Apache Spark
When it comes to big data tools, Apache Spark is gaining a rock star status in the big data world these days, and major big data players are among its biggest fans. If the predictions of industry experts are to be believed, Apache Spark is revolutionizing big data analytics. So if you’re in the dark as to what Apache Spark is and what it does, here’s a guide to shed some light on this powerful Big data tool.
What is Apache Spark?
Spark is a scalable, open-source big data processing engine designed for fast and flexible analysis of large datasets (big data). Developed in 2009 at UC Berkeley’s AMPLab, Spark was open-sourced in March 2010 and submitted to the Apache Software Foundation in 2013, where it quickly became a top-level project.
Until Spark came along, machine learning was not practically scalable and took too long. Spark accommodates multiple languages. Two of the most significant benefits of Spark are its scalability and speed of processing. Spark supports multiple languages such as Scala, PySpark, R, and SQL. It provides many configuration parameters that allow you to optimize the Spark Application.
Spark consists of a single driver and multiple executors. Spark can be configured to have a single executor or as many as you need to process the application. Spark supports autoscaling, and you can configure a minimum and a maximum number of executors.
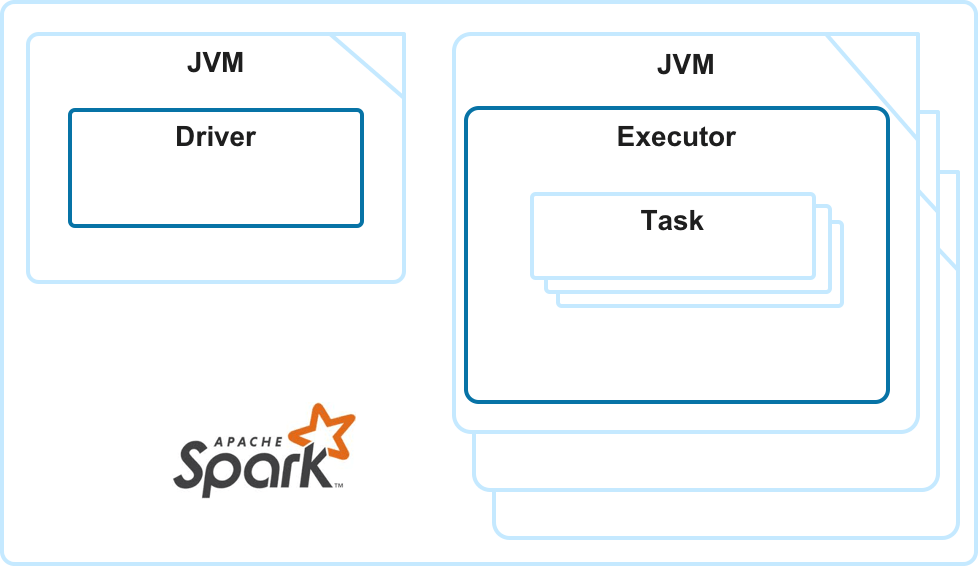
Click here to learn some of the best practices for optimizing Spark in the Qubole environment.
Apache Spark Components
Spark Core
The general execution engine of the Spark platform, Spark Core contains various components for functions such as task scheduling, memory management, fault recovery, etc. Spark’s API that defines Resilient Distributed Datasets (RDDs) also resides in Spark Core. Thanks to RDDs—Spark can draw on Hadoop clusters for stored data and process that data in memory at unprecedented speeds, allowing data to be explored interactively in real-time.
Spark SQL
Big data consists of structured and unstructured data, each of which is queried differently. Spark SQL provides an SQL interface to Spark that allows developers to co-mingle SQL queries of structured data with the programmatic manipulations of unstructured data supported by RDDs, all within a single application. This ability to combine SQL with complex analytics makes Spark SQL a powerful open-source tool for the data warehouse.
GraphX
Also found in Spark’s integrated framework is GraphX, a library of common graph algorithms and operators for manipulating graphs and performing graph-parallel computations. Extending the Spark RDD and API, GraphX allows users to create directed graphs with arbitrary properties attached to each vertex and edge. GraphX is best used for analytics on static graphs, such as Facebook’s Friend Graph, that uncover social network connection patterns.
Apache Spark Benefits
Here are some advantages that Apache Spark offers:
- Ease of Use: Spark allows users to quickly write applications in Java, Scala, or Python and build parallel applications that take full advantage of Hadoop’s distributed environment.
- Is designed for fast distributed processing: Spark’s engine enables massive amounts of data to be processed quickly, in-memory, or with batch.
- Supports multiple languages: Spark allows users to code with SQL, Python, R, and Scala.
- Offers a robust data science ecosystem: Spark allows you to easily use custom or prebuilt packages for machine learning and advanced analytics use cases.
- Handles a wide variety of workloads: Spark enables you to use streaming for near-real-time data processing, batch processing, and running ad hoc queries across various data sources.
Apache Spark Streaming
Spark Streaming allows you to use Spark for stream processing. You write a streaming job the same way as you would write a Map job. At execution time, Spark breaks the input stream into a series of small jobs and runs them in batches. Inputs can come from sources such as HDFS, Kafka, Kinesis, Flume, and others. A typical output destination would be a file system, a database, or a dashboard.
Spark Streaming has gone alpha with Spark 0.7.0. It’s based on the idea of discretized streams or DStreams. Each DStream is represented as a sequence of RDDs, so it’s easy to use if you’re coming from low-level RDD-backed batch workloads. DStreams underwent a lot of improvements over that period of time, but there were still various challenges, primarily because it’s a very low-level API.
You can run Spark Streaming jobs on a Qubole Spark cluster either from the Analyze page or Notebooks page of QDS. For more information, see Composing Spark Commands in the Analyze Page and Running Spark Applications in Notebooks.

Apache Spark Structured Streaming
Spark Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing. You can express your streaming computation the same way you would express a batch computation on static data. You can use the Dataset or DataFrame API in Scala, Java, Python, or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The Spark SQL engine runs it incrementally, continuously, and updates the final result as streaming data continues to arrive. The computation is executed on the same optimized Spark SQL engine.
Spark Structured Streaming was introduced in Spark 2.0 (and became stable in 2.2) as an extension built on top of Spark SQL. Because of that, it takes advantage of Spark SQL code and memory optimizations. Structured Streaming also gives very powerful abstractions like Dataset or DataFrame APIs as well as SQL. You can run Spark Structured Streaming jobs on a Qubole Spark cluster from the Workbench and Notebooks pages as with any other Spark application. You can also run Spark Structured Streaming jobs by using the API. For more information, see Submit a Spark Command.
Spark Streaming Vs Structured Streaming
Both Structured Streaming and Streaming with DStreams use micro-batching. The most significant difference in latency and message delivery guarantees: Structured Streaming offers exactly once delivery with 100+ milliseconds latency, whereas the Streaming with DStreams approach only guarantees at-least-once delivery but can provide millisecond latencies.
To see how to use Streaming with DStreams and Streaming with DataFrames (which is typically used with Spark Structured Streaming) for consuming and processing data from Apache Kafka. Click here.
Apache Spark Use Cases
Here’s a review of some of the top use cases for Apache Spark.
Streaming Data
Apache Spark’s key use case is its ability to process streaming data. With so much data being processed on a daily basis, it has become essential for companies to be able to stream and analyze it all in real-time. And Spark Streaming has the capability to handle this extra workload. Some experts even theorize that Spark could become the go-to platform for stream-computing applications, no matter the type. The reason for this claim is that Spark Streaming unifies disparate data processing capabilities, allowing developers to use a single framework to accommodate all their processing needs. To check out the general ways that Spark Streaming is being used by businesses today, click here.
Machine Learning
Another of the many Apache Spark use cases is its machine learning capabilities. Spark comes with an integrated framework for performing advanced analytics that helps users run repeated queries on sets of data—which essentially amounts to processing machine learning algorithms. Among the components found in this framework is Spark’s scalable Machine Learning Library (MLlib). The MLlib can work in areas such as clustering, classification, and dimensionality reduction, among many others. All this enables Spark to be used for some very common big data functions, like predictive intelligence, customer segmentation for marketing purposes, and sentiment analysis. Network security is also a good business case for Spark’s machine learning capabilities. Utilizing various components of the Spark stack, security providers can conduct real-time inspections of data packets for traces of malicious activity.
Interactive Analysis
Among Spark’s most notable features is its capability for interactive analytics. Apache Spark is fast enough to perform exploratory queries without sampling. By combining Spark with visualization tools, complex data sets can be processed and visualized interactively. Structured Streaming allows users the ability to perform interactive queries against live data. Combining live streaming with other types of data analysis, Structured Streaming provides a boost to Web analytics by allowing users to run interactive queries against a Web visitor’s current session.
Fog Computing
Fog computing brings new complexities to processing decentralized data, as it increasingly requires low latency, massively parallel processing of machine learning, and extremely complex graph analytics algorithms. Fortunately, with key stack components such as Spark Streaming, an interactive real-time query tool (Shark), a machine learning library (MLib), and a graph analysis engine (GraphX), Spark more than qualifies as a fog computing solution. In fact, as the IoT industry gradually and inevitably converges, many industry experts predict that—compared to other open-source platforms— Spark has the potential to emerge as the de facto fog infrastructure.
Hadoop Vs Spark
 There’s no question that Spark has ignited a firestorm of activity within the open-source community. So much so that organizations looking to adopt a big data strategy are now questioning which solution might be a better fit, Hadoop, Spark, or both? To help answer that question, here’s a comparative look at these two big data frameworks.
There’s no question that Spark has ignited a firestorm of activity within the open-source community. So much so that organizations looking to adopt a big data strategy are now questioning which solution might be a better fit, Hadoop, Spark, or both? To help answer that question, here’s a comparative look at these two big data frameworks.
Spark is a scalable open-source Hadoop execution engine designed for fast and flexible analysis of large multiple format data sets—with an emphasis on the word ‘fast’. Compared to Hadoop, Spark runs programs 100 times faster in memory and ten times faster for complex applications running on disk.
Hadoop is a parallel data processing platform that uses open-source software, a distributed file system (HDFS), and the MapReduce execution engine to store, manage, and process very large data sets in parallel across distributed clusters of commodity servers. However, Hadoop has one major drawback. It just doesn’t work very fast when comparing Spark vs. Hadoop. That’s because most map or reduce jobs are long-running batch jobs that can take minutes or hours or longer to complete. On top of that, big data demands and aspirations are growing, and batch workloads are giving way to more interactive pursuits that the Hadoop MapReduce framework just isn’t cut out for.
What sets Spark apart from other tools in the Hadoop herd is the ability to handle both batch and streaming workloads at lightning-fast speeds.
Spark doesn’t just process batches of stored data after the fact, which is the case with MapReduce. Thanks to Spark Streaming, Spark can also manipulate data in real-time, allowing for fast, interactive queries that finish within seconds.
Spark on Hadoop supports operations such as SQL queries, streaming data, and complex analytics such as machine learning and graph algorithms. Spark also enables these multiple capabilities to be combined seamlessly into a single workflow.
It should be pointed out that Spark does not include its system for organizing files in a distributed fashion. But that’s not a problem. Since Spark is one hundred percent compatible with Hadoop’s Distributed File System (HDFS), HBase, and any Hadoop storage system, virtually all of an organization’s existing data is instantly usable in Spark.
To learn how Qubole has optimized the traditional Hadoop model, please visit our Hadoop as a Service page.
MapReduce vs. Spark
 MapReduce is the massively scalable, parallel processing framework that comprises the core of Apache Hadoop 2.0, in conjunction with HDFS and YARN. It has the fundamental flexibility to handle unstructured data regardless of the data source or native format. MapReduce Hadoop is designed to run batch jobs that address every file in the system. It is well suited for large distributed data processing where fast performance is not an issue, such as running end-of-day transactional reports. MapReduce is also ideal for scanning historical data and performing analytics where a short time to insight isn’t vital.
MapReduce is the massively scalable, parallel processing framework that comprises the core of Apache Hadoop 2.0, in conjunction with HDFS and YARN. It has the fundamental flexibility to handle unstructured data regardless of the data source or native format. MapReduce Hadoop is designed to run batch jobs that address every file in the system. It is well suited for large distributed data processing where fast performance is not an issue, such as running end-of-day transactional reports. MapReduce is also ideal for scanning historical data and performing analytics where a short time to insight isn’t vital.
The functions and capabilities of MapReduce Hadoop make it ideal for a number of real-world big data applications. However, as data continues to explode in volume, variety, and velocity, the one area in which MapReduce, with its high-latency batch model, falls short is real-time data analysis.
Spark, on the other hand, was purposely designed to support in-memory processing. The net benefit of keeping everything in memory is the ability to perform iterative computations at blazing fast speeds—something MapReduce is not designed to do.
Spark has another advantage over MapReduce, in that it broadens the range of computing workloads that Hadoop can handle.
Unlike MapReduce, Spark is designed for advanced, real-time analytics and has the framework and tools to deliver when shorter time-to-insight is critical. Included in Spark’s integrated framework are the Machine Learning Library (MLlib), the graph engine GraphX, the Spark Streaming analytics engine, and the real-time analytics tool, Shark. With this all-in-one platform, Spark is said to deliver greater consistency in product results across various types of analysis.
Why Spark on Qubole?
Qubole offers a greatly enhanced and optimized Spark as a service, it makes for a perfect deployment platform. Here are some stats pertaining to Apache Spark on Qubole Data Service (QDS):

Highlights of Apache Spark as a service offered on Qubole
Auto-scaling Spark Clusters:
In the open-source version of auto-scaling in Apache Spark, the required number of executors for completing a task is added in multiples of two. In Qubole, we’ve enhanced the auto-scaling feature to add the required number of executors based on configurable SLA
With Qubole’s auto-scaling, cluster utilization is matched precisely to the workloads, so there are no wasted compute resources and it also leads to lowered TCO. Based on our benchmark on performance and cost savings, we estimate that auto-scaling saves Qubole’s customers over $300K per year for just one cluster.
Heterogeneous Spark Clusters on AWS:
Qubole supports heterogeneous Spark clusters for both On-Demand and Spot instances on AWS. This means that the slave nodes in Spark clusters may be of any instance type.
For On-Demand nodes, this is beneficial in scenarios when the requested number of primary instance type nodes is not granted by AWS at the time of the request. For Spot nodes, it’s advantageous when either the Spot price of the primary slave type is higher than the Spot price specified in the cluster configuration or the requested number of Spot nodes is not granted by AWS at the time of the request. For more details, click here.
Improve Apache Spark Performance by 2.9x with Amazon S3 Select Integration
Optimized Split Computation for Spark SQL
We’ve implemented optimization with regards to AWS S3 listings which enables split computations to run significantly faster on Spark SQL queries. As a result, we’ve recorded up to 6X and 81X improvements on query execution and AWS S3 listings respectively. For more details, click here.
Qubole Multi-Tenant Runtime for Apache Spark
Qubole Open Data Lake Platform provisions dedicated resources per Spark Application through containers in a multi-tenant cluster. It reduces the total cost of ownership (TCO) and improves productivity with faster response time, and a fair share of compute resources.
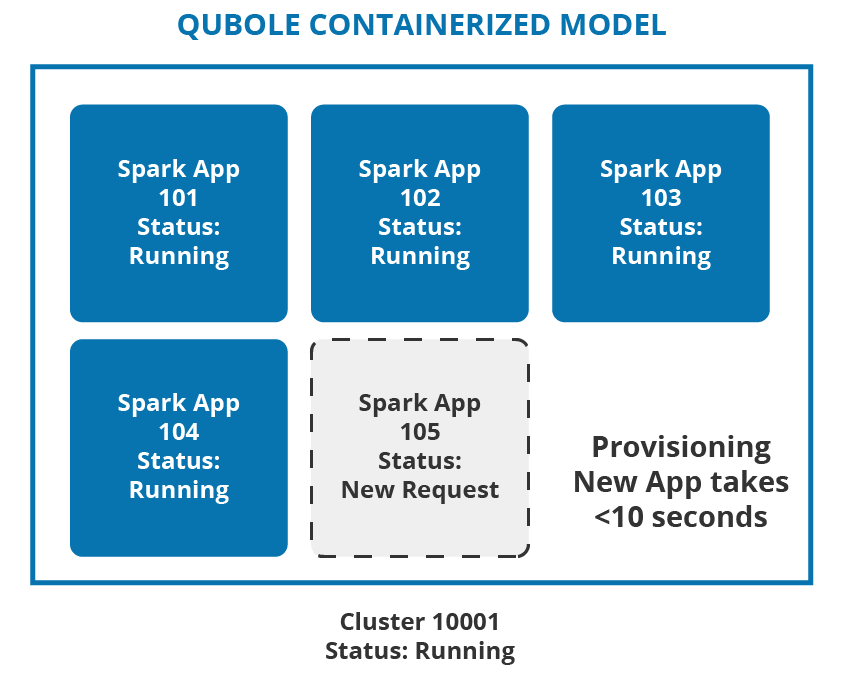
As illustrated above, multiple Spark applications are all provisioned in the same running cluster (Cluster: 10001) and this provides a lower TCO without compromising on the productivity gains of the end-user. Read more on Cost and Performance efficiency with the Multi-tenant Spark Platform
Learn how to optimize Spark clusters on Qubole for cost reliability and performance
“To estimate the cost of Spark jobs, determine how many executors will fit on a node by dividing available node memory by total executor memory size (executor + memory overhead). Then determine EC2 cost for your node type by looking on AWS EC2 instance pricing page and also how many nodes the requested number of executors will fit on,” says Brad Caffey, Staff Data Engineer, Expedia Group.
Watch his presentation on Running Apache Spark jobs cheaper while maximizing performance:
Apache Spark on QDS: New Features and Highlights
Apache Spark 3.0 on Qubole
Spark 3.0 comes with a lot of exciting new features and enhancements. Some of the key highlights of the new release are Adaptive Query Execution, Dynamic Partition Pruning, and Disk-persisted RDD blocks served by shuffle service. There are also significant improvements in pandas API and up to 40X speedups in invoking R user-defined functions. Scala 2.12 is Generally Available while Scala 2.11 is removed in the latest version. On top of the open-source release, we have added over 700 patches to provide various value-added capabilities for our customers. These features are already available with Spark 2.4 version on the Qubole platform and now they can be used with Spark 3.0 clusters as well. Check out some of the supported functionality here.
For further details, refer to the Qubole documentation on Apache Spark here.
Sparklens
Qubole has open-sourced Sparklens a spark profiler and performance prediction tool. Sparklens provides insights into the scalability limits of spark applications from a single run of the application. Sparklens supports reporting using spark’s event-history files, which are generated for all spark-apps by default. Sparklens also tells what could be the maximum memory (spark.memory.fraction) used by an executor in the course of the spark-app run.
Furthermore, Sparklens makes the ROI of additional executors extremely obvious for a given application and needs just a single run of the application to determine how the application will behave with different executor counts. Learn more about Sparklens 0.2.0 here.
Interested to learn the theory behind Sparklens and what it does? Watch this on-demand session on ‘Spark Optimizations with Sparklens presented by Rohit Karlpuria, MTS at Qubole.
Also, to learn how you can use Qubole for various workload types, click here.


