Qubole’s autonomous big data platform orchestrates and runs various types of big data workloads whether it is ETL, ad hoc, data science, etc. Native to the cloud (Amazon, Microsoft or Google) and using open source technologies like Spark, Hadoop, Hive and Presto, Qubole is built for any person who uses data like analysts, data scientists, data engineers and dataops. Learn how you can use Qubole for your workload types.
Start Free TrialWorkload Types
Data Science
Data Science is a critical component for success for any company in today’s competitive environment. Qubole’s mission is to build the only Autonomous Data Platform, allowing your data scientists to focus on what matters and solving your business’ most pressing big data challenges without the frustration and wasted time of mundane work. See how Qubole is the best platform for Data Science:
 | Self-Service AnalyticsWith Qubole, Data Scientists no longer need to rely on Data Admins for provisioning compute clusters and resources. Once the exploratory data analysis and/or model development is done, data scientists can productize their notebooks using the notebook API with just a few clicks. |
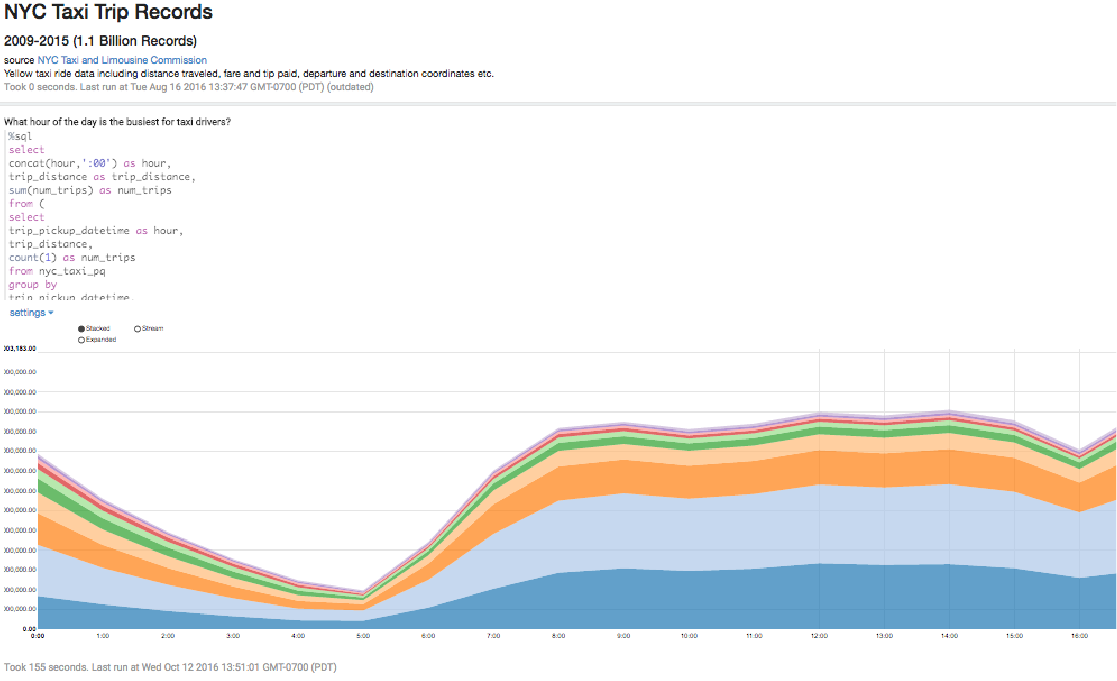 | Big Data VisualizationQubole’s integrated UI lets you access, explore and visualize data all in one place. You have a central location to access data, along with metadata. Additionally, Qubole offers offline meta data access, and Notebooks can save results offline. This means you can access, review, and inspect Notebooks offline, more conveniently and at a lower cost, since you do not need to start a cluster each time. |
 | Cloud ScalabilityIn addition to the Spark processing capability, Qubole has included performance optimizations to run queries 1.5 to 2 times faster. With over 500 PB of data processed monthly, the largest Spark cluster in the cloud (500 nodes), and an average scaling factor of a cluster of 20x, Qubole’s reliability and scalability is second to none. |
 | Data ScienceReturnPath is using Qubole for Data Science initiatives: Given a customer’s past browsing history, purchase history and other characteristics, what are they likely to want to purchase in the future? |
Big Data ETL
ETL can be a major bottleneck for many companies. When ETL is generating roughly 80% of your compute hours, you’re constantly looking for ways to control and cut costs. Qubole’s autonomous data platform helps ETL engineers and data ops focus on what matters most, helping create business outcomes instead of doing tedious, manual, repetitive tasks. See how Qubole is the best platform for ETL:
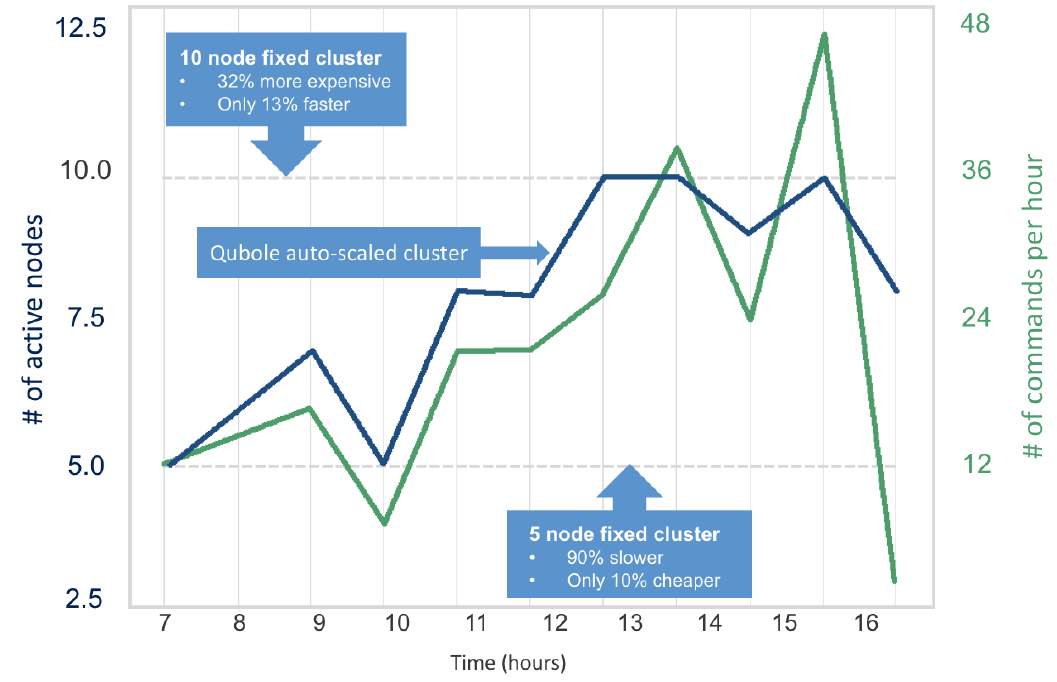 | Cloud AutoscalingQubole’s Cloud Agents™ (Workload Aware Auto-Scaling, Spot Shopper and others) will dynamically reduce the number of compute nodes required to run a workload – which reduces your cloud costs by up to 50%. Agents will intelligently hunt for the best price/performance for the compute nodes you need, which can reduce costs by as much as 80%. Best of all, Qubole helps you optimize your operational costs – allowing Hadoop Engineers to focus on more important work versus maintaining clusters. |
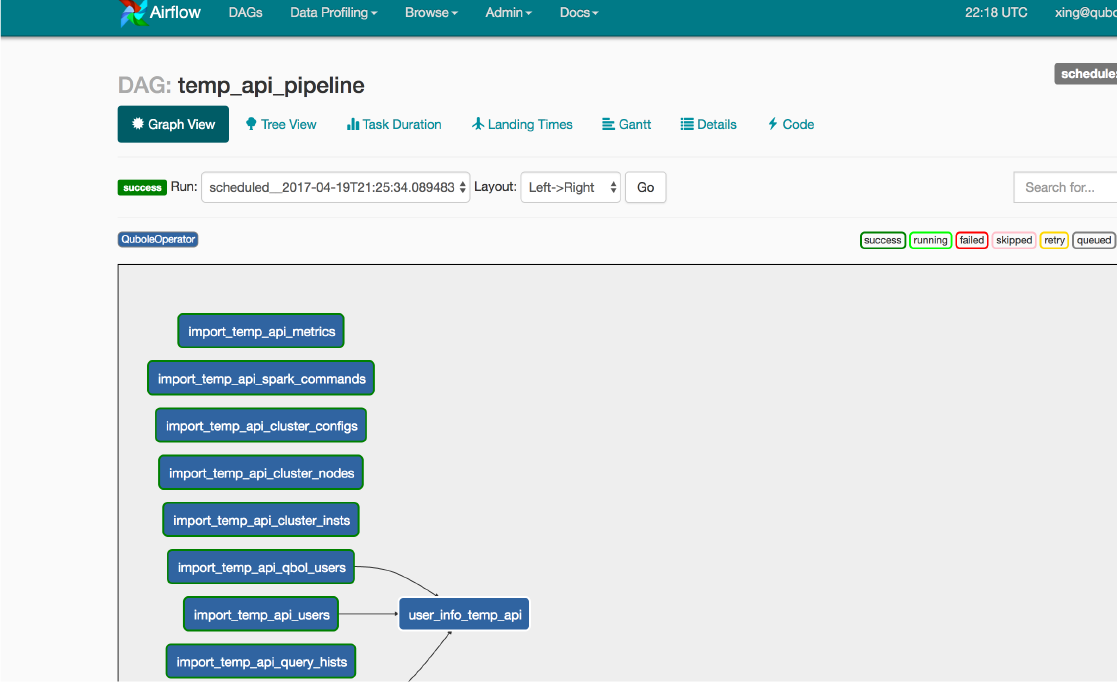 | Data Pipeline ETLQubole is optimized for the cloud and supports many open source engines for ETL, such as Hadoop, MapReduce, Spark, Hive, Pig, and Cascading. Qubole provides the flexibility ETL engineers need. Easily orchestrate pipelines with Qubole’s API/SDKs. In addition, the integrated Airflow engine can provide an overview of your pipeline as well as a simple programming interface. |
 | Cluster ManagementWith Qubole, you can automatically manage your clusters with built-in automation. Thanks to Cloud Agents™, Qubole automates manual tasks to make your team more productive, reduce error rates and increase query performance. If you run QDS on AWS, you can use Spot Shopper to dramatically reduce compute spend: the vast majority of our Spot use cases are, in fact, for ETL. |
Ad Hoc Analysis
Ad Hoc analysis by your Data Analysts or Data Scientists uncover the most critical insights for businesses. However, it’s not easy to size Ad Hoc analysis a priori, and costs can be unpredictable. Qubole’s mission to build the only Autonomous Data Platform allowing your data users to focus on what matters, solving your business’ most pressing big data challenges. See how Qubole is the best platform for Ad Hoc:
 | Ad Hoc WorkloadsAutomation addresses the classic unpredictability, scalability, and cost challenges of running big data in the Cloud. Qubole’s ephemeral clusters isolate ad hoc workloads from other workloads, so you don’t have to worry about unpredictable node sizing. Qubole’s Workload Aware Auto-scaling, Cluster Lifecycle Management, Built-in job scheduler, Spot Shopper Agent (AWS only), and Heterogeneous cluster nodes will increase efficiencies while driving down costs. |
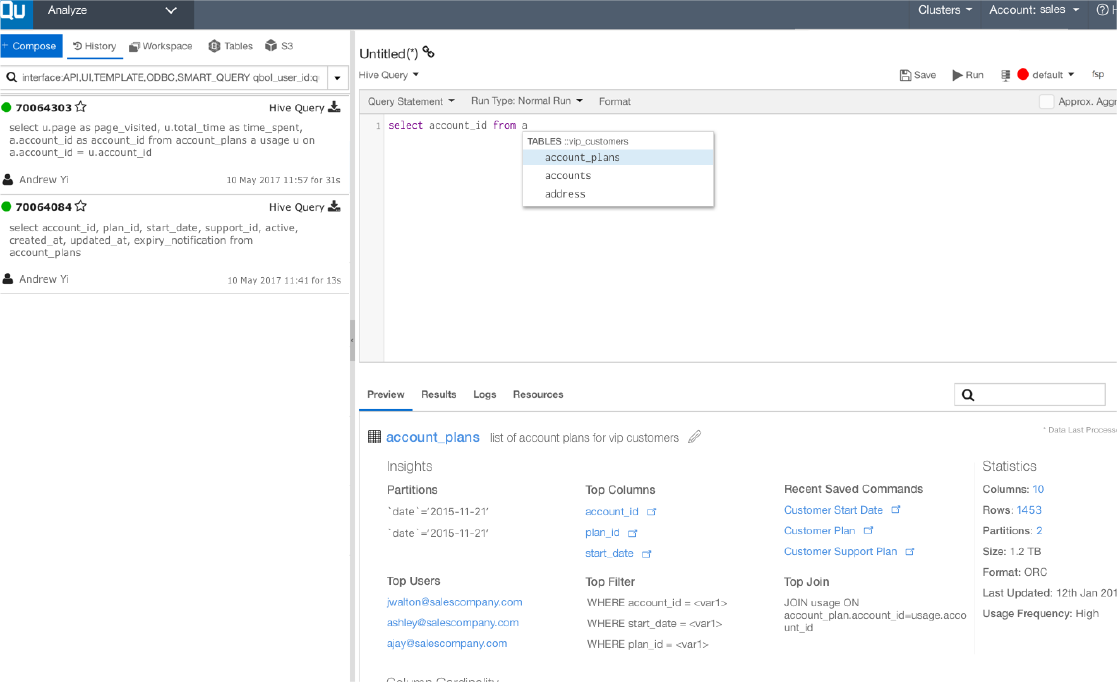 | Data DemocratizationQubole’s integrated UI lets anyone access, explore and visualize data all in one place, which allows you to achieve your data democratization goals. Built-in ACLs (users, groups, and accounts) solve multi-user complexities and allow different business units/teams to solve problems together. Furthermore, unified metastore and zero downtime for migrations and upgrades allow for scalability. |
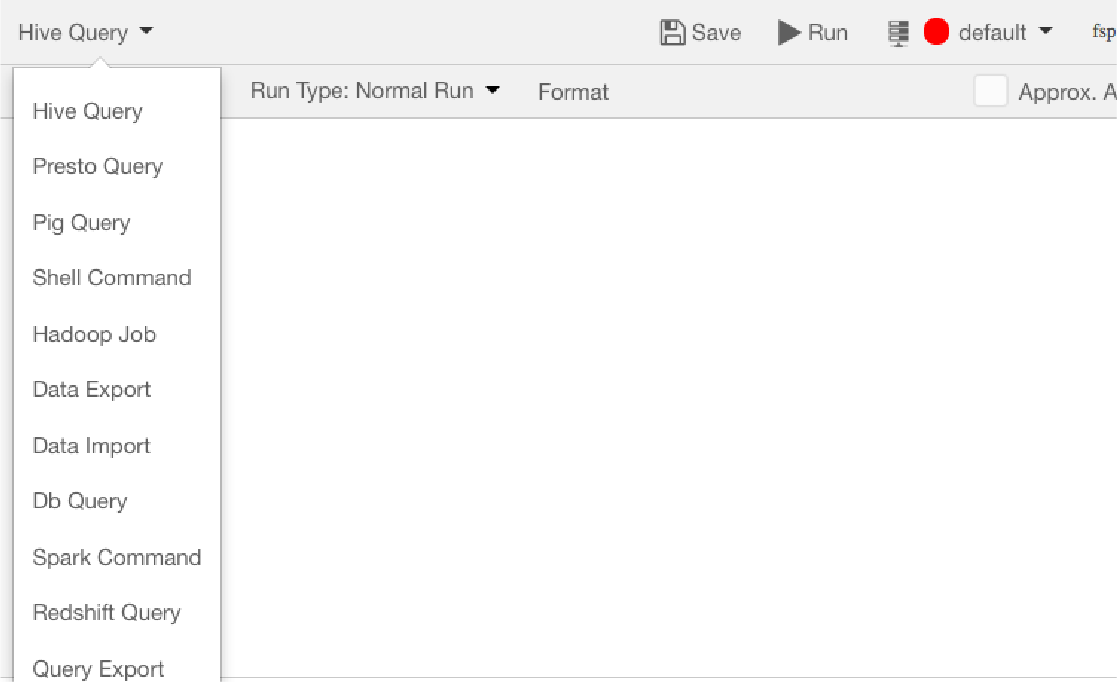 | Ad Hoc EnginesQubole offers you the flexibility you need. Choose from a variety of Ad Hoc engines such as Hive, Presto, or Spark SQL. So, when your Data Analysts and Data Scientists are trying to answer a question that has been asked by someone higher up in the organization (i.e., leader of a business unit or function), they’re not forced to familiarize themselves with different engines. |


