Introduction
Presto can access S3 Buckets using one of the following options:
- IAM roles provided in the configuration
- Access-key/Secret-key provided in the configuration
- Credentials fetched from InstanceProfileCredentialsProvider
In all these options, it is assumed that all buckets that will be queried, will be accessible through these credentials. But in some use-cases, there is a need for multiple credentials, particularly different credentials for different S3 Buckets. In this blog post, we will cover the ‘Per-Bucket Configuration’ feature that we added in Presto on Qubole for such use-cases. With this feature, users can provide the same configs that they provide at the cluster level, now at the bucket level too and Presto picks the right configuration set for Bucket being read in the query.
Overview
Hive connector in Presto, which is used to read/write tables that are stored in S3 buckets, supports multiple configurations to customize the access to these buckets e.g. using Instance Credentials for S3 authentication, using KMS for data encryption, etc. These configurations, by default, are applied to all the buckets that are accessed from the cluster. But, there are use cases where buckets with different configurations are to be accessed from the same cluster.
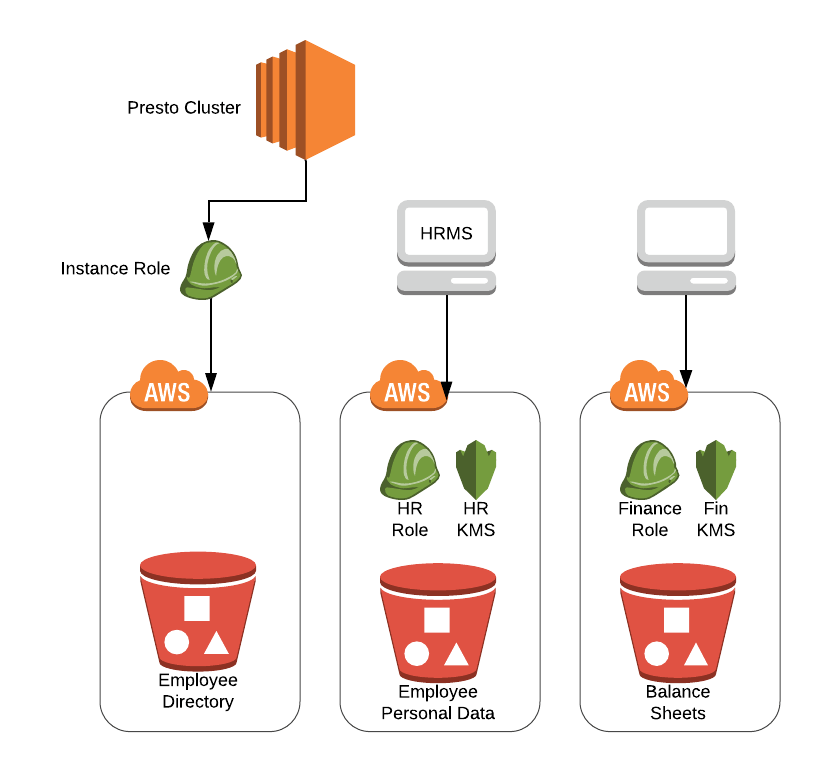
In the diagram above, instance role is only provisioned to access the general data bucket ‘Employee Directory’. The buckets like ‘Balance Sheets’, ‘Employee Personal Data’ have a separate IAM role and KMS configuration attached. To use Presto, an employee from the finance department needs to update hive connector configuration according to ‘Balance Sheets’ bucket and then restart the cluster. Thus, the same Presto cluster can’t be used by different departments concurrently and needs Presto restart.
In such cases, per-bucket configurations which are described in this blog post should be used so that Presto can dynamically pick the right configuration for the bucket being accessed by the query.
Enabling per bucket configuration
In catalog/hive.properties, hive.s3.bucket-config-base-path represents the base path to store all the bucket configurations. If this configuration is not set, which is the default behaviour, then all buckets would be accessed by the same IAM role and with common S3 configuration.
For each bucket configuration, there should be a file named .properties at a path configured by property hive.s3.bucket-config-base-path.
Bucket Configuration
Apart from basic configs, the bucket configuration supports advance configuration mentioned below. The bucket configuration will be provided in a Key=Value format as:
hive.s3.role-arn=<String>
hive.s3.role-ext-id=<String>
hive.s3.ssl.enabled=<Boolean>
hive.s3.path-style-access=<Boolean>
hive.s3.use-instance-credentials=<Boolean>
hive.s3.sse.enabled=<Boolean>
hive.bucket-owner-full-control=<Boolean>
hive.s3.pin-client-to-current-region=<Boolean>
hive.s3.endpoint=<String>
hive.s3.signer-type=<String>
hive.s3.kms-key-id=<String>
hive.s3.sse.kms-key-id=<String>
hive.s3.encryption-materials-provider=<String>
hive.s3.sse.type=<String>
For consistency and ease of use, bucket configuration property names are kept the same as of hive catalog configuration. The sample cluster configuration and bucket configuration, that goes into Presto overrides in Cluster Configuration page (Configuring a Presto Cluster), is described below:
catalog/hive.properties:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:10000
hive.allow-drop-table=true
.
.
.
hive.s3.bucket-config-base-path=/usr/lib/presto/etc/
hr-employee-data.properties:
hive.s3.role-arn=arn:aws:iam::<AWS-account>:role/hr-role
hive.s3.role-ext-id=<role-ext-id>
hive.s3.ssl.enabled=false
hive.s3.path-style-access=false
hive.s3.use-instance-credentials=true
hive.bucket-owner-full-control=true
hive.s3.pin-client-to-current-region=false
hive.s3.endpoint=http[s]://hr-employee-data.s3-<AWS-region>.amazonaws.com
hive.s3.signer-type=S3SignerType
hive.s3.sse.enabled=true
hive.s3.sse.type=kms
hive.s3.sse.kms-key-id=<KMS Key ID>
hive.s3.kms-key-id=<Key ID>
hive.s3.bucket-config-base-path line enables per bucket configuration and configures Presto to look for bucket configurations in /usr/lib/presto/etc/. As described in the documentation (Understanding the Presto Engine Configuration), each section header creates/updates the file under /usr/lib/presto/etc/ with the same name as the header, hence /usr/lib/presto/etc/hr-employee-data.properties file will be created which will be picked as a configuration file for hr-employee-data bucket. For all other buckets, the default configs will be used.
Role selection for Bucket access under different scenarios
Depending upon the Cluster role setup, Bucket configuration setup and User overridden role setup different combinations can arise and the right role has to be selected to access the bucket. We cover the most important combinations of these configs below:
- No bucket configuration: Cluster instance role will be used to access the bucket.
- User overridden role provided: Cluster instance role will first assume the user overridden role and then access the bucket.
- Bucket configuration provided: Cluster instance role will access the bucket using the bucket configuration.
- Both user overridden role and bucket configuration provided: Cluster instance role is a super role and can access every other role. Therefore, the cluster will directly access the bucket using the bucket configuration assumed by the Cluster instance role.
Summary
- To enable bucket configuration support, property ‘hive.s3.bucket-config-base-path’ should be set in catalog/hive.properties.
- The bucket configuration file name should be the same as that of a bucket.
- In case of any change in a bucket configuration file, Presto Cluster needs to be restarted to reflect the latest changes.
- The bucket configuration file should be present at the path as defined by property ‘hive.s3.bucket-config-base-path’.



