What Is Presto?
Presto SQL
Presto is an open-source SQL query engine built for running fast, large-scale analytics workloads distributed across multiple servers. It was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses. Developed by Facebook, Presto plays a vital role in providing accelerated access to any data store and helps avoid the need to move activated or refined datasets to an on-premises or cloud MPP data warehouse for analytics and reporting.
Enterprise Presto Platforms
Presto supports standard ANSI SQL and has enterprise-ready distributions made available such as Qubole, AWS, Athena, GE Digital Predix, and HDInsight. This helps companies on other data warehouses like Redshift, Vertica, and Greenplum to move legacy workloads to Presto.

Presto can plug into several storage systems such as HDFS, S3, and others. This layer of Presto has an API that allows users to author and use their storage options as well.
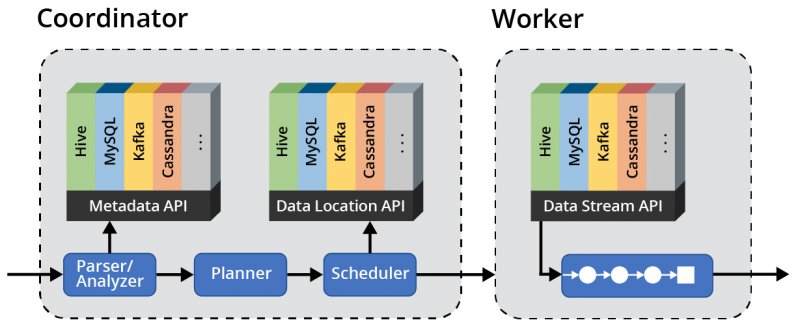
Presto has its own scheduler and resource manager, which makes the execution of queries much quicker and is similar to the design of many relational databases. In fact, for large queries, the performance of Presto is on par with several badged RDBMSs.
How Does Presto Work?
Presto provides several advantages:
![]()
![]() Supports ANSI SQL
Supports ANSI SQL
This includes complex interactive analytics, window functions, large aggregations, joins, and more, which you can use against structured and unstructured data.
![]()
![]() Separates storage from compute
Separates storage from compute
Presto is built such that each command is passed through a master coordinator that dictates which nodes will run the job through a scheduler.
![]()
![]() Supports federated queries to other data sources
Supports federated queries to other data sources
Presto supports querying other database systems like MySQL, Postgres, Cassandra, MongoDB, and more, so you can bring together disparate data sources.
![]()
![]() Performs fast distributed SQL query processing
Performs fast distributed SQL query processing
The in-memory engine enables massive amounts of data to be processed quickly.
Presto Cluster
With the Per-Bucket configuration feature, users can provide the same cluster-level configurations at the bucket level and Presto picks the right configuration set for the bucket being read in the query.
Hive connector in Presto, which is used to read/write tables that are stored in S3 buckets, supports multiple configurations to customize the access to these buckets, for example, using Instance Credentials for S3 authentication, using KMS for data encryption, etc. These configurations, by default, are applied to all the buckets that are accessed from the cluster. But, there are use cases where buckets with different configurations are to be accessed from the same cluster.
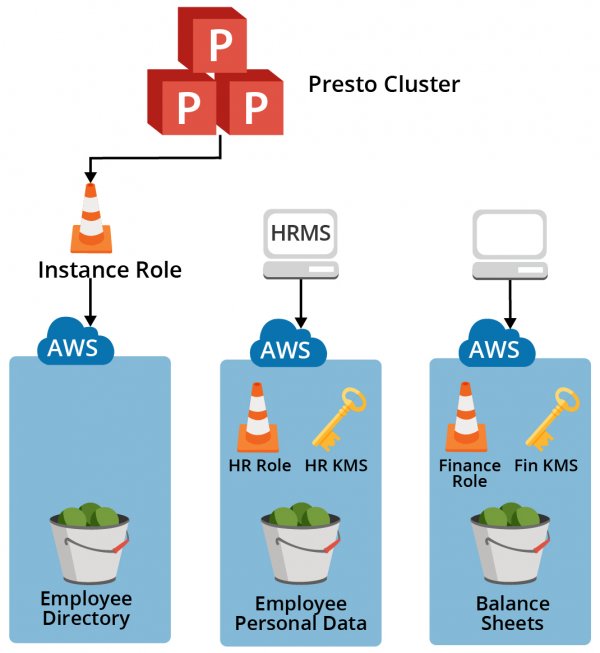
In the above diagram, the instance role is only provisioned to access the general data bucket ‘Employee Directory’. The buckets like ‘Balance Sheets’, and ‘Employee Personal Data’ have a separate IAM role and KMS configuration attached. To use Presto, an employee from the finance department needs to update the Hive connector configuration according to the ‘Balance Sheets’ bucket and then restart the cluster. Thus, the same Presto cluster can’t be used by different departments concurrently and needs a Presto restart.
In such cases, per-bucket configurations described in this blog post should be used so that Presto can dynamically pick the right configuration for the bucket being accessed by the query.
Presto Query
The resource group mechanism ensures that groups using more than their allocated quota are penalized, preventing any group from exceeding its quota limit. It is a reactive gating mechanism that checks whether a resource group has exceeded its limit before letting it start a new query. Resource groups in Presto can be configured like a tree, where non-leaf groups can be further subdivided into multiple resource groups. It defines soft and hard limits for CPU usage and hard limits for memory usage (which is interestingly referred to as ‘softMemoryLimit’). Resource groups in Presto can control query scheduling based on a hard concurrency parameter, which can be configured either in isolation or in conjunction with soft limits on CPU utilization.
Resource groups are an important construct in Presto to control resource usage and query scheduling. Many Qubole customers have expressed interest in trying out resource groups for their production workloads but were unable to do so because of the complex configuration involved. Read this blog to understand how to configure and leverage Resource Groups in Presto.
Presto Analytics
Qubole Presto is a cloud-optimized version of open-source Presto, with enhancements that improve performance, reliability, and cost. We have tried to make sure we offer one of the best-performing and easy-to-use Presto-based services.
A good subset of Big Data analytics involves interactive, exploratory queries which can be expressed in ANSI-SQL – and Presto targets this use case. As a PaaS provider, we provide multiple options to our users so they may evaluate these and other tools like Pig and MR without a lot of effort and choose the tool that works best for them.
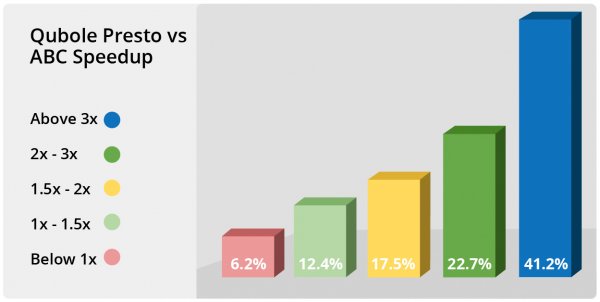
Presto on Qubole is 2.6x faster than ABC Presto in terms of overall Geomean of the 100 TPC-DS queries for the no-stats run. More importantly, 94 percent of queries were faster on Presto on Qubole, with 41 percent of the queries being more than 3x faster and another 23 percent of the queries being 2x-3x faster. In this blog post, we compared the Presto service on Qubole against one of the popular competitors Presto offerings (referred to as “ABC”) in AWS.
Spot Instance Interruption
Presto on Qubole differentiates itself via value additions that handle Spot interruptions without sacrificing reliability. These features are switched on by default and transparently provide higher reliability and stability to most Qubole users who find Spot nodes to be a great way to reduce their cloud bills.
This blog quantifies these benefits using real-world Spot interruption data from a customer’s workload on Amazon Web Services (AWS). We also compare against a competitive Presto offering (referred to as “ABC” throughout this blog). Click here to read more.
Combining Presto and Spot nodes seems like an obvious choice to build a highly performant and economical solution — but Presto and Spot nodes do not work well together. Highly efficient implementations and design choices like in-memory execution and pipelined stage execution make it possible for Presto to run as fast as it does today. However, these same features also prevent Presto from leveraging Spot nodes. This blog post explores how Qubole allows our customers to get the best of both worlds. Click here for a detailed explanation.
Spot Instance Rebalancing
Spot Rebalancing feature in Presto helps in scenarios when the <short-lived compute instances> ratio of a running cluster falls short of the configured spot ratio due to unavailability or frequent terminations of spot nodes. The Spot rebalancer ensures that the cluster proactively recovers from this shortfall and it brings the cluster to a state where its <short-lived compute instances> ratio is as close as possible to its configured value.
By default, after every 30 minutes, Qubole inspects the <short-lived compute instances> ratio of the cluster and attempts a rebalancing if the <short-lived compute instances> ratio falls short of the configured <short-lived compute instances> ratio. The time period for the <short-lived compute instances> ratio inspection is configurable using the ascm.node-rebalancer-cooldown-period parameter.
An example of using this configuration is setting ascm.node-rebalancer-cooldown-period=1h in the Presto cluster overrides. If this example setting is used, Qubole inspects for a skewed <short-lived compute instances> ratio every hour instead of 30 minutes
Qubole has improved Spot Rebalancer to handle cluster composition where all minimum nodes are spot nodes or all nodes (including the coordinator node) are spot nodes (that is a Spot-only cluster). For more information, click here.
Datadog Monitoring
Presto clusters support the Datadog monitoring service. You can configure the Datadog monitoring service at the cluster level as described in Advanced Configuration: Modifying Cluster Monitoring Settings, or at the account level. For more information on configuring the Datadog monitoring service at the account level on AWS, see Configuring your Access Settings using IAM Keys or Managing Roles.
In addition to the default Presto metrics that Qubole sends to Datadog, you can also send other Presto metrics to Datadog. Qubole uses Datadog’s JMX agent through the jmx.yaml configuration file in its Datadog integration. It uses 8097 as the JMX port. This enhancement is available for beta access and it can be enabled by creating a ticket with Qubole Support.
Enabling Datadog on a Presto cluster on Qubole will create a default dashboard (Account <account owner> Cluster <label> (<cluster ID>)) with default metrics and alerts:
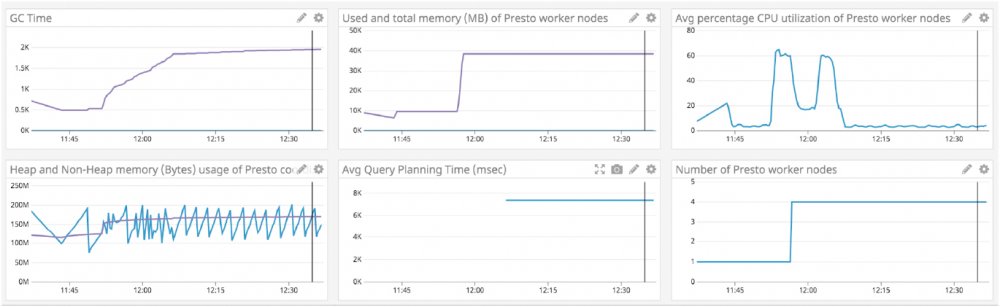
Learn more on how Qubole enhances Presto Cluster Monitoring with Datadog.
Presto on Qubole
Using an open-source engine like Presto gives you an advantage over others’ work while remaining in control of your own technology. Because Presto doesn’t typically care what storage you use, you can quickly join or aggregate datasets and can have a unified view of your data to query against. The engine is also built to handle the data processing in memory. Why does this matter? If you can read data more swiftly, the performance of your queries improves correspondingly—always a good thing when you have business analysts, executives, and customer reports that need to be made available regularly.
Using Presto on Qubole to process SQL workloads has directly equated to more positive experiences for customers. Leveraging Presto on Qubole and its new data infrastructure, an advertising software company has achieved improvements with far-reaching business impacts. The company has been able to optimize data pipelines and deliver rich reporting that allows its clients to make smarter business decisions. Read how this company processes over 10 billion daily events with Presto on Qubole.
For technical details on setup, configuration, deploying, and using Presto as a service on QDS, please refer to our documentation.


