MACHINE LEARNING MODELS
- Home >
- Platform >
- Open Data Lake Platform >
- MACHINE LEARNING MODELS
BUILD AND DEPLOY MACHINE LEARNING MODELS AT ENTERPRISE SCALE
Innovate, differentiate, and modernize with data science and machine learning.




| Top Common Challenges | Solution |
|---|---|
| Setting up interfaces manually to collaborate with peers and connect to data sources and infrastructure | Provides choice to use preferred interface such as Rstudio, Python or Jupyter while providing a common workspace where everyone on the data team can collaborate |
| Coordinating specific dependencies between OS, programming language, and the libraries to build models. | Solves code portability problem by keeping dependencies intact from one environment to another and also does version control |
| Inefficient ad-hoc collaborative methods via emails or slack | Allows continuous collaboration and governed searches of the code, data, and metadata of peers |
| Deployment of enterprise-wide machine learning solutions requires the applications to rapidly scale to accommodate variability in the usage or data | Scales up compute capacity to meet demand and scales down when the usage drops automatically while optimizing the cost based on workload SLA and performance requirements. |
Build Machine Learning Models
Data Scientists can build, deploy and iterate on their models faster with
- Experiment Tracking
- Out-of-box Integrations for front-end tools: RStudio, H2O.ai, Datarobot
- End-to-End Workflows anchored by schedulers and Airflow
- Managed Notebooks – Serverless (Offline) Editing
Increase Developer Productivity
Developers can now skip steps and build applications with
- Code auto-complete
- Code compare
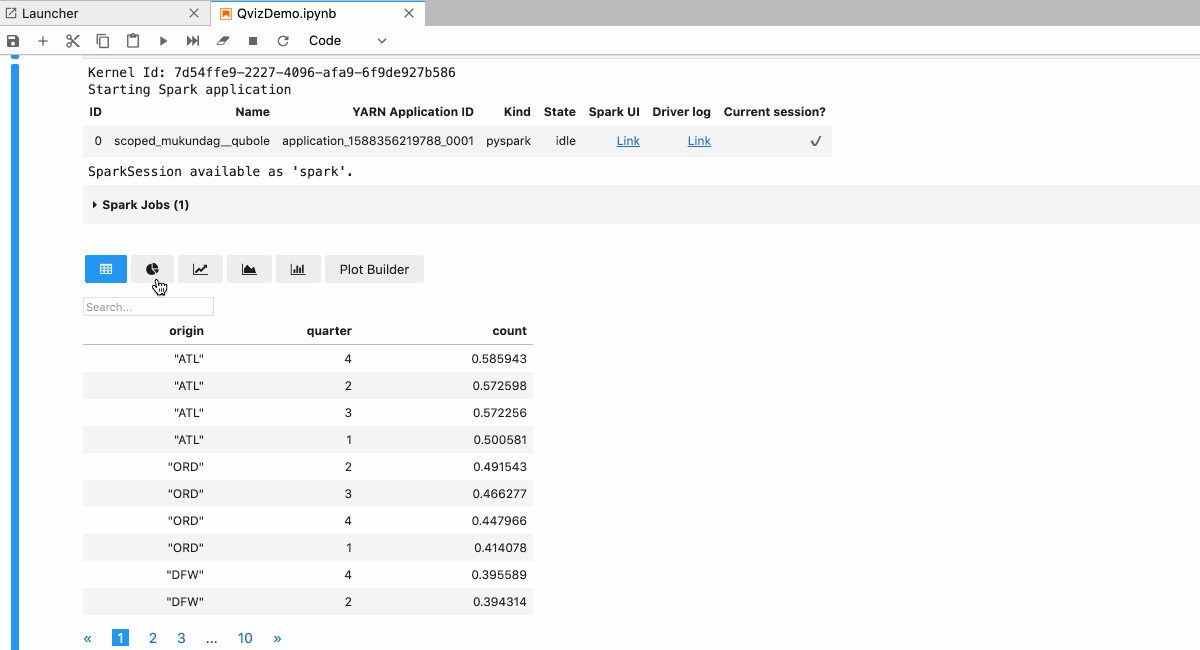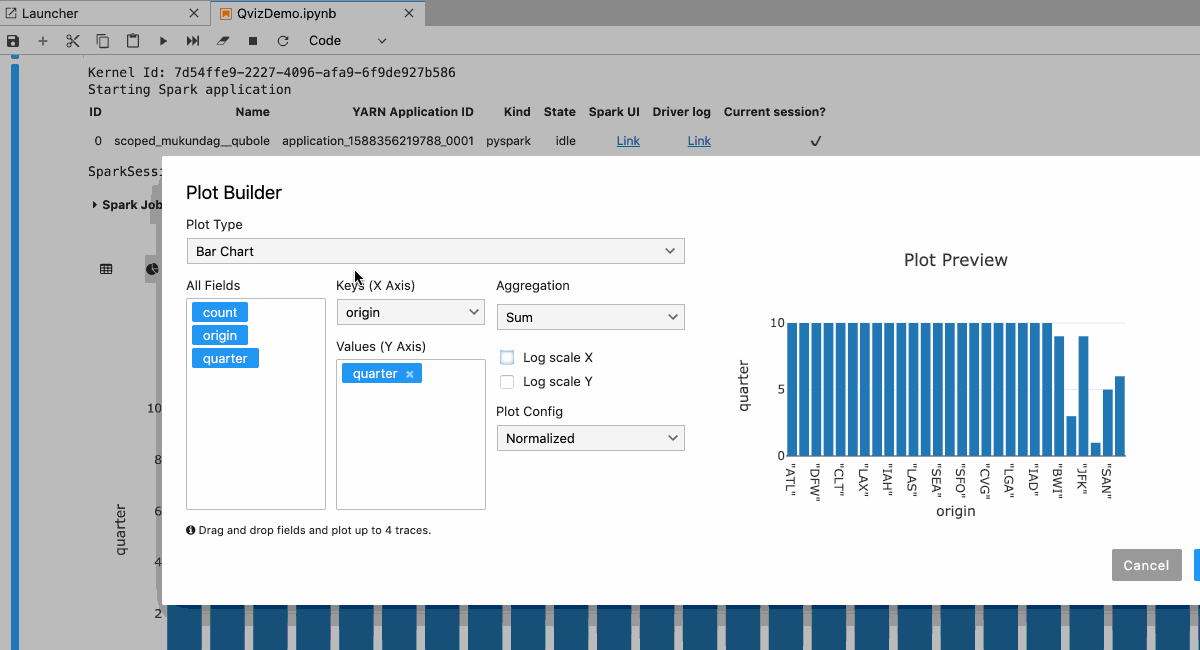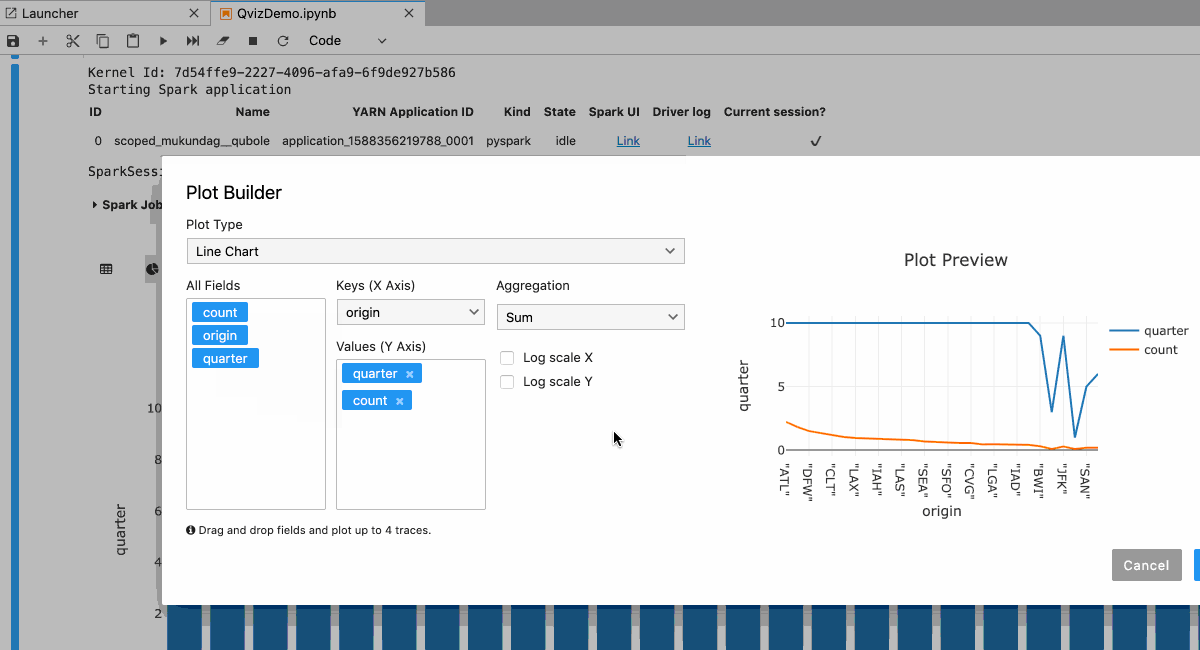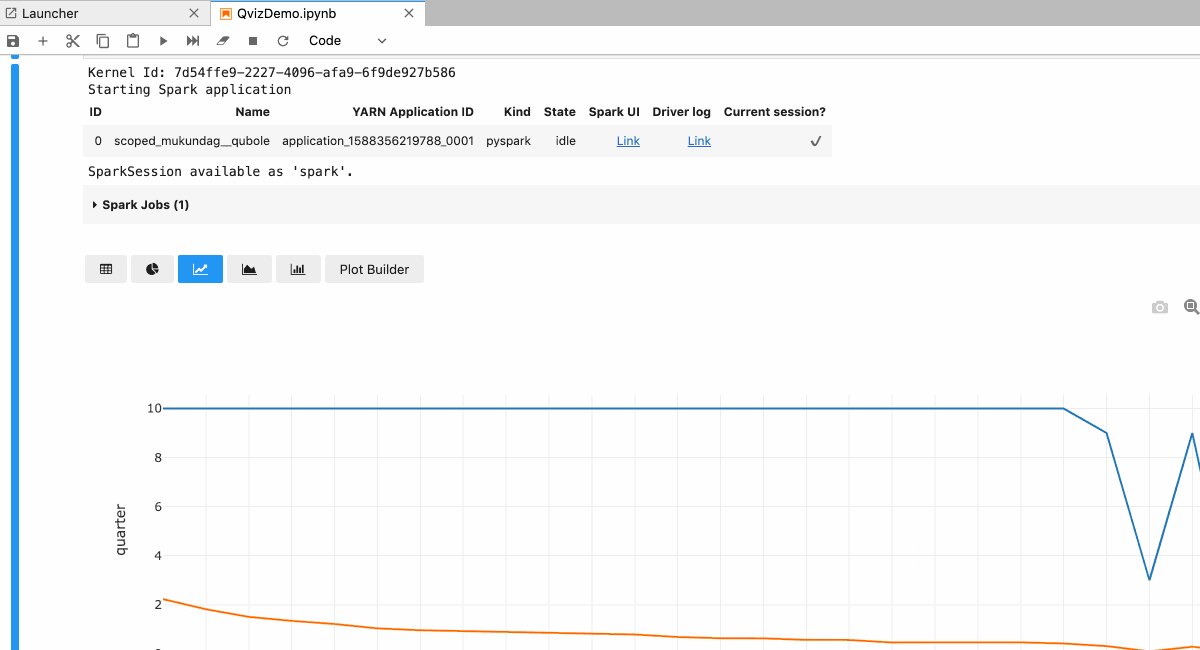
- Code-free visualizations (QVIZ)
- Version control
- Hands-free dependency management
- Easy access to cloud storage and data catalog
Infrastructure Provisioning
- Minimize costs automatically while supporting concurrent user growth without a performance impact
- Have near-zero management overhead regardless of the number of users or model versions
- Scale up or down automatically to support all workloads at any point in time
Ecosystem Partners






