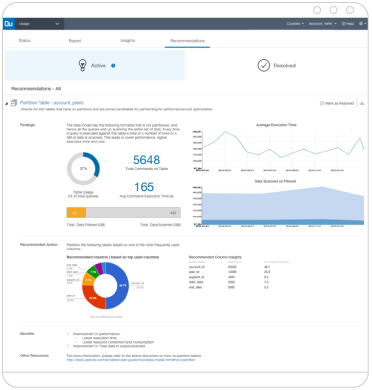
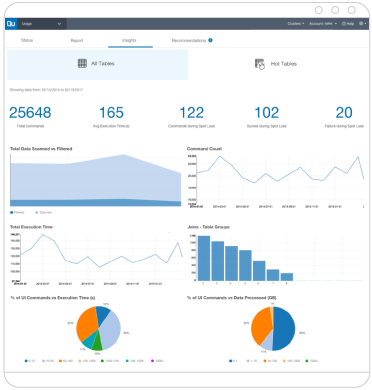
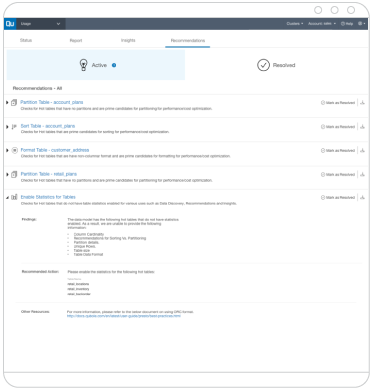
Leveraging big data is no longer a luxury. It’s necessary for survival. The question is how, when the hurdles—complexity, scalability, speed, cost,reliability, expertise—are many. The answer is the world’s first Autonomous Data Platformwhere metadata talks back and gives back.
Have you been dreaming of use cases limited only by your imagination? You’ve come to the right place. Our Autonomous Data Platform self-manages and self-optimizes by sending Alerts, Insights and Recommendations (AIR) based on Cloud Agents connected to your data team’s specific data policies and preferences.
Using a combination of heuristics and machine learning, AIR provides actionable alerts, insights and recommendations to ensure:
Workload continuity
High performance
Low reliance on Cloud resources
Greater cost savings
By automating lower-level, repetitive tasks, your engineering team can be less reactive to problems and more focused on directing better business outcomes. With AIR, QDS constantly analyzes metadata about infrastructure (cluster, nodes, CPU, memory, disk), platforms (data models and compute engines) and applications (SQL, reporting, ETL, machine learning) so you can better understand performance, usage patterns and Cloud spend.
Cloud Agents
Cloud Agents perform actions the data team determines. These typically include:
Executing automated tasks, based on a policy or configuration
Bundling specific low-level features
Learning based on individual, company and system-wide behavior
Cloud Agents are valuable to a data team because they:
Minimize resources consumed
Reduce costs
Automate repetitive, low-level activities
Increase productivity
Reduce custom development
QDS offers the following Cloud Agents:
Workload Aware Auto-Scaling Agent
Workload Aware Auto-Scaling Agent:
The Auto-scaling Agent augments the basic auto-scaling feature available in the Enterprise Edition with storage-based scaling and aggressive down-scaling.
The Workload Aware Auto-scaling Agent can reduce compute spend by as much as 33% over basic auto-scaling solutions available in the market today.
Workload Aware Auto-scaling offers the following capabilities:
HDFS-based
QDS continuously monitors the cluster’s HDFS storage to ensure it can support current jobs, and it will launch more nodes, if necessary.
EBS-based
When a cluster has sufficient compute resources but requires additional storage, the agent can dynamically add storage using EBS to avoid provisioning a new compute node.
Aggressive Downscaling
Aggressive downscaling is triggered when you reduce the maximum size of a cluster while it’s running. To save costs, QDS terminates nodes that are closest to completing their tasks and closest to their billing boundary.
Offloading
Your mappers may be running idly waiting for reducers to finish their job. Offloading conserves compute resources by saving mapper data to HDFS or object storage.
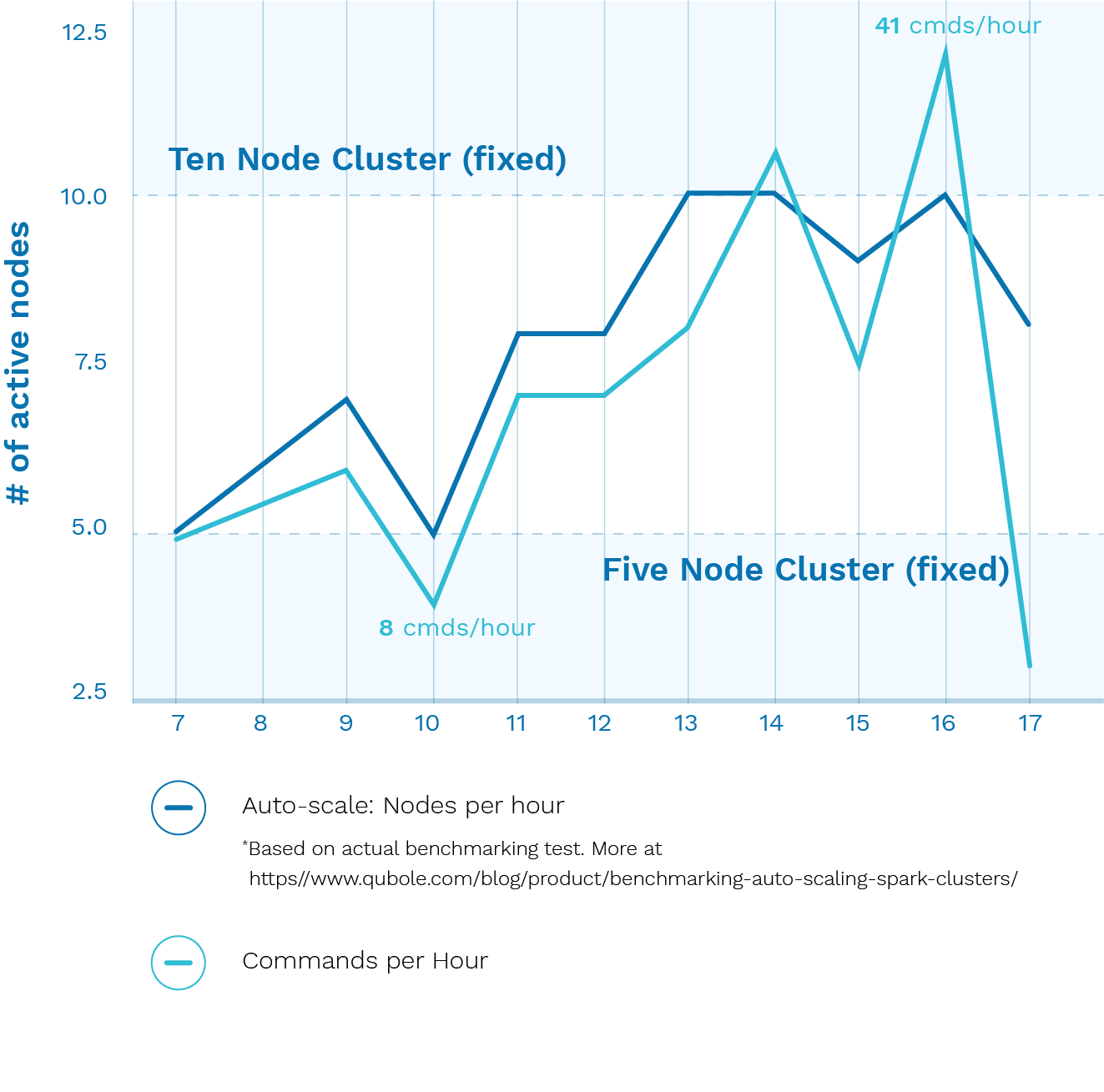
Qubole auto-scaling advantage
Comparing Qubole performance and cost against two fixed-cluster scenarios under typical fluctuating load conditions.
Scenario 1: Ten-node fixed cluster:
13% faster then QDS, but 32% more expensive
Qubole Data Service auto-scaling cluster:
Automatically optimizes performance and cost in response to elastic demand
Scenario 2: Five-node fixed cluster
10% cheaper than QDS, but 90% slower
Learn how much Workload Aware Auto-scaling can save you from our benchmarking analysis.
Spot Shopper Agent
The Spot Shopper Agent ‘shops’ for the best combination of price and performance, based on the policy you provide. It achieves this by shopping across different instance types, by dynamically rebalancing Spot and On Demand nodes and by considering different Availability Zones.
The Spot Shopper Agent can reduce compute spend by as much as 50% over solutions that exclusively rely on on-demand type instances.
Spot Shopper offers the following capabilities:
Heterogeneous Clusters
With Heterogeneous Clusters, slave nodes comprising the cluster may be of different instance types. Heterogeneity in Spot nodes is highly beneficial because Spot prices can change rapidly, and Spot Shopper can make the lowest-cost purchasing decision in real time.
Availability Zone selection
Unless you specify a particular AZ when you configure the cluster, Qubole can automatically select the AZ with the lowest Spot prices for the region and instance type you’ve specified.
Spot Rebalancing
Fluctuations in the market may mean that QDS cannot always obtain as many Spot instances as your cluster specification calls for. In these circumstances, the Spot Shopper Agent will automatically rebalance the cluster later on when prices drop by swapping out on-demand nodes for Spot nodes, ensuring that you continue to get the lowest prices possible [learn more].
Placement Policy
The Placement Policy option enables QDS to make a best effort to store one replica of each HDFS block on a stable node. This prevents job failures that could occur if all replicas were lost as a result of AWS reclaiming many Spot instances at once [learn more].
Data Caching Agent
The Data Caching Agent automates the movement of data for performance optimization.
Caching from Object Store
Data Caching automatically determines the right set of data to cache in the cluster so that interactive, ad-hoc queries run faster and don’t need to retrieve data for each query.
Caching of Index Metadata
Data Caching makes optimal use of ORC, Parquet and Avro data formats by minimizing the amount of data that’s read when selecting only specific columns.
START YOUR FREE TRIAL OF QUBOLE
Free access to Qubole for 30 days to build data pipelines, bring machine learning to production, and analyze any data type from any data source.