NEW! Spark 3.3 is now available on Qubole. Qubole’s multi-engine data lake fuses ease of use with cost-savings. Now powered by Spark 3.3, it’s faster and more scalable than ever.
Spark Clusters in the Cloud
Ad-hoc analytics and data exploration require computing resources that can process incoming jobs instantaneously and keep the response time low. Apache Spark is a powerful open-source engine used for processing complex, memory-intensive ad-hoc analytics, and data exploration workloads. However, running Apache Spark in the cloud can be complex and challenging. Users try the following approach to run Spark applications in the cloud but cannot achieve the lower Total Cost of Ownership (TCO).
Spark Provisioning
In the legacy model of cloud orchestration, this means the provision of dedicated clusters for each individual tenant as described in the figure below. Each Spark application is provisioned in a separate dedicated single-tenant cluster.
Single Spark Application Per Cluster
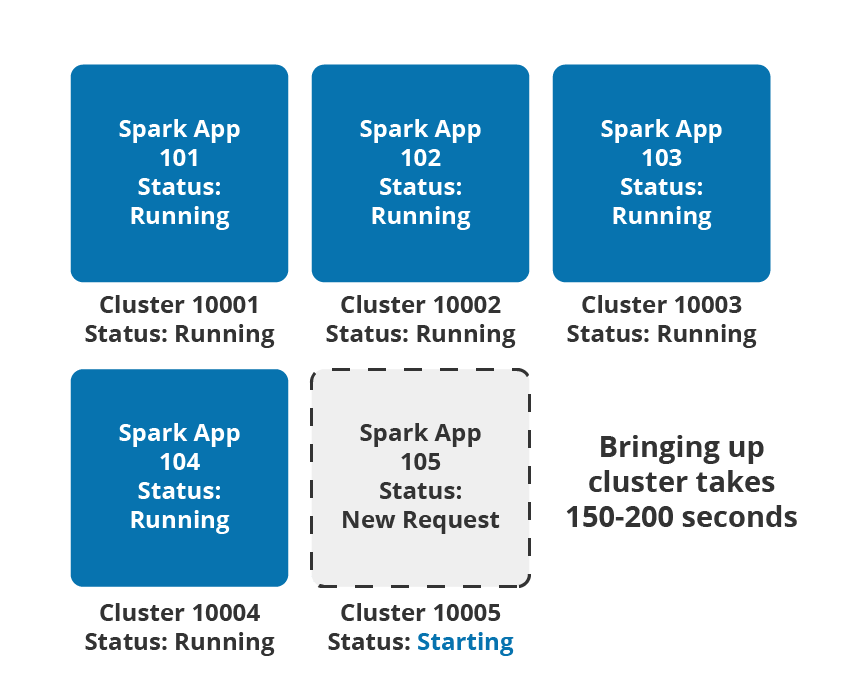
This model is one of the easiest and simplest ways to get started and preferably in an aspiration phase. But this approach is inefficient and results in:
- Unexpected and massive cost overruns with active machines running all the time in the dedicated clusters
- Delayed response time as the process of provisioning a new cluster whenever the users need it can take up to a few minutes. This impacts the end-user productivity and unnecessary delays in interactive jobs.
Multi-Tenant Architecture
With this approach, a single cluster runs several Spark applications that can support multiple users and jobs that require a dedicated set of resources (memory and CPU), and/or jobs that require unique engine configurations. This model is a step in the right direction but runs into spare capacity limitations and fair share resource allocation problems in multi-tenant environments. If the cluster is configured with peak capacity requirements or has a dedicated and static configuration for each spark application, it results in lower TCO.
The challenges described above of single-tenant and multi-tenant clusters have been addressed by the Qubole Open Data Lake Platform.
Multi-Tenant Application Runtime
Qubole Open Data Lake Platform provisions dedicated resources per Spark Application through containers in a multi-tenant cluster. It reduces the Total Cost of Ownership (TCO) and improves productivity with faster response time, and a fair share of compute resources.
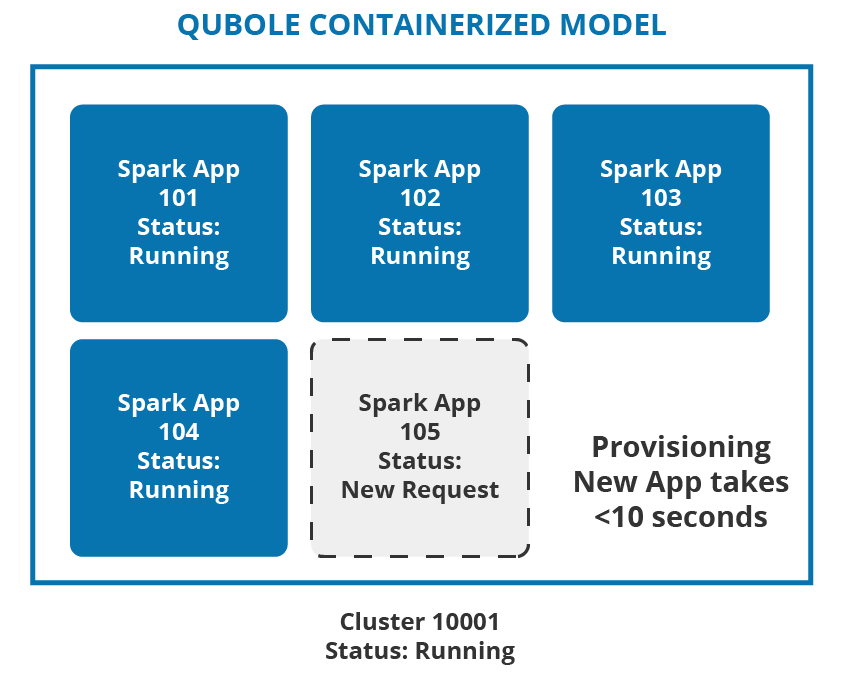
As illustrated above, multiple Spark applications are all provisioned in the same running cluster (Cluster: 10001) and this provides a lower TCO without compromising on the productivity gains of the end-user.
Lower TCO with Multi-Tenant Architecture
Multiple users execute their jobs using Spark applications provisioned inside a containerized multi-tenant cluster. Each Spark application can be configured, to either optimize for performance, cost savings or improve productivity. With a containerized multi-tenant model, users not only have the ability to control job isolation at the per-user or per-job level but also get a fair share of compute resources inside the cluster. The effective utilization of computing resources in this containerized multi-tenant environment leads to lower TCO.
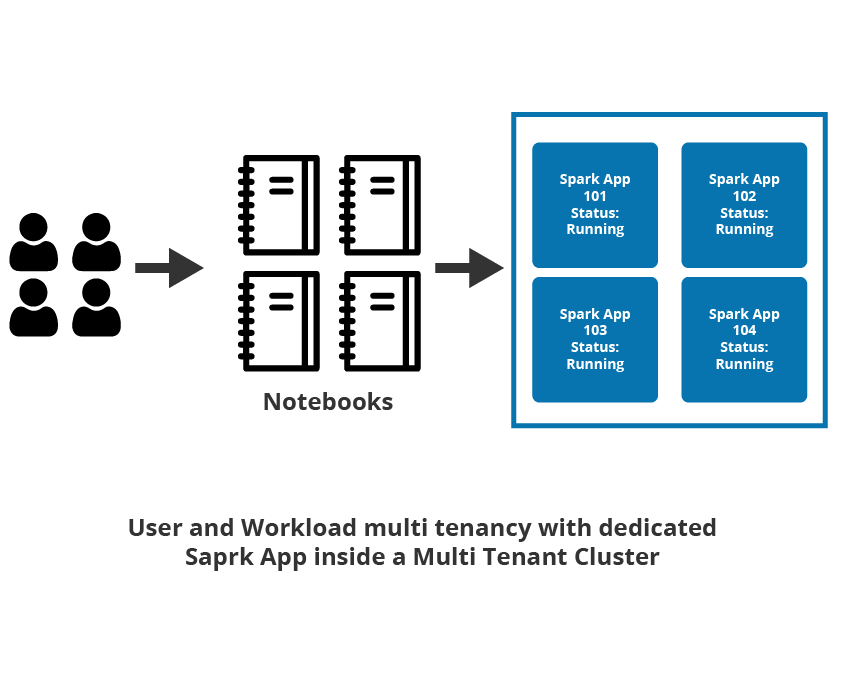
Productivity Gains with Multi-tenancy
In a containerized multi-tenant environment, end-user productivity can be achieved in two ways: by providing isolation from other users thereby eliminating any resource contention that could significantly increase the latency, and by eliminating the wait time involved in provisioning a new cluster.
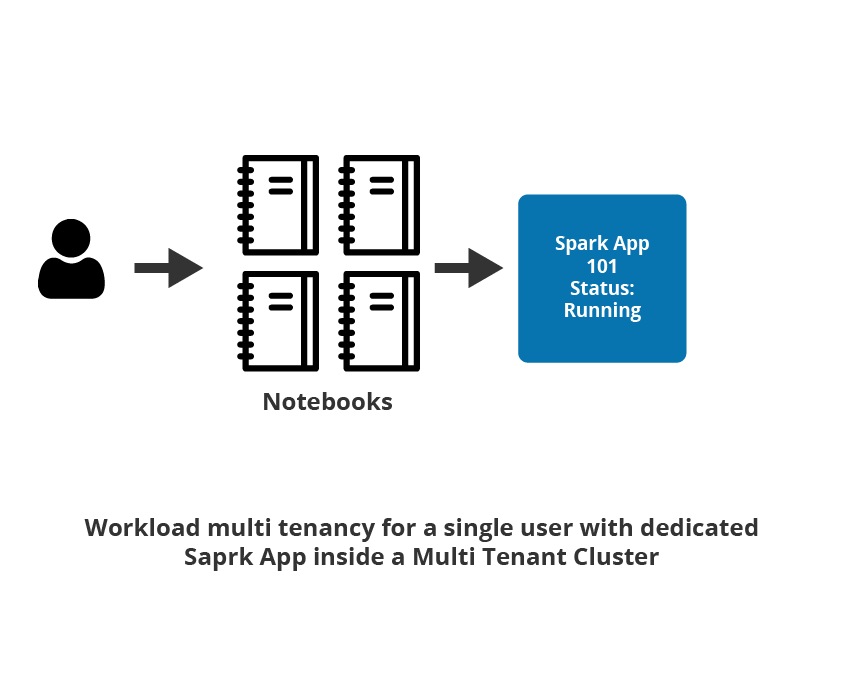
Isolation
While multi-tenancy provides cost reduction, users need a dedicated infrastructure that provides them isolation from other users using the same infrastructure. The single-tenant (per user) Spark application runs multiple jobs submitted by a single user. In this case, all of the commands from the user (through multiple notebooks), are submitted against the same Spark application. Provisioning a dedicated Spark application increases user productivity since the user doesn’t have to compete with other users while using a shared infrastructure to do so helps reduce the cost. In addition, it provides isolation from other users and is faster to launch an application for each job.
Instantaneous Spark App Provisioning
With multi-tenant Spark clusters that can support multiple Spark applications, there is no need to provision a new cluster when a new user has to execute his/her command. Since the cluster is already in a running state, a new Spark application is immediately provisioned thereby eliminating any wait time to bring up the cluster.
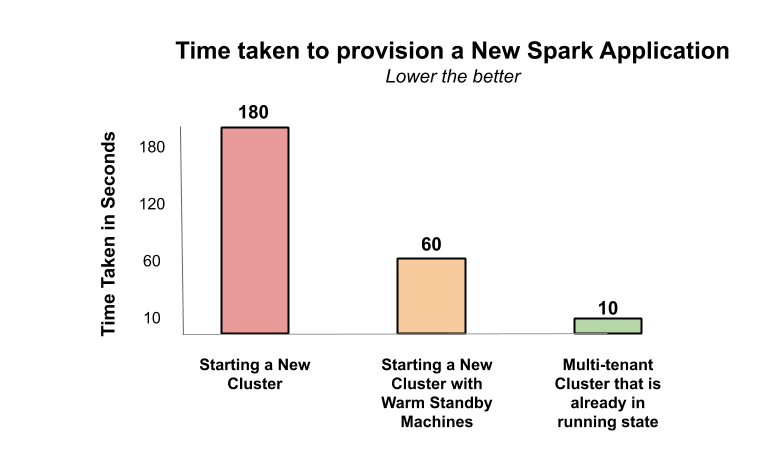
As illustrated below, provisioning a new Spark application is completed in less than a few seconds and the jobs are submitted immediately.
While multi-tenancy provides both cost and productivity benefits, they are constrained by the availability of resources in the underlying infrastructure. New Spark applications can be provisioned only when there is capacity available in the cluster.
Provisioning with Multi-tenancy
Since a multi-tenant cluster is used by several users and workloads, in certain scenarios, the cluster utilization could be high resulting in very low spare capacity. As a result, provisioning the new Spark application could be delayed until more machines are added to the cluster to increase its capacity. This results in a sub-optimal experience since the workload submitted to the cluster now has to wait for the cluster to scale up, which could take 2 to 3 minutes depending on the cloud provider’s compute capacity or completion of running jobs.
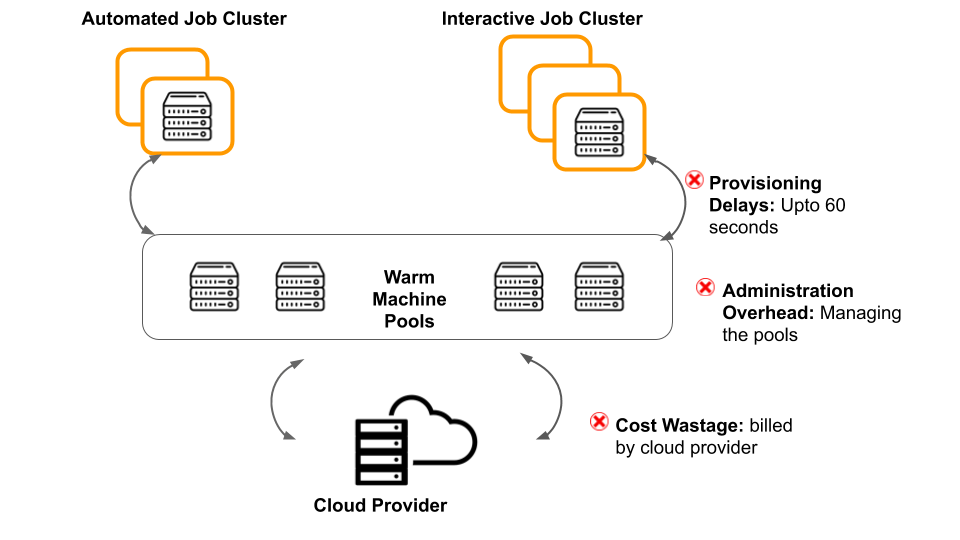
Managed Cache of VMs
An intuitive way to solve this problem is to keep a managed cache of virtual machine instances in standby mode that is active and running. In this model, VMs are proactively acquired from the cloud provider and maintained in a pool. Whenever the cluster requires more VMs for upscaling, these VMs are fetched from the pools and added to the cluster. However, this solution has several drawbacks:
- Cost Wastage: The active machines that are in standby mode and not utilized at all are still billed by the cloud provider.
- Provisioning Delays: Adding these standby machines still takes up to 60 seconds which introduces provisioning delays.
- Administration Overhead: Manual configurations to size the pool and manage the minimum count and the exact time when they have to be provisioned into the cache for standby.
Incurring additional costs for machines for a marginal reduction in provisioning time creates a lot of inefficiencies when the same can be achieved through multi-tenant Spark clusters at no additional cost.
Built-in Pool Mechanism
Qubole Open Data Lake Platform’s built-in pool mechanism can address the demand and supply gaps in the cluster without jeopardizing optimal end-user experience while avoiding unnecessary cost wastage.
At any given point in time, the machines (nodes) belonging to a cluster fall under one of the following lifecycle stages:
- Provisioning
- Active but underutilized
- Decommissioning due to idleness
- Terminating

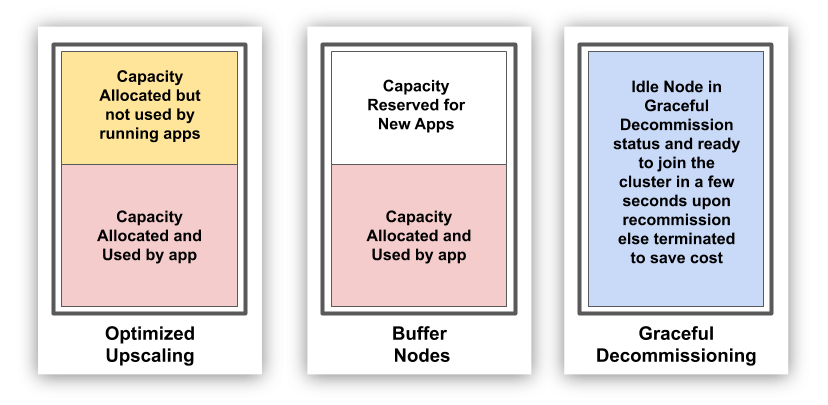
By intelligently leveraging these nodes in different lifecycle stages, Qubole removes the mismatch of demand and supply for new Spark applications without increasing the cost in the following manner:
1. Optimized Upscaling
“Oversubscribe the active but underutilized nodes”
The resources offered by a Virtual Machine (VM) are broken into several logical units called containers. These statically configured containers, in most cases, result in over-commitment and under-utilization of the resources at the machine level.
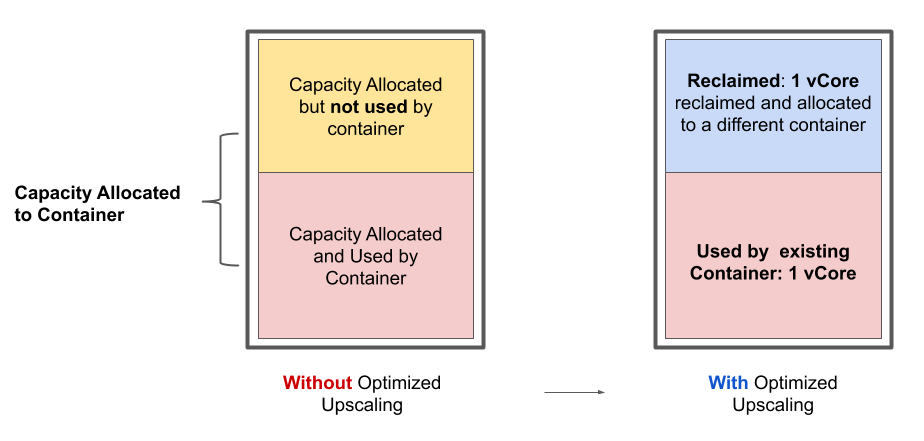
Optimized Upscaling reclaims unused resources from the running applications in the cluster and allocates them to the pending applications. This improves the cluster throughput and reduces the delays due to provisioning machines while lowering the TCO and cost avoidance.
2. Graceful Decommissioning
“Recommission the nodes that are in decommissioning state rather than provisioning new nodes”
When a node has finished executing all of its tasks and becomes idle, it is immediately put into a graceful decommissioning mode for a configurable cool-down period. During this phase, while the node doesn’t accept any new tasks, it is busy offloading the intermediate data (generated by completed tasks) that would be required by tasks from a later stage. Several nodes that are candidates for termination go through this phase, forming a pool of machines that are in standby mode and can be recommissioned if required. Recommissioning a node is much faster than provisioning a new machine, which helps in the instantaneous provisioning of machines.
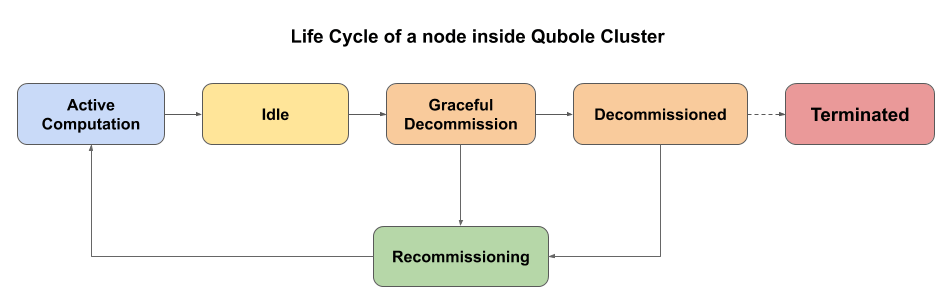
However, if the nodes are not required within the next few mins, Qubole automatically terminates these nodes thereby providing incremental cost savings.
3. Buffer Capacity
“Capacity reserved within existing nodes for new Spark applications”
While Optimized Upscaling and Graceful Decommissioning are great options, certain clusters have a very high utilization resulting in a very low spare capacity.
Buffer Capacity reserves a certain capacity in the cluster for new Spark applications that have to be provisioned without waiting for the cluster to scale up. This reserved capacity is spread across multiple running nodes that are already part of the cluster rather than provisioning dedicated machines in standby mode. This eliminates any delays in provisioning and the commands are executed immediately. Maintaining a buffer capacity in the cluster can increase the cost and introduce unwanted administration overhead. Qubole’s Buffer Capacity eliminates both these problems by providing the following advantages:
- Up to 80% discount: Qubole’s Buffer Capacity supports AWS Spot instances thereby providing up to 80% in savings.
- Zero Administration: Buffer capacity is spread across existing nodes that are of the cluster rather than maintaining them as separate pools. This eliminates the need to separately administer or manage the buffer capacity.
- Auto-Sizing: Static sizing of pools could result in two inefficiencies: over-provisioning or under-provisioning.
While over-provisioning of VMs results in cost wastage, under-provisioning results in unwanted delays since VMs have to be provisioned from the cloud provider on-demand which might take up to 3-4 minutes.
To address this, Buffer capacity, at any given point in time, is dynamically sized based on the current cluster size. As more workloads are submitted to the cluster, and the cluster scales up in response to it, the buffer capacity is also increased. At the same time, when the cluster scales down, the buffer capacity size is also reduced to account for the lower load on the cluster.
Conclusion
Qubole Open Data Lake Platform with a multi-tenant model and multiple pool options provide customers with the flexibility to customize their infrastructure to maximize cost or productivity gains for ad-hoc analytics, data exploration, streaming analytics, or ML workloads.
To learn more about Qubole’s Open Data Lake Platform runtime services click here. You can also experience the benefits firsthand by signing up for a free trial.



