Data Engineering
- Home >
- DATA LAKE SOLUTIONS >
- Data Engineering
Bottlenecks in data preparation and ingestion are a frustrating part of creating a scalable data architecture and pipelines.
Leverage Qubole automation to meet demand and easily explore, build, and deliver data pipelines using your data processing framework of choice.
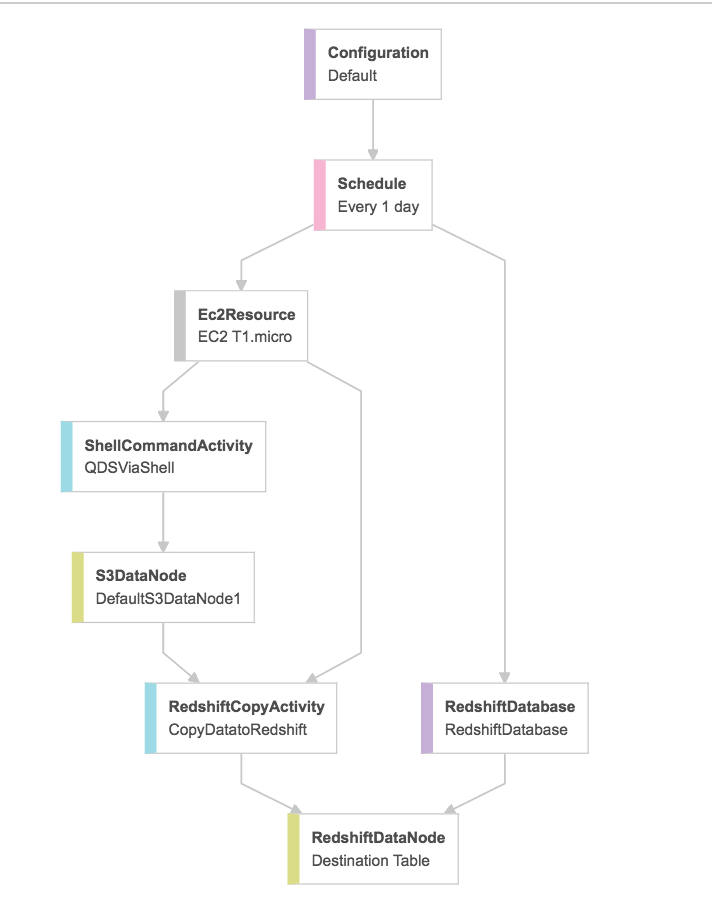
Data Pipelines
Qubole supports multiple engines and notebooks, providing a choice for data engineering teams to build pipelines using SQL, Python, Scala, Spark, Hive, and streaming data services.
Users can create, schedule and manage workloads with Continuous Data Engineering services, using Zeppelin or Jupyter notebooks. Qubole offers integrations with Talend, Big Query, AWS Data Lake Formation, and APIs/SDKs to integrate other processes with data.
Avoid bottlenecks in data preparation and ingestion by using Qubole to easily explore, build and deliver data pipelines, and meet your big data engineering requirements.
Data Lake Architecture
To gain a competitive edge from data, businesses need more than just a good BI tool. From interactive analytics to deep learning, Qubole’s cloud data lake platform offers an optimal architecture for complex requirements.
With a simple, open, and secure platform, Qubole addresses diverse use cases, data formats, and clouds, providing flexibility in a rapidly growing environment.
This empowers engineers to focus on data processing, minimizing DevOps support for cluster operations. Qubole’s user interface also offers a great Sandbox for Hive queries and Spark jobs, making it easy to implement and use.
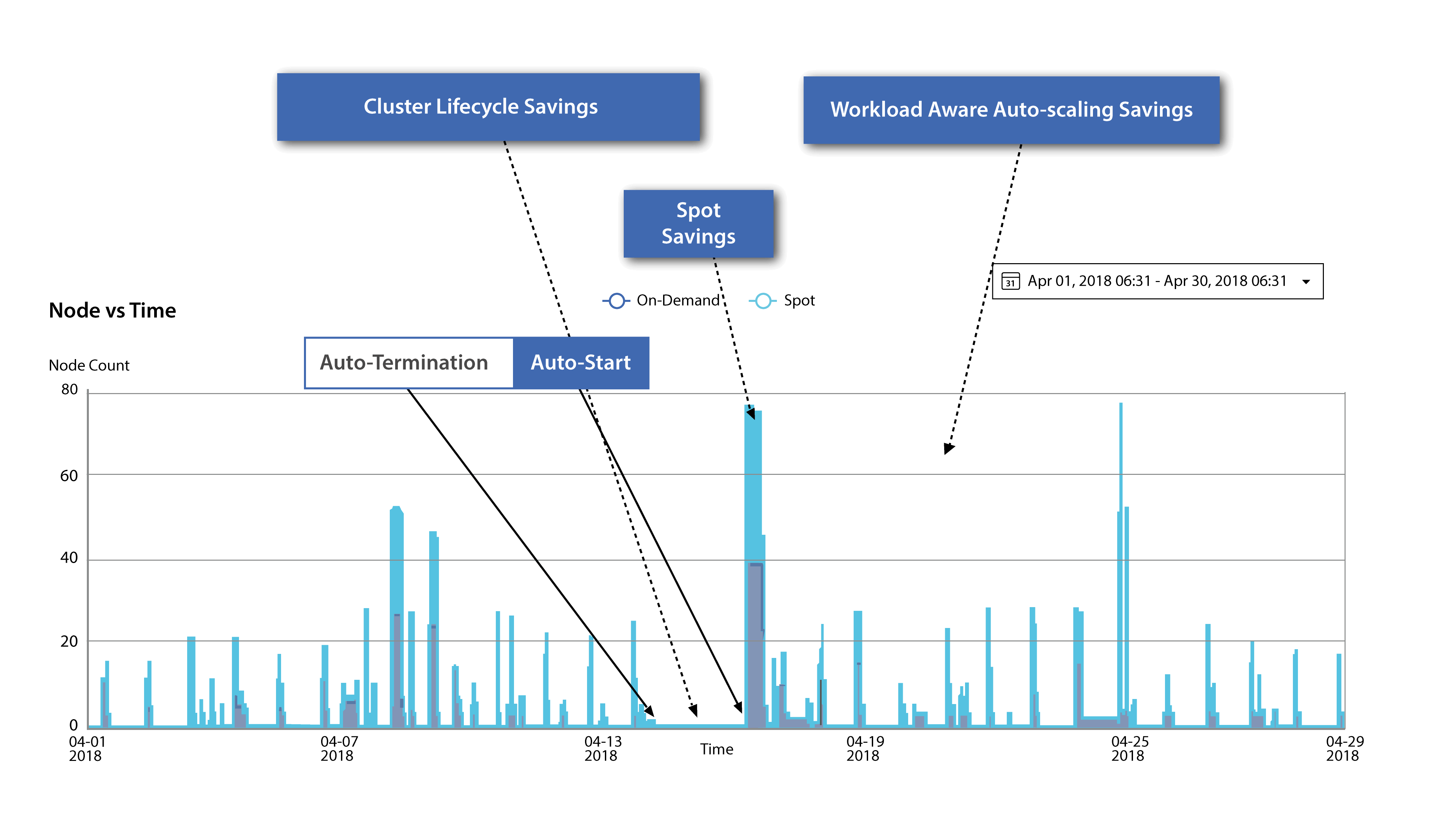
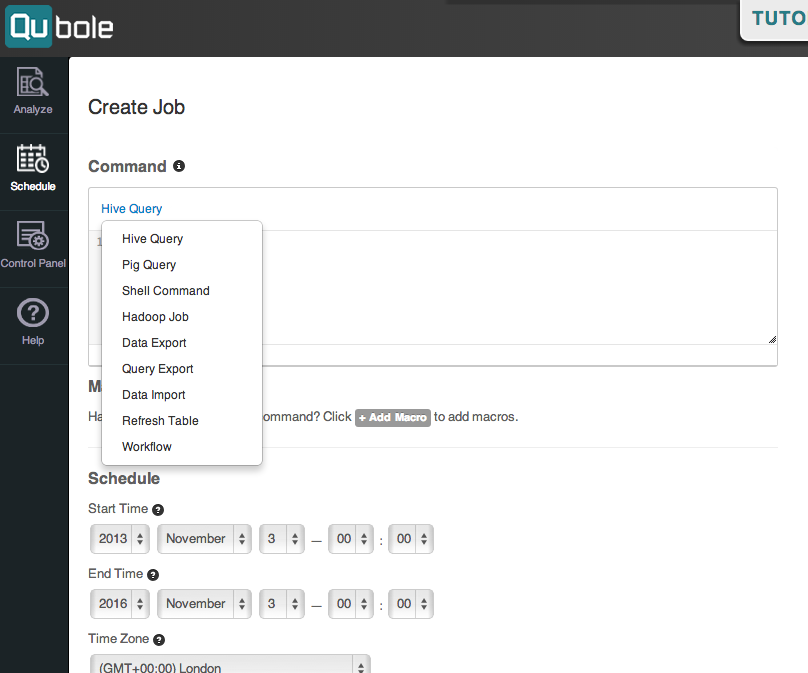
Airflow Workflows
Want to create dynamic, extensible, and scalable data pipelines, while leveraging Qubole’s fully managed and automated cluster lifecycle management? With Airflow, you can programmatically author, schedule, and monitor workflows, visualizing dependencies, progress, logs, code, tasks, and success status.
It provides insights into execution time and task completion patterns. Notably, Airflow excels in representing Directed Acyclic Graphs (DAGs) of tasks using Python scripts, enabling data engineers to easily handle complex workflows and perform transformations on intermediate data sets using Python utilities.


