This post is a guest publication written by Saba El-Hilo, a Senior Data Engineer at Mapbox. A version of this post first appeared as a Mapbox devlog.
On a daily basis, Mapbox collects over 300 million miles of anonymized location data from our mobile (iOS and Android) SDKs. We use this data to compute speed estimates for a given time and road generated from historical observations, which answer questions like what is the expected speed on Market St. in San Francisco on Friday at noon?
At Mapbox, we use Apache Spark on Qubole which allows us to take advantage of distributed data processing to calculate 30 billion speed estimates a week for the entire world’s road network. In this post, I’ll walk you through how we were able to do that.
Calculating speed estimates
Telemetry events collected from our SDKs are anonymized, privacy-filtered, and chained into traces that contain coordinate information like longitude and latitude. Eventually, distance, duration, speed, and heading information are derived from consecutive coordinates and are referred to as speed probes.

Probes generated from the traces are matched against the entire world’s road network. At the end of the matching process, we are able to assign each trace an average speed, a 5-minute time bucket, and a road segment. Matches on the same road that fall within the same 5-minute time bucket are aggregated to create a speed histogram. Finally, we estimate a speed for each aggregated histogram, which represents our prediction of what a driver will experience on a road at a given time of the week.
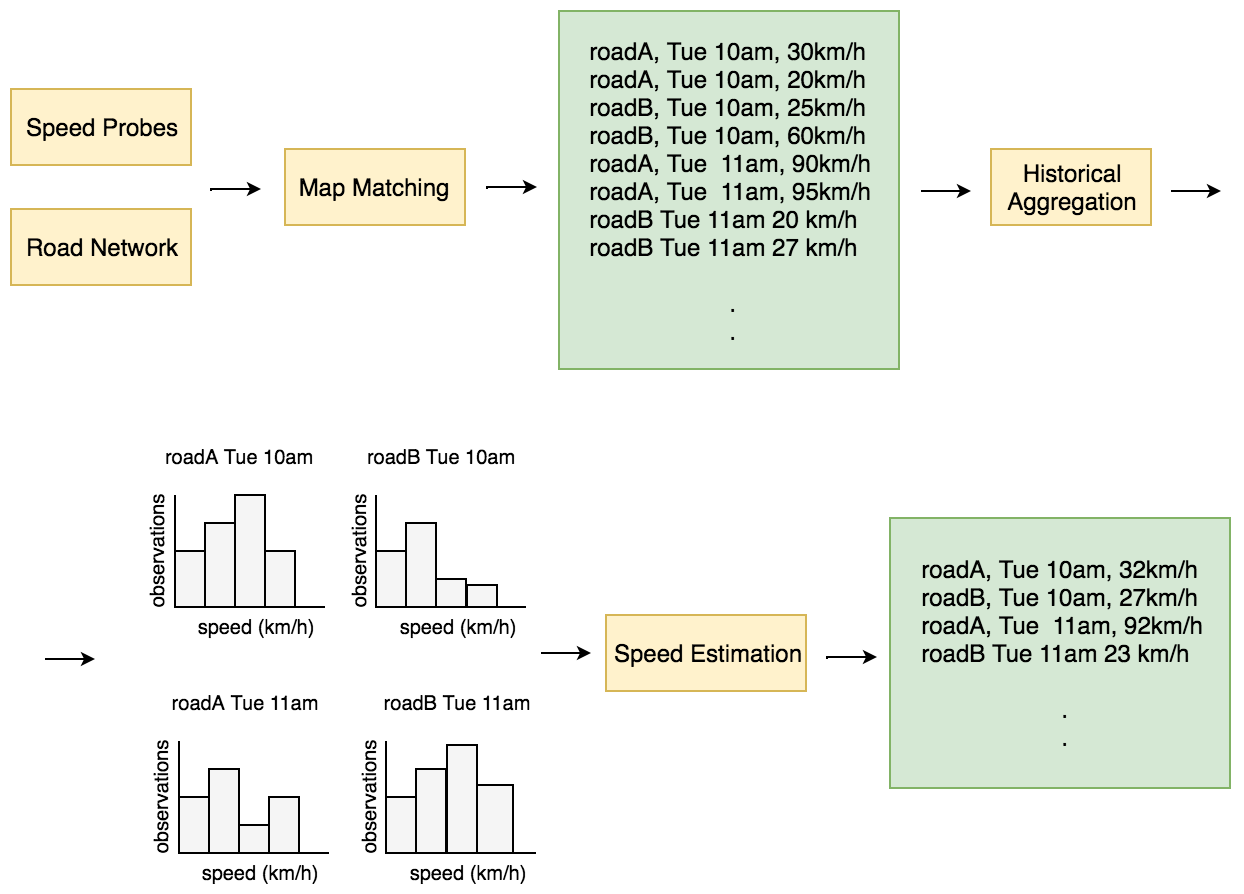
So much data
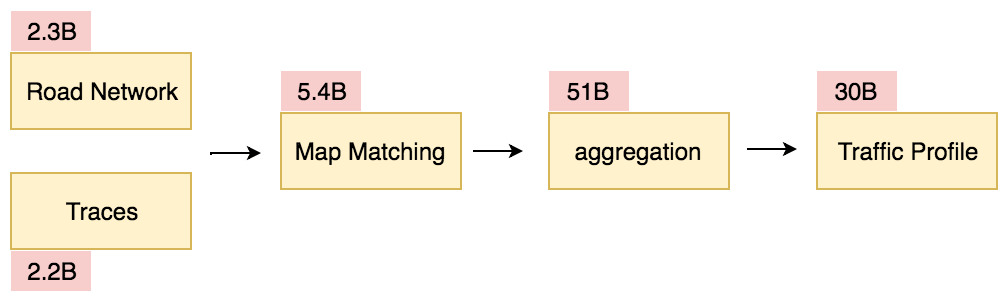
Matching all the telemetry traces against the entire world’s road network on a daily basis and aggregating historical observations to get to a one-speed estimate for a road per 5-minute time interval for every day of the week: You’re probably wondering “wow that must be a ton of data to churn through, but how much really?”
On a weekly basis, we match on average 2.2 billion traces to 2.3 billion roads to produce 5.4 billion matches. From the matches, we build 51 billion speed histograms to finally produce 30 billion speed estimates.
Based on the size of the data, and the complexity of the transformations and calculations, a pySpark implementation made a lot of sense since Spark provides a framework for large-scale distributed computing that allows for fast processing of large datasets.
Data processing pipeline design
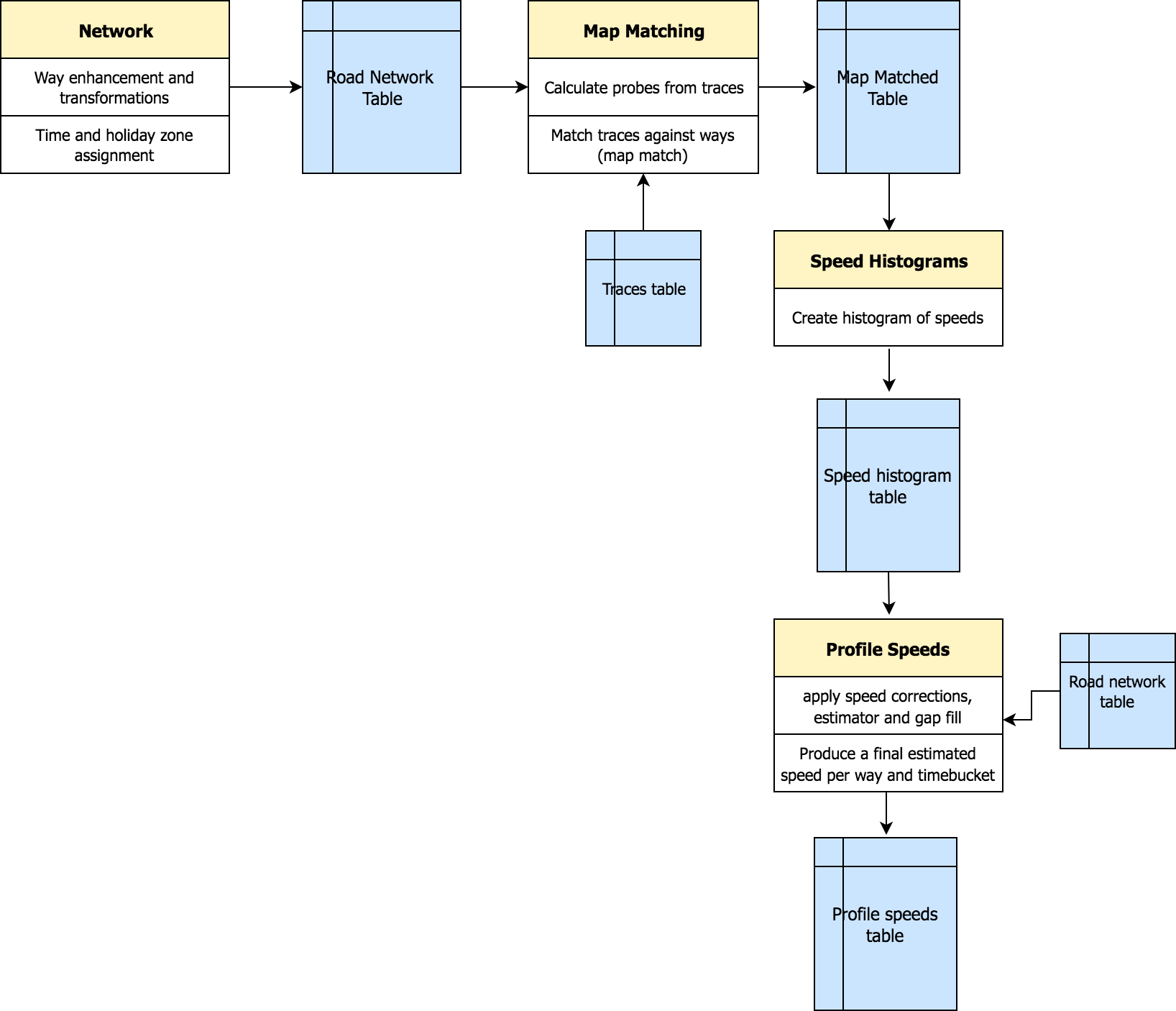
The first thing we spent time on was designing the pipeline and schemas of all the different datasets it would produce. In our pipeline, each pySpark application produces a dataset persisted in a hive table readily available for a downstream application to use.
Instead of having one pySpark application execute all the steps (map matching, aggregation, speed estimation, etc.), we isolated each step to its own application. By doing so, we were able to mock dataset fixtures for each individual application which sped up and distributed early development amongst the team. It also made it possible to test and evaluate the results of complex transformations on real production data. Finally, the intermediary datasets allow data scientists to perform model experiments on different components of the pipeline.
We favored normalizing our tables as much as possible and getting to the final traffic profiles dataset through relationships between relevant tables. Normalization allows table schemas to be defined by the application producing the dataset, maintains data integrity, and removes data redundancy. Naturally, we kept in mind the option to denormalize if a transformation such as a join became prohibitively expensive.
Our pipeline:
Data partitioning
Partitioning makes querying part of the data faster and easier. We partition all the resulting datasets by both a temporal and spatial dimension.
Using Airflow we are able to easily carry over the spatial partitioning into the pipeline orchestration and run a pipeline per partition instead of the “entire world” at once. This reduces the data size within each pipeline which allows for easier scalability. Allowing for faster development, iteration, and frequent testing against production data as you can pick sparser partitions to test the entire pipeline on.
Data skew
Data is in a skewed state if it is not evenly distributed across partitions or a key. This is a common characteristic of telemetry data as you’re always going to have more data in certain geographical locations over others.
When performing transformations like a join, Spark colocates data according to the evaluation of a partitioning expression. If your data is keyed by a variable that is unevenly distributed, you can end up with a few significantly large partitions.
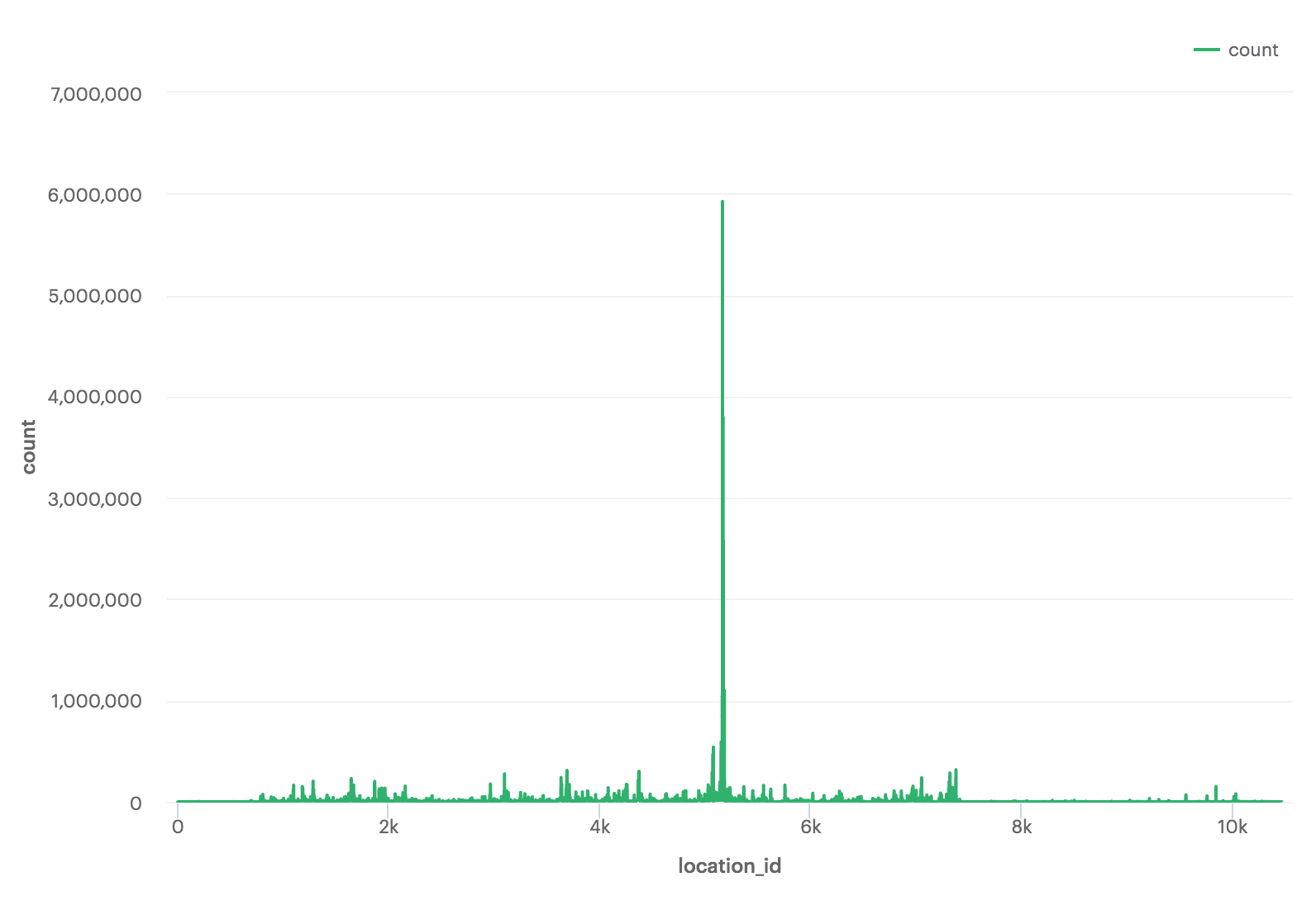
This is a problem when processing because Spark allocates one task per partition. So, if you have one very large partition, the task processing that partition will take the majority of the time whereas 90%+ of the other tasks are completed quickly. Clearly, this defeats the purpose of distributed processing and wastes resources. At the end of the day, you want a reasonable number of tasks that all roughly take the same amount of time to run.
We came across multiple strategies to mitigate data skew:
- Increase the number of partitions: Naively increasing the number of partitions on a data frame using repartition or setting spark.sql.shuffle can help in cases when the data isn’t severely skewed.
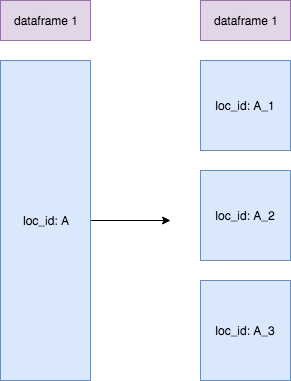
- Create a new unique ID: Adding and re-partitioning on a unique id column will create balanced partitions, as the hash partitioner will assign each of the rows to partitions independent of the skewed variable.

- Salt the skewed key: In cases where you need to perform a transformation like a join on a skewed key, adding randomization to the key will distribute it more evenly. Start by defining an acceptable batch size and salt all the keys in a batch with the same random integer. Effectively, breaking down large partitions into evenly distributed smaller groups.
Conclusion
Our pySpark pipeline churns through tens of billions of rows on a daily basis and provides us with the ability to iterate, make improvements to our models, and evaluate changes quickly.
Working with Spark on Qubole in a project with data at this scale required a deep understanding of Spark internals and an understanding of how the underlying data can significantly affect performance.



