DATA LAKE ARCHITECTURE
When done right, data lake architecture on the cloud provides a future-proof data management paradigm, breaks down data silos, and facilitates multiple analytics workloads at any scale and at a very low cost. Key considerations to get data lake architecture right include:
Data Ingestion Architecture
An Open Data Lake ingests data from sources such as applications, databases, real-time streams, and data warehouses. It stores the data in its raw form or an open data format that is platform-independent.
The ingest capability supports real-time stream processing and batch data ingestion; ensures zero data loss and writes exactly once or at least once; handles schema variability; writes in the most optimized data format into the right partitions and provides the ability to re-ingest data when needed.
The data is stored in a central repository that is capable of scaling cost-effectively without fixed capacity limits; is highly durable; is available in its raw form and provides independence from fixed schema; and is then transformed into open data formats such as ORC and Parquet that are reusable, provide high compression ratios and are optimized for data consumption.
Big Data Lake Architecture
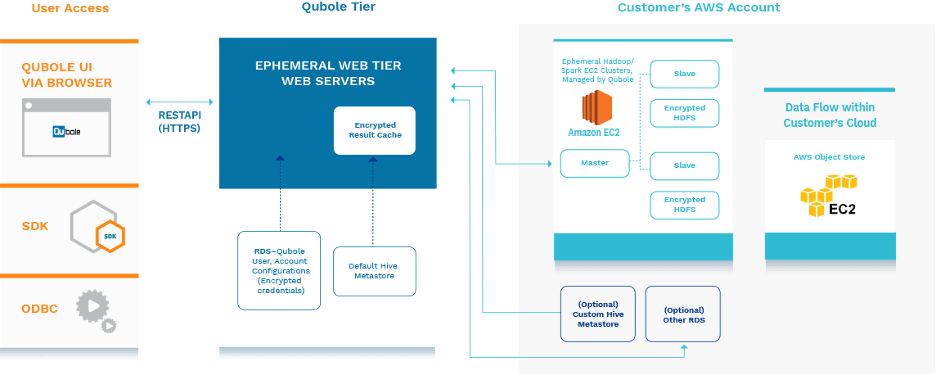
Open Data Lake
An Open Data Lake supports concurrent, high-throughput writes and reads using open standards. Data is transformed to create use-case-driven trusted datasets
Ingested data is frequently reconciled to reflect continuous business operations. Concurrent data writes and reads need to be supported with the desired levels of transaction guarantees that are dictated by the use case and the data.
Data is cleaned, classified, denormalized, and prepared for a variety of use cases using continuously running data engineering pipelines. Data lakes that run into petabyte-scale footprints need massively scalable data pipelines that also provide sophisticated orchestration capabilities. Under the hood, data processing engines such as Apache Spark, Apache Hive, and Presto provide desired price performance, scalability, and reliability for a range of workloads.
An Open Data Lake enables different use cases such as ad hoc analytics, data discovery, business intelligence reports, and machine learning. Different types of data access and tooling are supported. Data access can be through SQL or programmatic languages such as Python, Scala, R, etc.
Data Lake Catalog
It can be hard to find data in the lake. Without a data catalog, users can end up spending the majority of their time just trying to discover and profile datasets for integrity before they can trust them for their use case. A data catalog crawls and classifies datasets, documents them, and supports a search interface to aid discovery.
Data Lake Analytics
For business intelligence reports, SQL is the lingua franca and runs on aggregated datasets in the data warehouse and also the data lake. Ad hoc analytics uses both SQL and non-SQL and typically runs on raw and aggregated datasets in the lake as the warehouse may not contain all the data or due to limited non-SQL access. Third-party SQL clients and BI tools are supported using a high-performance connectivity suite of ODBC, JDBC drivers, and connectors. Machine learning users need a variety of tooling and programmatic access through single node-local Python kernels for development; Scala and R with standard libraries for numerical computation and model training such as TensorFlow, Scikit-Learn, MXNet; ability to serialize and deploy, monitor containerized models.
Data Lake Governance
When multiple teams start accessing data, there is a need to exercise oversight for cost control, security, and compliance purposes.
Data Lake Cost
The cost of big data projects can spiral out of control. This is exacerbated by the lack of native cost controls and lifecycle policies in the cloud. Fine-grained cost attribution and reports at the user, cluster, job, and account levels are necessary to cost-efficiently scale users and usage on the data lake.
Data Lake Security
Data in the lake should be encrypted at rest and in transit. Cloud providers provide services to do this using keys either managed by the cloud provider or keys fully created and managed by the customer.
An Open Data Lake integrates with non-proprietary security tools such as Apache Ranger to enforce fine-grained data access control to enforce the principle of least privilege while democratizing data access
Perimeter security for the data lake includes network security and access control. Cloud providers support methods to map the corporate identity infrastructure onto the permissions infrastructure of the cloud provider’s resources and services. LDAP and/or Active Directory are typically supported for authentication
Data Lake Compliance
Expanded data privacy regulations, such as GDPR and CCPA, have created new requirements around the “Right to Erasure” and “Right to Be Forgotten”. An Open Data Lake not only supports the ability to delete specific subsets of data without disrupting data consumption but offers easy-to-use non-proprietary ways to do so.
Cloud Agnostic Architecture
An Open Data Lake provides a platform runtime with automation on top of cloud primitives such as programmatic access to instance types, and low-cost compute (Spot on AWS, Low priority VMs on Azure, Preemptible VMs on GCP). This frees up organizations to focus on building data applications.
Whether the data lake is deployed on the cloud or on-premise, each cloud provider has a specific implementation to provision, configure, monitor, and manage the data lake as well as the resources it needs.
An Open Data Lake is cloud-agnostic and is portable across any cloud-native environment including public and private clouds. This enables administrators to leverage the benefits of both public and private clouds from an economics, security, governance, and agility perspective.
Data Lake Components












| Data Lake Architecture components | Qubole capabilities |
|---|---|
| Data ingestion and storage | Pipelines for stream based data ingestion, Spark structured streaming |
| Data processing and continuous data engineering | Qubole ACID for concurrent writes & reads Airflow, Scheduler to orchestrate data pipeline Spark, Hive, Presto data processing engines |
| Data access and consumption | Native applications - Jupyter notebooks, Workbench Connectivity - REST APIs & SDK, Drivers |
| Data governance - Discoverability, Security and Compliance | Qubole cost explorer for financial governanc Ranger for data access contro Qubole ACID for data updates, deletes |
| Infrastructure and operations | Automated cluster lifecycle management Workload aware auto-scaling Intelligent spot management |


