Presto optimizes cluster utilization by assigning work to the cluster nodes uniformly across all running queries. This prevents nodes from becoming overloaded, which would lead to a slowdown of queries due to the overloaded nodes becoming a compute bottleneck.
Presto’s current scheduling algorithm works well if all work items assigned to the nodes are equal in terms of CPU and I/O requirements. This is true for cases when tasks are reading from the cloud stores, with each work item reading an almost equal amount of data and doing similar calculations on that data.
However, this assumption breaks if the source of data is the cluster itself, e.g. in the case of RubiX the data is read from the disk of the cluster nodes. In such cases, the I/O requirement of the work item depends on the placement of the work item: if it executes on the same node where data resides, then the I/O requirement is lesser than when it executes on a node other than the one where data resides (since it must read data from a remote node over the network). Thus, depending on the placement of the work item, query performance and network traffic will vary in the current scheduling model of Presto.
To improve query performance and minimize network traffic for such cases, we have implemented a new scheduling algorithm in Presto on Qubole. Optimized Local Scheduling considers data locality along with existing load on the cluster nodes. In this blog, we will cover in detail:
- Why do existing scheduling algorithms of Presto fall short in optimizing execution in cases like RubiX
- The details of the Optimized Local Scheduling algorithm that fill those gaps and improve the local cache hit rate in RubiX
- A case study showing the efficacy of the Optimized Local Scheduling algorithm
Data Locality and RubiX
When Presto queries are run in a RubiX-enabled cluster, RubiX ensures that the data gets cached in the worker node’s local disk when it executes the split that reads the data from cloud storage. Once the data is available in a worker node, subsequent reads of that data will be served from that worker node’s disk instead of using the cloud source. (Refer to this RubiX blog for more details.)
When a split executes on the same node where the required data resides, it is referred to as a ‘cached read’. On the other hand, when a split executes on a different node in the cluster, it is referred to as a ‘non-local read’; in such a case, the data is read over the cluster network. Because cached reads are served locally without any network transfer, they are faster than non-local reads. Therefore, it is desirable to have a higher number of cached reads than non-local reads.
RubiX provides hints to the Presto scheduler about the locality information of the split, and it is up to the Presto scheduler to assign splits as per its assignment policies. Query performance and network traffic depend a lot on this assignment. In the next section, we cover the options available in Presto scheduler for assignments based on locality to see what can be done with existing options.
Locality-Based Scheduling Options in Presto
The default Presto scheduler assigns splits to nodes without any consideration of the locality of splits. For every split, the scheduler looks for a node with the maximum free slots available and assigns it to that node. This results in a uniform workload, but may also lead to a large number of non-local reads and few locally cached reads when Presto is used alongside RubiX. While non-local reads are still faster when compared to reading from the cloud storage, they result in increased communication between worker nodes and impact performance when a large amount of data has to be transferred over the cluster network.
Presto provides a few ways in which locality can be prioritized while assigning data to workers:
- The property ‘force-local-scheduling’ forces Presto to always assign data splits to local worker nodes. It was observed that this could have a negative effect on performance if the distribution of data across workers is not uniform or if certain nodes are processing splits slower than the others. Both of these cases could result in certain worker nodes becoming performance bottlenecks.
- Presto has a Topology Aware Scheduler that relies on a hierarchy of network segments (such as workers at the rack level, etc.) and assigns splits based on the proximity of data to workers. In flat Topology Aware Scheduling, there is a single level of the hierarchy of network segments, and the locality of splits to each machine is given some preference. However, here, the locality is prioritized by reserving a certain number of slots for local splits in each worker. The reservation behavior depends on the initial distribution of data and on the order in which splits arrive for scheduling. At times this could result in the under-utilization of resources and could cause splits to be in the waiting state for longer periods.
Both options for locality-aware scheduling in Presto have certain associated drawbacks. Hence, there is a need for a better scheduler that takes the locality of splits into account when Presto is used alongside RubiX while maintaining uniform distribution.
Optimized Local Scheduling
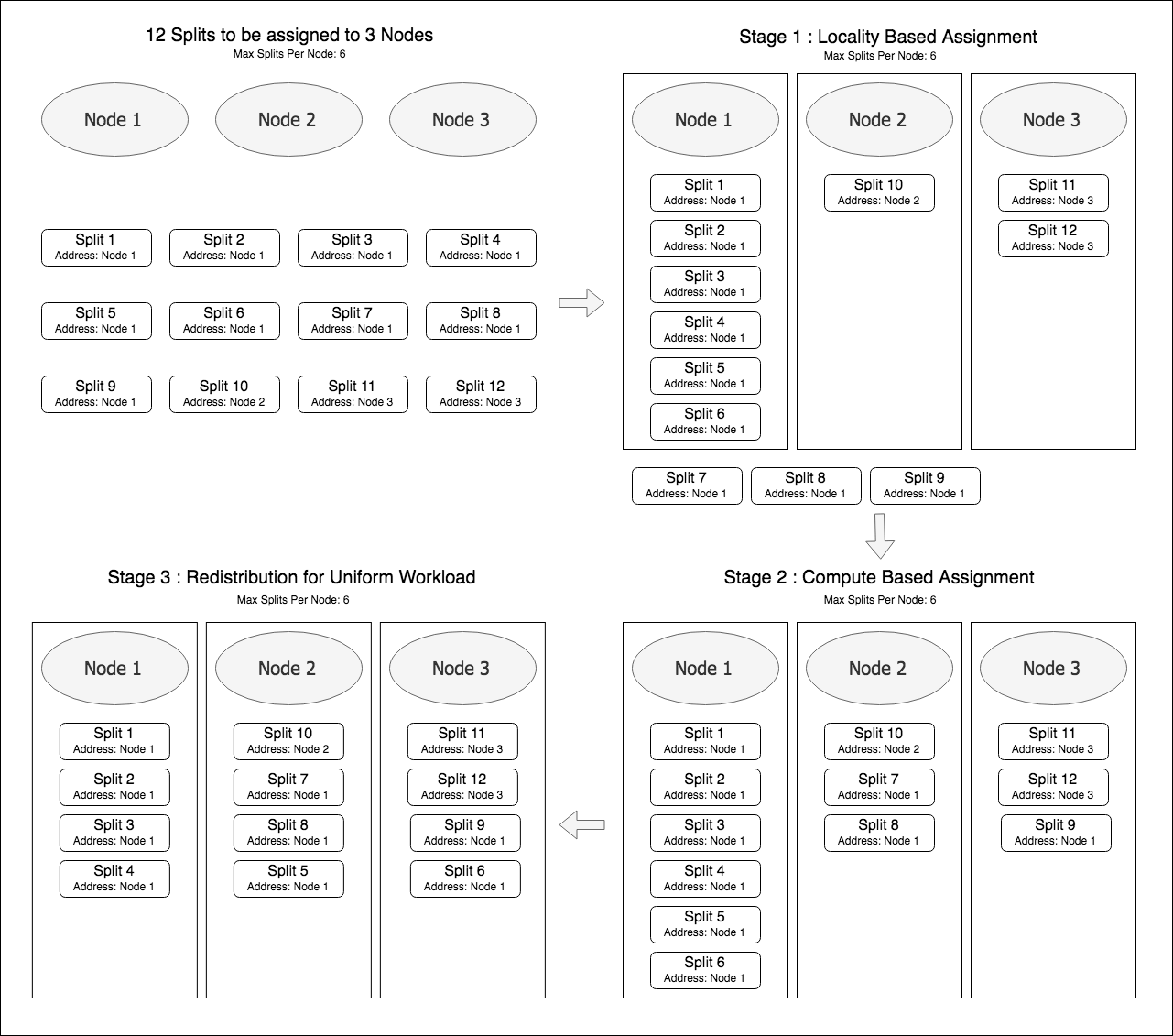
Qubole’s Optimized Local Scheduling is an improvement over the default Presto Scheduler. It follows a best-effort policy to assign splits to local nodes. The assignment of splits to worker nodes happens over three stages:
- The first stage is where locality is given priority. For a given query, if a split is local to any of the worker nodes, it is assigned to the same worker node.
- The second stage is applicable for those splits that were not scheduled in the first stage. This stage matches the default Presto scheduler behavior and assigns splits to nodes that have the most available free slots, thus helping to generate a more uniform distribution of splits.
- Splits are assigned in batches, and the third stage is responsible for ensuring that the distribution of splits is uniform. This stage redistributes splits from nodes that were assigned a large number of splits to those with fewer splits assigned. The redistribution of non-local splits is given preference. The third stage thus ensures that priority given to local splits is not at the cost of lower parallelism and that the worker nodes are uniformly loaded.
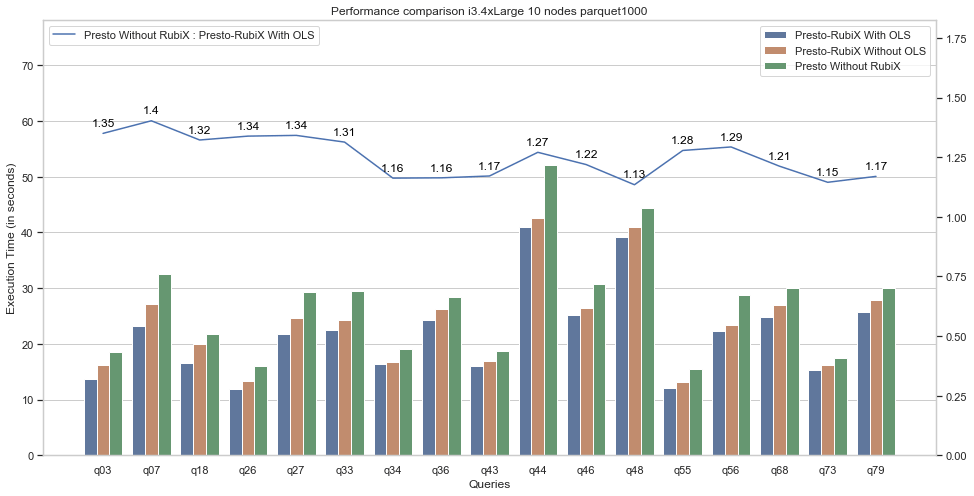
In our experiments, we found that Optimized Local Scheduling leads to improved query performance and also results in a much larger number of cached reads and fewer non-local reads as illustrated in the performance comparisons below.
Cache Statistics and Performance Measurements
To gauge the impact of Optimized Local Scheduling, 17 TPC-DS queries were executed on two Presto-RubiX clusters: one with Optimized Local Scheduling enabled and another with the property disabled. The rest of the configuration remained the same. The configuration of the clusters was as follows:
Presto version: 0.208
Cluster composition: 10 worker nodes (i3.4xLarge)
RubiX enabled: Yes
Custom overrides: join-distribution-type=BROADCAST
Data format: Parquet
Scale: 1000
The performance comparison was conducted on the Qubole Data Platform. Each query was executed thrice in succession. The best execution time and average local cache read value across the three trials were recorded.
We observed that Optimized Local Scheduling was able to boost RubiX runtimes, which were already an improvement over Presto runtimes. Presto runtimes decreased by an average of 25 percent with Optimized Local Scheduling, while the maximum improvement was around 40 percent.
Similarly, the RubiX execution time further decreased by an average of approximately 10 percent. The maximum improvement was approximately 20 percent. Optimized Local Scheduling led to improvements in execution times for all queries.
However, the most significant impact of Optimized Local Scheduling is on local cache reads. The plot below illustrates the local cache reads per worker with and without Optimized Local Scheduling.
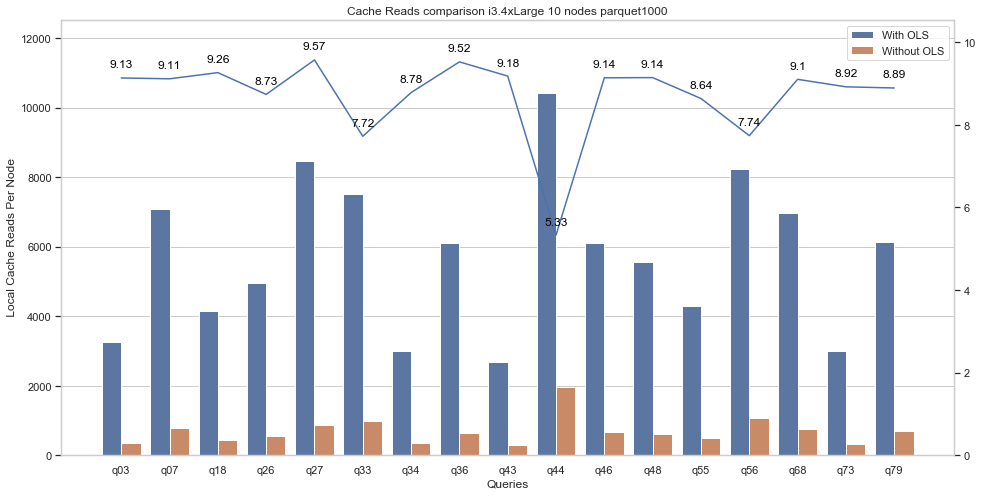
Optimized Local Scheduling led to a 9x increase in local cache reads on average. Non-local reads decreased proportionally. Decreasing non-local reads reduces network congestion by decreasing inter-node traffic, which leads to a network efficient deployment of RubiX on Presto. A similar significant increase in local cache reads can also be observed for the ORC format.
How to Enable Optimized Local Scheduling in Presto on Qubole
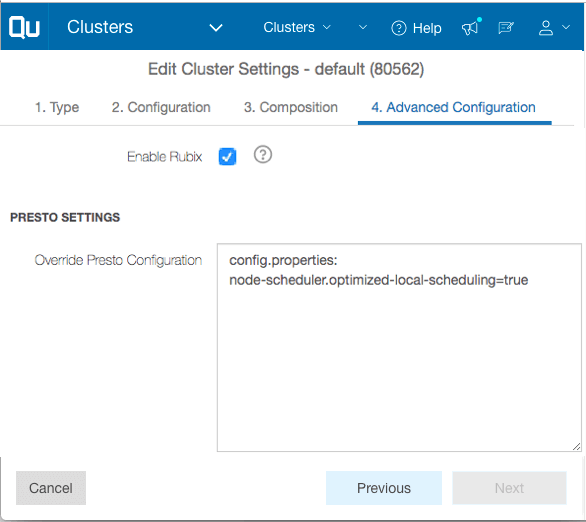
Optimized Local Scheduling is available for preview right now on request. Head to the Availability section below for details regarding general availability. To enable Optimized Local Scheduling in a Presto cluster, head to the Edit Cluster page and select the Advanced Configuration tab. Add the line ‘node-scheduler.optimized-local-scheduling=true’ under the ‘config.properties’ header in the Override Presto Configuration section and click on Update as shown below. A cluster restart is required for the configuration to take effect. Please note that Optimized Local Scheduling will not impact Presto clusters that do not have RubiX enabled.
Availability in Qubole and Open Source
Optimized Local Scheduling was proposed to open source Presto after the open-source community displayed interest in this feature. The new scheduling model has recently been added to the open-source Presto codebase and will be a part of the open-source Presto 315 release. The details of the implementation are available here.
Optimized Local Scheduling will be available in Presto on Qubole in the next major release, which is expected in the third quarter of 2019. It will be gradually made the default scheduling algorithm in all clusters in Qubole. If you want to try this out before general availability, reach out to us at [email protected] for a preview version.



