This blog covers new benchmark tests to better understand the Autoscaling behavior of concurrent Apache Spark applications. We believe that this will help in advancing research in this space and help data teams evaluate alternative solutions.
Testing for Autoscaling
Autoscaling is the process and technology that automatically allocates the right amount of cloud computing resources or machines required to finish a workload in an acceptable amount of time.
Let’s take a workload that needs to be processed in Apache Spark. Autoscaling automatically increases or decreases Spark executors and cluster sizes needed in response to load and scalability characteristics of the workload.
For this blog, we prepared a set of benchmark tests detailed below, which allow us to compare Qubole with other data platforms. Our findings suggest that Autoscaling with a popular alternative platform (let’s call it ABC) is susceptible to configuration errors and is hard to tune; whereas Qubole Autoscaling works well, out of the box without the need for any configuration changes. In addition, we are only reporting Qubole numbers for the benchmark as ABC Spark clusters failed to finish the benchmark tests well past our generously allotted timeouts and had to be manually terminated.
Apache Spark cluster size changes with Autoscaling
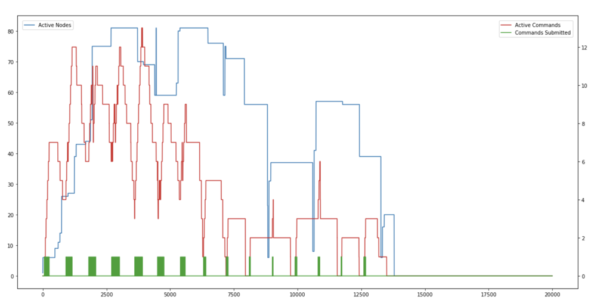
The best way to understand Autoscaling is to see how the cluster size changes with time as new commands are added and old commands finish. Let’s start with some graphs before we get into the details. The blue line shows the current nodes in the cluster, the red line shows the active/concurrent commands. The green bars at the bottom are the command arrival times. The x-axis shows the time. The left Y-Axis shows the number of nodes and the right Y-axis shows the number of active commands.
All tests below used the same Apache Spark Autoscaling benchmark.
How Autoscaling can fail on Apache Spark
We ran some tests on ABC, the alternate platform using the default Autoscaling template. The template has three rules, two for upscaling and one for downscaling;
- Add N nodes if YARNMemoryAvailablePercentage is less than 15% for 1 five-minute period with a cooldown of 5 minutes
- Add N nodes if ContainerPendingRatio is greater than 0.75 for 1 five-minute period with a cooldown of 5 minutes
- Remove N nodes if YARNMemoryAvailablePercentage is greater than 75% for 1 five-minute period with a cooldown of 5 minutes
In the first test, we set N to 1, which is the default value. We can clearly see that this results in very slow upscaling. Many queries failed because of a shuffle broadcast timeout. We had to increase the shuffle broadcast timeout to 10 hours to make this work. Some queries were stuck and had to be terminated manually. Eight commands failed this test.
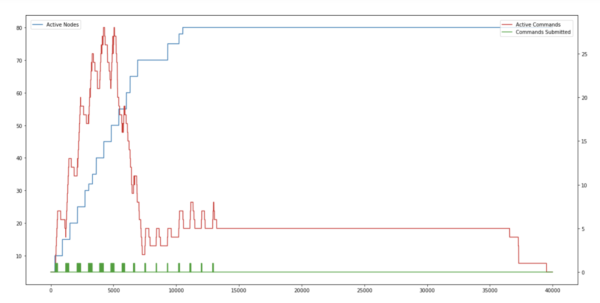
In the second test, we set N to 5. This cluster behaved much better and upscaled to 80 nodes in about 3 hours. The maximum number of active commands in the cluster was more than 25, whereas the maximum concurrent commands submitted were only 11. We had to terminate the cluster manually for ABC’s cluster. In this example, we see the absence of downscaling when the load goes down. Eleven commands failed in this test.
Note that ABC supports multiple metrics and hence these two tests are not a fair representation of ABC Autoscaling. The possible spectrum of “Autoscaling policies” is so large with ABC that it is hard to understand when [manual] configuration ends and “real automation” starts.
How Autoscaling performs on Spark on Qubole
Autoscaling on Spark on Qubole is governed by two main parameters. These are stage Timeout and max executors. Stage Timeout is used as SLA for all stages. Spark on Qubole upscales to meet this SLA. The calculation assumes tasks to be homogenous. We predict the expected completion time for the stage based on the current completion rate of tasks and upscale to meet the SLA. The second most important parameter is the max executors for a given application.
Note that, unlike ABC, none of the commands failed in these tests on Qubole.
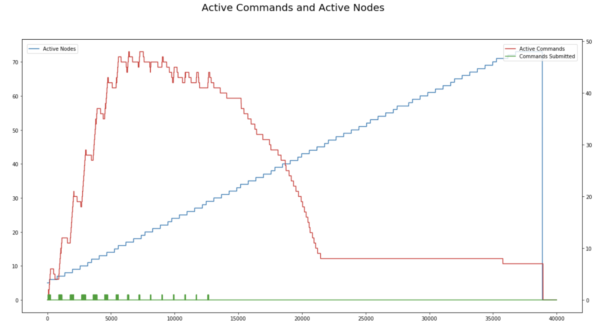
Autoscaling Timeline for Test1
Max Executors 1000, Stage Timeout 2 minutes
Autoscaling Timeline for Test2
Max Executors 1000, Stage Timeout 5 minutes
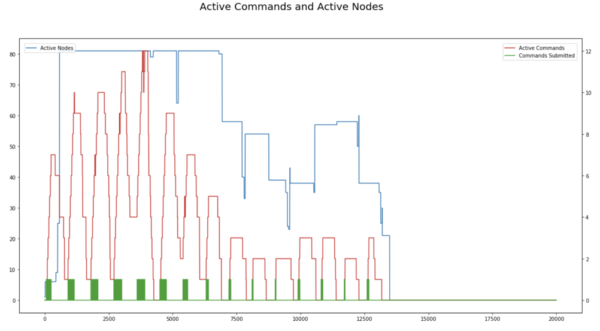
Autoscaling Timeline for Test3
Max Executors 100, Stage Timeout 2 minutes
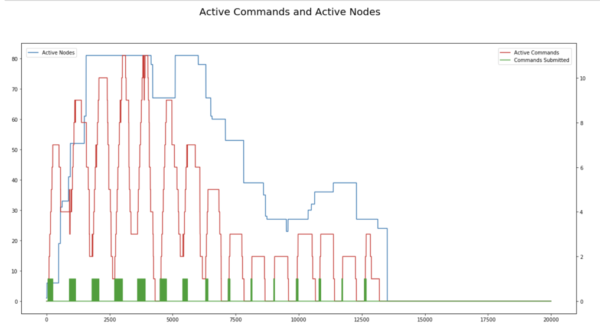
It is clear from looking at these graphs that Qubole Autoscaling adjusts well with the fluctuating workload and keeps the cluster size appropriate for the running queries. This is unlike ABC Autoscaling which needs to be tinkered with to make it work.
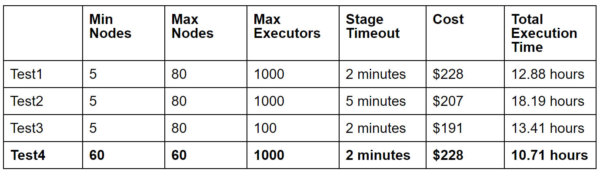
Results Chart
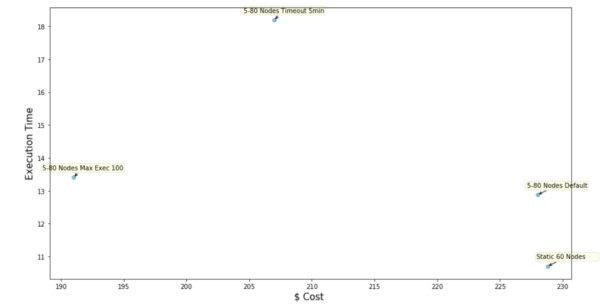
As we can see from the chart, the minimum cost is $191 when we limit the maximum executors to 100. Instead of using a static value, Qubole has an open-source tool called SparkLens, which can be used to estimate appropriate max executor value depending upon cost or time sensitivity. Qubole is also building SparkLens-based Autoscaling, which can automatically infer and adjust maximum executor settings using data from previous runs of a given application.
Even when the maximum executor setting is over-provisioned (1000 for this use case), Spark on Qubole manages to keep costs comparable to a fixed cluster size of 60 nodes with a default stage Timeout of 2 minutes. Increasing stage Timeout to 5 minutes results in lower costs, but it increases total execution time. If the workload is not very time-sensitive, it might be a good idea to increase stage Timeout.
Apache Spark Autoscaling vs Cluster Autoscaling
The difference between Qubole and ABC Autoscaling can be better understood by dividing it into two parts: Spark Autoscaling and Cluster Autoscaling.
The essence of Apache Spark dynamic allocation or Autoscaling is to share cluster resources among concurrent Spark applications.
Whereas the essence of cluster Autoscaling is to adjust cluster size based on demands from concurrent Apache Spark applications.
Qubole Cluster Autoscaling is transparent, as it combines resource requests from concurrent applications to automatically adjust cluster sizes. ABC Cluster Autoscaling—in contrast— treats Cluster Autoscaling as a separate concept altogether. This additional configuration step creates additional divergence, which needs to be realigned and recalibrated as the nature of the number of Spark applications running on a cluster changes.
Apache Spark Autoscaling Benchmark
Most benchmarks for Apache Spark deal with single query/application performance. Typically Spark clusters run many concurrent Spark applications, especially on YARN. So we have created a new benchmark for comparing Autoscaling on Apache Spark clusters that consist of 86 queries. These queries were picked up from the TPC-xBB benchmark. This benchmark typically runs for about 225 minutes.
This benchmark simulates a workload that submits multiple queries to the cluster every 15 minutes. The table below describes all the TPC-xBB queries submitted and the submission timings. All the queries in a given row are part of the same group. Within a group, queries are submitted with 30 seconds delay. We can see in the table that for a group starting at 45 minutes, the last query of the group is submitted after a 5-minute delay. The maximum number of concurrent queries submitted within any group is 11 and the minimum is 2. The workload starts heavy—i.e the bulk of the queries are submitted in the first half of the benchmark, with the second half relatively lean. This is useful for comparing both upscaling and downscaling aspects of cluster Autoscaling.
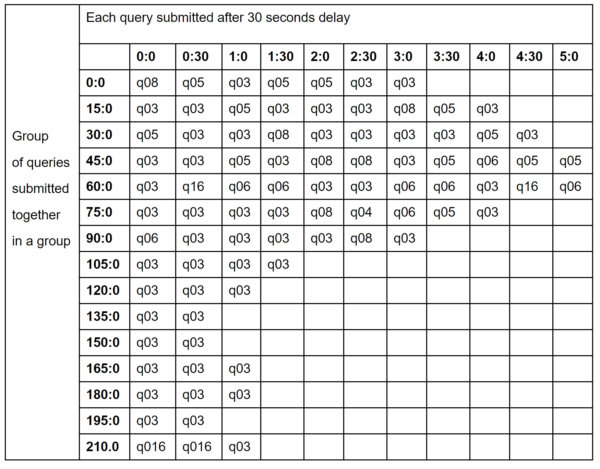
We look at the sum of total wallclock time for each query, the number of queries that succeeded, and the total cost of the cluster to compare the effectiveness of Autoscaling policies.
Configuration Details
All tests were run on a cluster with r4.4xlarge instances. The Spark version used was 2.4.0. Spark driver memory was set to 10GB, explicitly. Spark.sql.autoBroadcastJoinThreshold was increased to 50MB and Spark.sql.shuffle.partitions were increased to 320 from the default of 200. Additionally, Spark.sql.broadcastTimeout was increased to 10 hours for queries running on ABC as they were failing because of a lack of executors. The TPC-xBB data was generated on a scale of 3000.
Conclusion of the Apache Spark Concurrency Benchmark
Our findings suggest that ABC Autoscaling is susceptible to configuration errors and hard to tune, whereas Qubole Autoscaling works well out of the box without any configuration changes required. Given the large range of configurations with respect to Autoscaling for ABC, it is difficult to discern if our tests use the best configuration for ABC Autoscaling. But it is very indicative of a real-world scenario where even expert professionals will face challenges configuring such a platform, as it requires significant manual administrative effort to fine-tune it whenever data distribution is changed, new applications added, or old applications removed from the cluster.
For more information on Apache Spark’s performance on Qubole, please contact your Sales Architect to send us an email.



