
- Storage level security – e.g. IAM role or Access/Secret Keys for AWS S3, Posix like ACLs for HDFS
- NoSQL repository – as an alternative or to complement the stored content; Namespaces and accounts access (like in traditional Relational Databases) are used in protecting these data stores.
- Metadata level security – e.g. Hive SQL auth, Ranger, Kerberos, etc.
Data Encryption
Enterprise-level organizations typically require encryption for stored data. If not universally, then at least for most of the classifications of data other than what’s publicly available. All leading cloud providers support encryption on their primary objects store technologies (such as AWS S3) either by default or as an option. Additionally, the technologies used for other storage layers such as derivative data stores for consumption, also offer encryption.
Encryption key management is also an important consideration, with requirements typically dictated by the enterprise’s overall security controls. Options include keys created and managed by the cloud provider, customer-generated keys managed by the cloud provider, and keys fully created and managed by the customer on their premise.
The final related consideration is encryption in transit. This covers data moving over the network between devices and services. In most situations, this is easily configured with either built-in options for each service, or by using standard TLS/SSL with associated certificates.
Network Level Security
Another important layer of security resides at the network level. Cloud-native constructs such as security groups, as well as traditional methods such as network ACLs and CIDR block restrictions, all, play a part in implementing a robust “defense-in-depth” strategy, by walling off large swaths of inappropriate access paths at the network level. This implementation should also be consistent with an enterprise’s overall security framework.
Access Control
Enterprises usually have standard authentication and user directory technologies such as Active Directory in place. Every leading cloud provider supports methods for mapping the corporate identity infrastructure onto the permissions infrastructure of the cloud provider’s resources and services. While the plumbing involved can be complex, the roles associated with the access management infrastructure of the cloud provider (such as IAM on AWS) are assumable by authenticated users, enabling fine-grained permissions control over authorized operations. The same is usually true for third-party products that run in the cloud such as reporting and BI tools. LDAP and/or Active Directory are typically supported for authentication, and the tools’ internal authorization and roles can be correlated with and driven by the authenticated users’ identities.
Governance
Typically, data governance refers to the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. It relies on both business policies and technical practices. Similar to other described aspects of any cloud deployment, data governance for an enterprise data lake needs to be driven by and consistent with overarching practices and policies for the organization at large.
In traditional data warehouse infrastructure, control over database content is typically aligned with business data and separated into silos by business units or system functions. However, in order to derive the benefits of centralizing an organization’s data, a centralized view of data governance is required.
Even if an Enterprise is not fully mature in its data governance practices, it is critical to enforce at least a minimum set of controls such that data cannot enter the lake without the meta-data (“data about the data”) being defined and captured. While this partly depends on the technical implementation of metadata infrastructure as described in the earlier “Physical Storage” section, data governance also means that business processes determine the key metadata that is required. Similarly, data quality requirements related to concepts such as completeness, accuracy, consistency, and standardization are in essence business policy decisions that must first be made, before baking the results of those decisions into the technical systems and processes that actually carry out these requirements.
Data Lake Cost Control
Apart from data security, another aspect of governance is Cost Control. Financial governance in big data deployments is a top-of-mind priority for every CEO and CFO around the world. Big data platforms have a bursty and unpredictable nature that tends to exacerbate the inefficiencies of an on-premises data center infrastructure. Many companies who perform a lift and shift of their infrastructure to the cloud face the same challenges in realizing their big data promise because replicating the existing setup prevents you from leveraging cloud-native functionalities.
Data privacy laws are fast becoming a primary element in any data security conversation: from the EU’s GDPR to California’s CCPA to Japan’s Act on the Protection of Personal Information, the ability to protect consumer data is top of mind. For companies that are built around consumer data, consumer trust becomes a vital part of their business model.
Qubole’s Data Lake capabilities
- Qubole supports all the major open-source formats like JSON, XML, Parquet, ORC, Avro, CSV, etc. Supporting a wide variety of file formats adds flexibility to tackle a variety of use cases.
- Hadoop/Hive – ORC Metadata caching support improves performance by reducing the time spent reading metadata.
- Apache Spark – Parquet Metadata caching which improves performance by reducing the time spent on reading Parquet headers and footers from an object store.
- Qubole keeps its distribution up-to-date with respect to file format optimizations available in open source, allowing customers to take advantage of recent open-source developments.
- Encryption for data at rest and data in transit in collaboration with your public cloud and network connectivity providers.
- Security through Identity and Access Management, Qubole provides each account with granular access control over resources such as clusters, notebooks, and users/groups including:
- Accessing through API Tokens
- Accessing QDS through OAuth and SAML
- Google Authentication
- Active Directory integration
- Authenticating Direct Connections to Engines
- Using Apache Ranger for Hive, Spark SQL, and Presto
- SQL Authorization through Ranger in Presto
- Using Role-based Access Control for Commands
- Using the Data Preview Role to Restrict Access to Data
- Security Compliance based on industry standards: Qubole deploys baselines in its production environments that are compliant with SOC2, HIPAA, and ISO-27001.
- Role-Based Access Control support for all resources including clusters, workbench, notebooks, and also commands. Users can set commands to be private to prevent others from viewing their commands, or public to support collaboration. Command access settings can be changed before, during, or after execution.
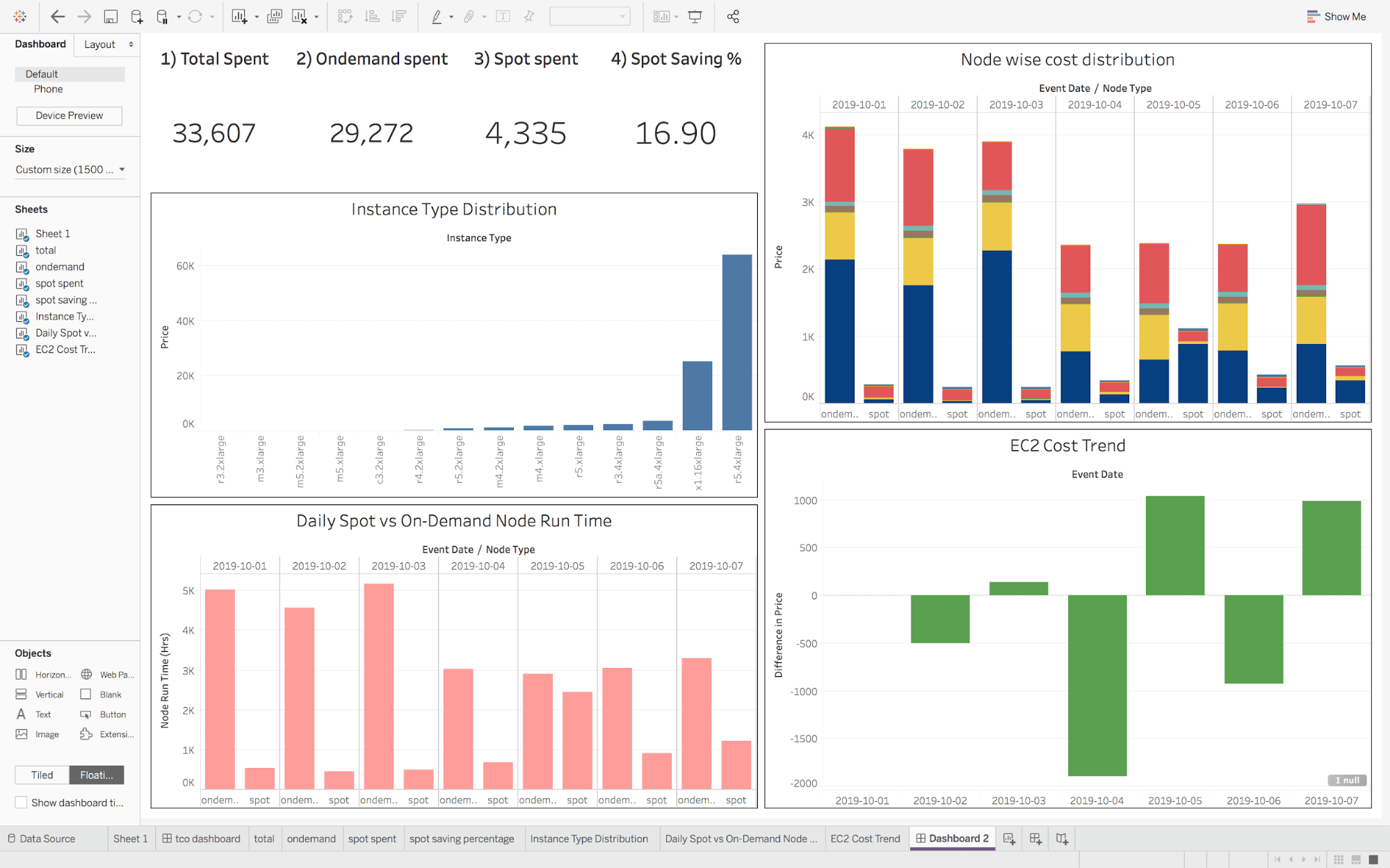
- Dashboards for cost flow across different business verticals within the organization.
- Qubole is GDPR and CCPA compliant and supports Hive ACID transactions to meet right-to-be-forgotten requirements.
Missed Part 1? Data Lake Essentials, Part 1 – Storage And Data Processing
Continue Reading: Data Lake Essentials, Part 3 – Data Catalog and Data Mining
Some References
- https://docs.qubole.com/en/latest/admin-guide/hive-administration/configure-hive-server2.html
- https://docs.qubole.com/en/latest/security-guide/index.html
- https://docs.qubole.com/en/latest/rest-api/qubole-endpoints.html#qubole-endpoints
- https://docs.qubole.com/en/latest/security-guide/data-security.html
- https://docs.qubole.com/en/latest/security-guide/data-management.html
- https://docs.qubole.com/en/latest/security-guide/infra-security.html
- https://www.qubole.com/product/data-platform/big-data-financial-governance/
- https://www.qubole.com/products/trust/general-data-protection-regulation-gdpr/
- https://www.qubole.com/blog/qubole-gdpr-ready/
- https://www.qubole.com/blog/qubole-open-sources-multi-engine-support-for-updates-and-deletes-in-data-lakes/



