AD HOC ANALYTICS
SQL ON DATA LAKE
- Home >
- Platform >
- Open Data Lake Platform >
- Ad hoc Analytics
Higher productivity, faster time to value and scale to support a larger number of concurrent users.




| Challenges of Data Analytics | Data Lake Solution |
|---|---|
| Balance accessibility and performance tradeoffs for growing set of users | |
| Face infrastructure, data management, data ingestion delays to provide valuable insights on specific issues | Have a self service access scalable ad-hoc analytics solution with automated data pipelines |
| Build data pipelines manually every time to do proof of concept for new types of regular reports |
AD HOC Analysis
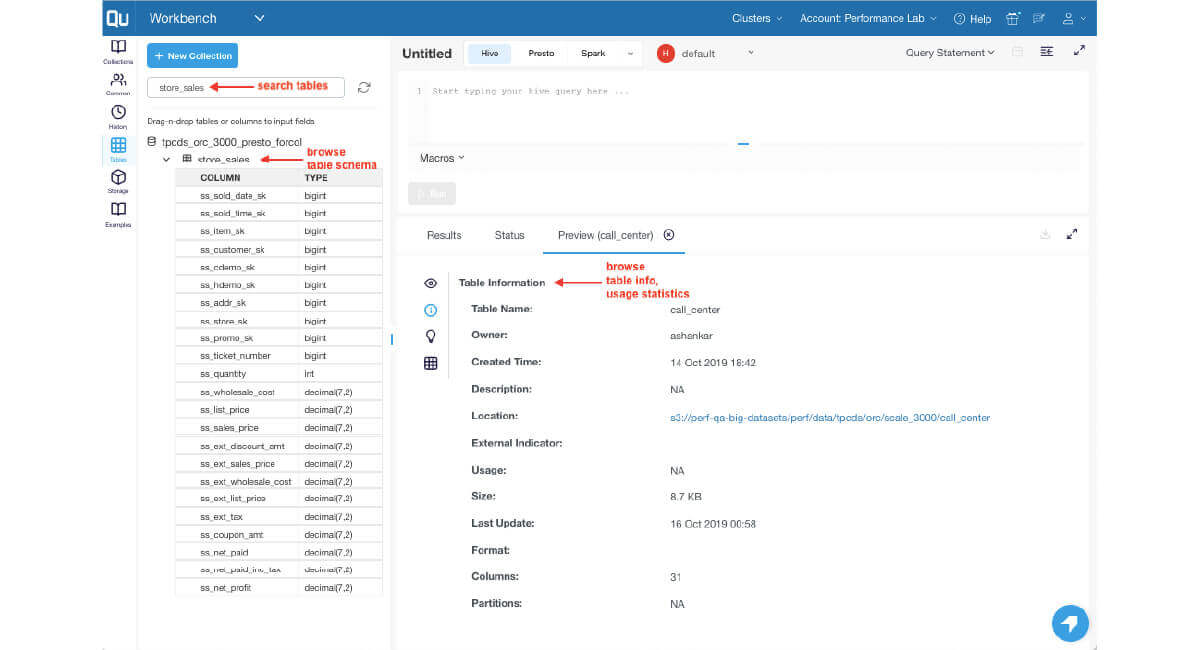
- Get started with easy-to-use SQL interfaces that work the way analysts want
- Discover insights, query data, analyze results, and debug queries from a single pane of glass Qubole Workbench.
- Leverage built-in connectors or JDBC and ODBC drivers with popular BI tools like Looker and Tableau to visualize the data
- Ingest data into the platform with popular tools like Talend, Informatica, Ascend.io
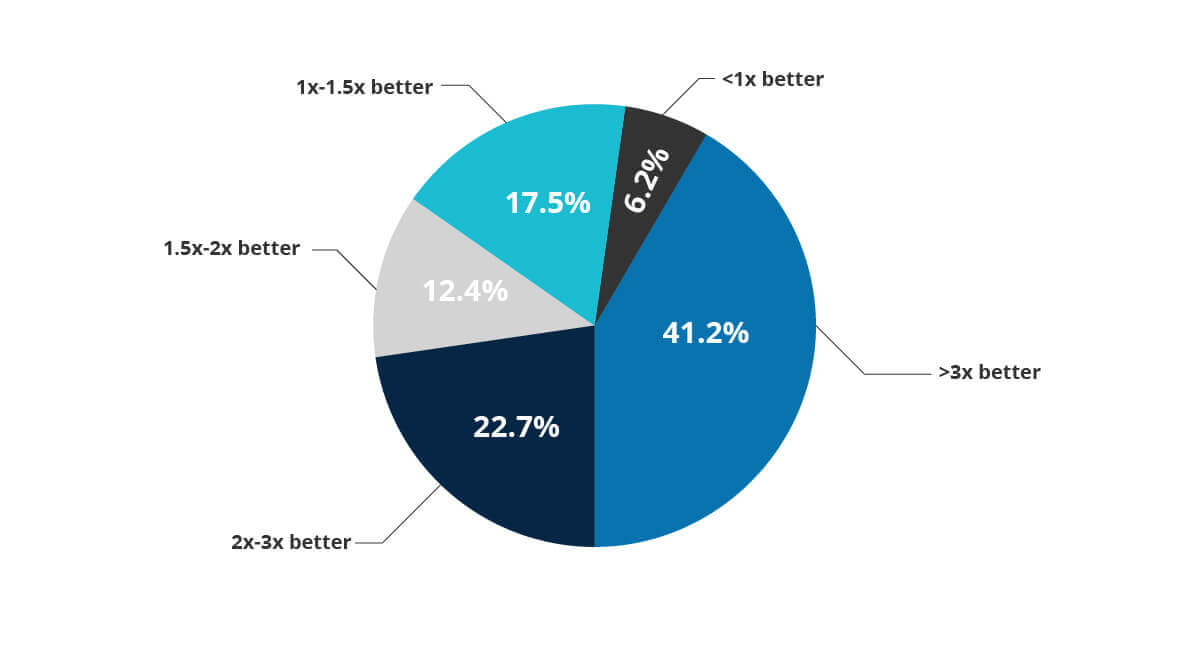
Scalability With Data and Queries
- Maintain price-performance balance for complex queries due to the query or the data or both
- Improve workload performance by implementing a data layout strategy such as columnar data formats, statistics collections
- Power ad-hoc or batch queries on large datasets with cloud-optimized open-source frameworks Presto, Hive, SparkSQL
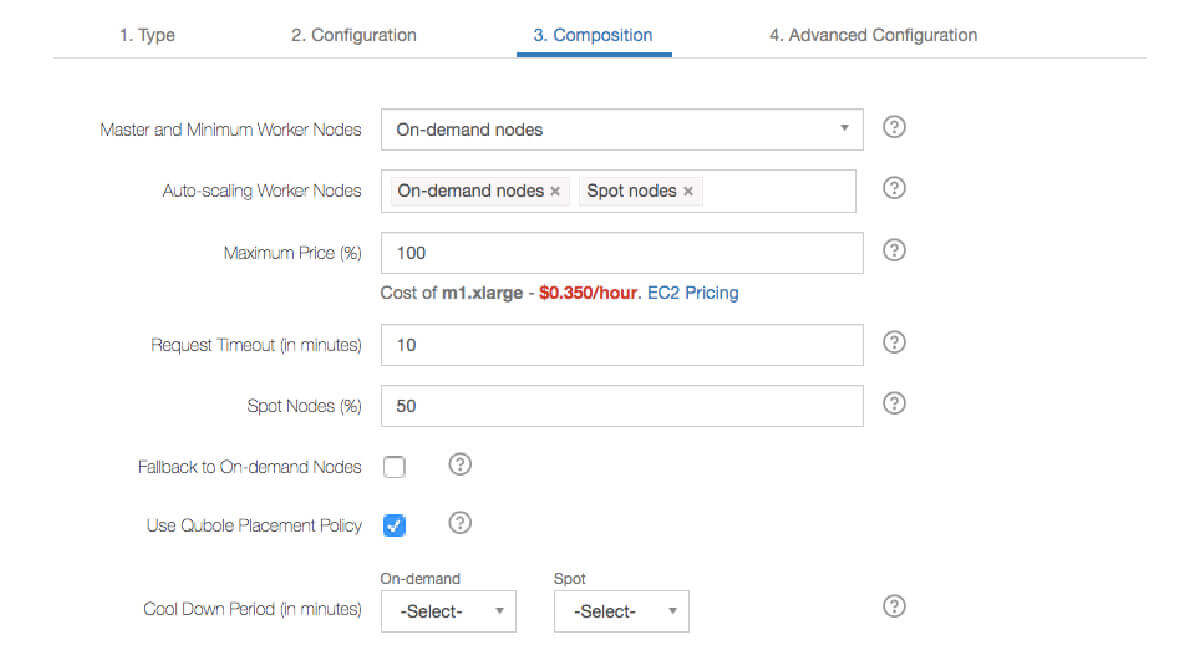
AD HOC Solution Support 1000s of Concurrent Users
- Handle burstiness of ad-hoc queries from multiple end-users without operational complexity
- Minimize costs automatically while supporting concurrent user growth without a performance impact
- Have near-zero management overhead regardless of inbound query flow
- Scale up or down automatically to support all workloads at any point in time
Ecosystem Partners