THE COST EFFICIENT
DATA LAKE
Qubole enables you to use all your data engines together,
in one cost-efficient platform.

Upcoming Events! Don’t miss out.
❖ Webinars ❖ Roundtables ❖ Virtual & In-person Events
❖ Top industry experts ❖ Interactive sessions ❖ On-Demand
What is Qubole?
Find out in 65 seconds.
Why Qubole?
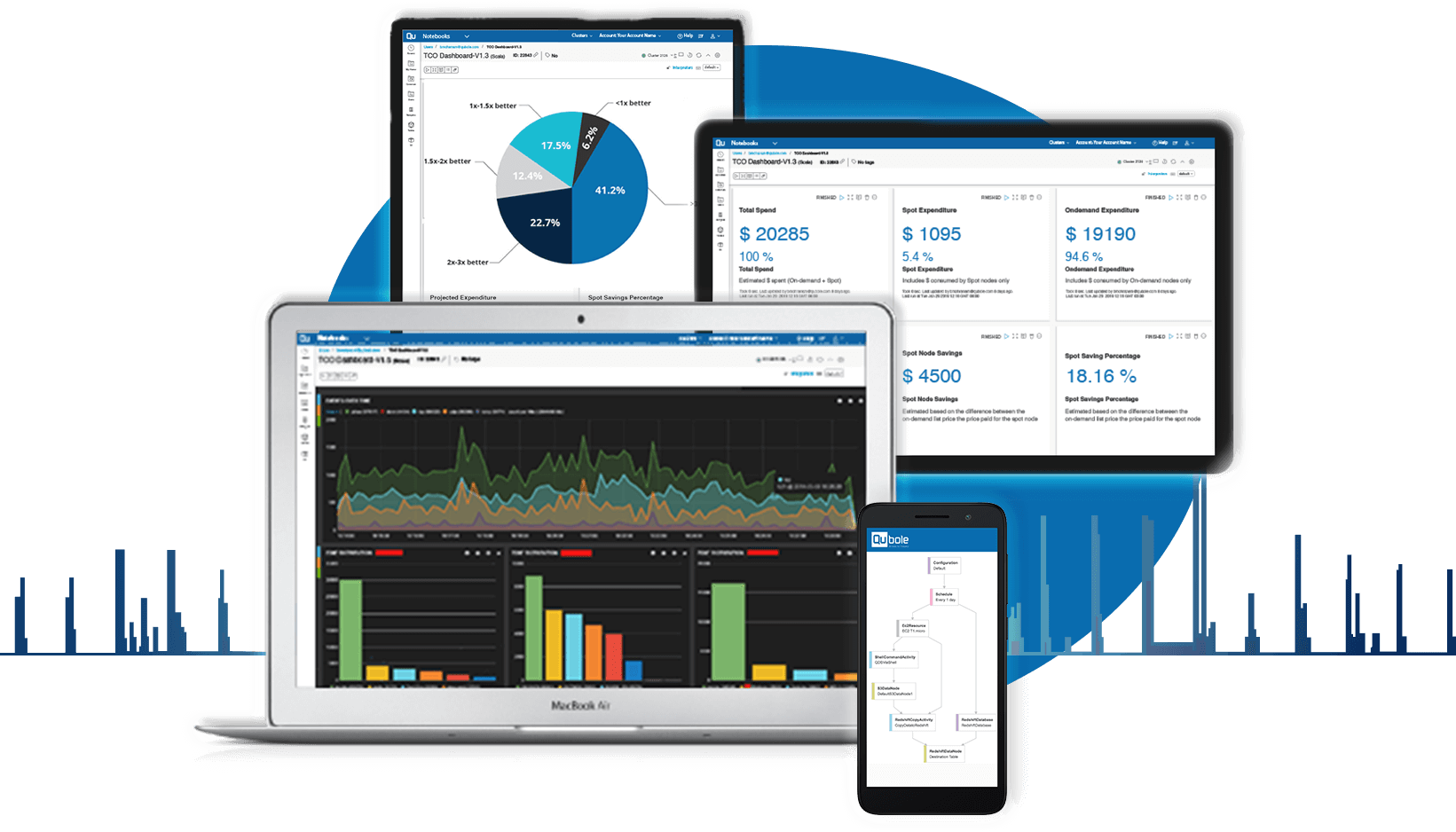
Qubole is a simple, open, and secure Data Lake Platform for machine learning, streaming, and ad-hoc analytics. Our platform provides end-to-end services that reduce the time and effort required to run Data pipelines, Streaming Analytics, and Machine Learning workloads on any cloud. No other platform offers the openness and data workload flexibility of Qubole while lowering cloud data lake costs by over 50 percent.

Open, Simple, and Secure
Delivers faster access to petabytes of secure & trusted datasets of structured & unstructured data.

Fast Adoption at Scale
Out-of-the-box workbench & notebooks for data scientists, data engineers, data analysts & administrators.

Near Zero Administration
Automates installation, configuration & maintenance of multiple open source engines, and tools.

Reduce Cost by 50%
Workload-aware autoscaling and real-time spot buying drive down compute costs dramatically.
EXPLORE QUBOLE



HOW QUBOLE CAN HELP YOU WIN WITH DATA

Machine Learning
Innovate, differentiate, and modernize your platform with data science and machine learning.

Streaming Analytics
Build streaming data pipelines to capture the benefits of real time data for ML and ad-hoc analytics.

Ad-hoc Analytics
Higher productivity, faster time to value and scale to support a larger number of concurrent users.

Data Engineering
Efficiently manage data pipelines with the flexibility of preferred data processing frameworks.
Data
Fabric
A tooling ecosystem to optimize the functions of data architecture, data governance, & data analytics


