Open Data Lake Platform
- Home >
- Platform
An open and secure multi-cloud data lake platform for machine learning, streaming analytics, data exploration and ad-hoc analytics.










No other platform radically simplifies data management, data engineering and run-time services like Qubole. Qubole enables reliable, secure data access and collaboration among users while reducing time to value, improving productivity, and lowering cloud data lake costs from day one.
Ad-hoc Analysis
Develop and deliver advanced ad-hoc analytics to the team
With Qubole’s Workbench, author, save, template and share reports and queries. With optimized ANSI/ISO-SQL (Presto) service, built-in integrations with Tableau and Looker, and out-of-the-box Git integration share reports and queries with single click.


Data Pipelines
Collect and process stateful events, replay and reprocess data, and integrate with monitoring and alerting solutions.
With Qubole’s Assisted Pipeline Builder, you can build streaming data pipelines combining multiple streaming or batch data sources to gain real-time insights. Underlying fault-tolerant infrastructure ensures the accuracy and consistency of your data and results.
Machine Learning
Build, share and collaborate on machine learning and analytical models.
With Qubole platform’s offline editing, multi-language interpreter and version control capabilities deliver faster results. Leverage Qubole notebook to monitor application status, job progress, use the integrated package manager and visualize with Qviz
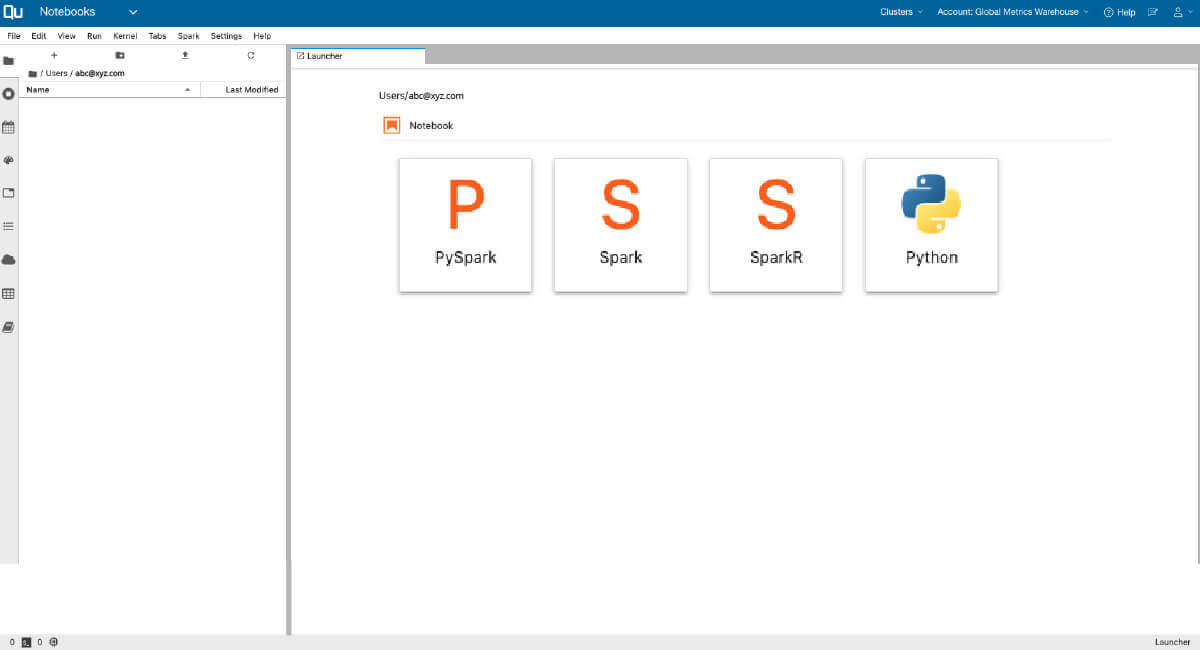
Data Engineering
Explore, build, and deliver data pipelines with ease.
With Qubole, automate end-to-end pipelines and avoid data ingestion and preparation bottlenecks and meet SLAs. Efficiently manage your data pipelines with the flexibility to use preferred programming language and data processing frameworks.
Data Management
Do faster data discovery, have quicker response time, and automated statistics collection.
With Qubole, you can build and manage metadata, discover and explore data dependencies, and provide indices and statistics to improve workload performance.
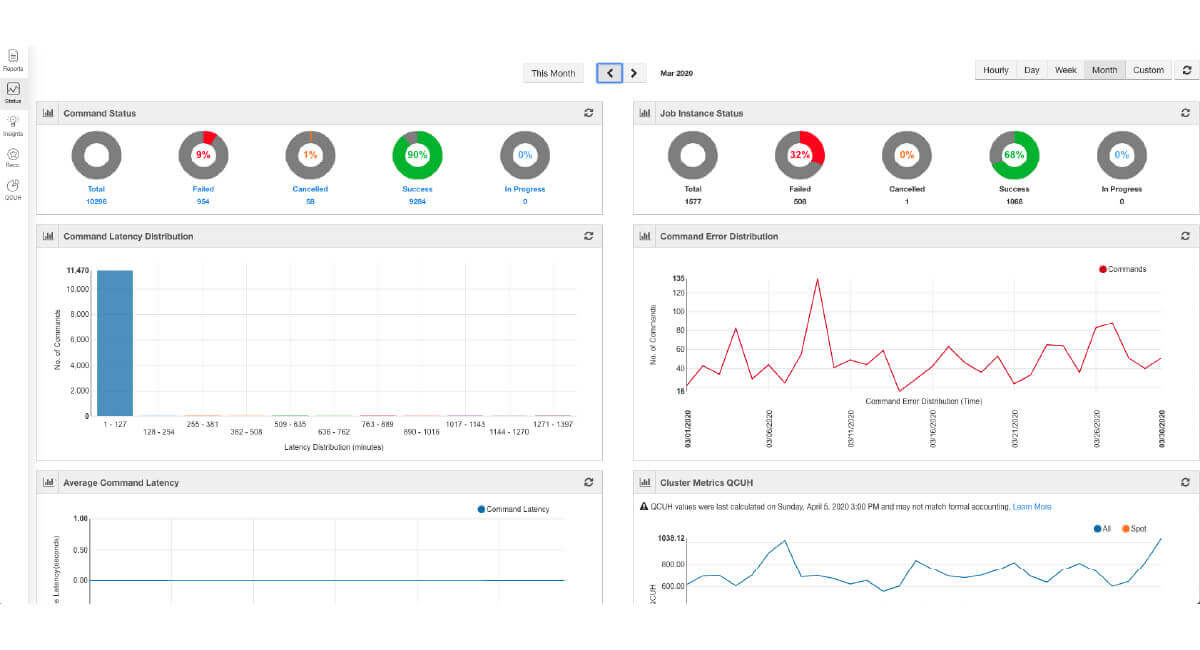
Platform Runtime
Automatically provision, manage, and optimize cloud resources balancing cost, workload, and performance requirements.
With Qubole, you can scale your compute infrastructure seamlessly on any cloud to accommodate new data and users without additional administrative overhead.
Security and Governance
Built-in multi-layer approach to protect the confidentiality, integrity, and availability of customer information.
Qubole provides ACID compliance based granular read/write data capabilities for regulatory compliance. Secure access with encryption and RBAC controls. Integrated with leading cloud provider IAMs, AD and LDAP implementations for the same data access privileges.

Our Unique Advantages

Open, Simple, Secure
Qubole delivers faster access to petabytes of secure, reliable and trusted datasets of structured and unstructured data for Analytics and Machine Learning. Users conduct ETL, analytics, and AI/ML workloads efficiently in end-to-end fashion across best-of-breed open source engines, multiple formats, libraries, and languages adapted to data volume, variety, SLAs and organizational policies.

Fast Data Lake Adoption at Scale
Qubole provides an out-of-the-box workbench and notebooks for data scientists, data engineers, data analysts, and administrators. It supports open source frameworks used by every type of data user including Apache Spark, Presto, Hive/Hadoop, TensorFlow, and Airflow.

Near Zero Administration
Qubole automates the installation, configuration, and maintenance of clusters, multiple open source engines, and purpose-built tools for data exploration, ad-hoc analytics, streaming analytics and machine learning. Organizations realize administrator-to-user ratios of 1:200 or higher and near-zero administration experience.

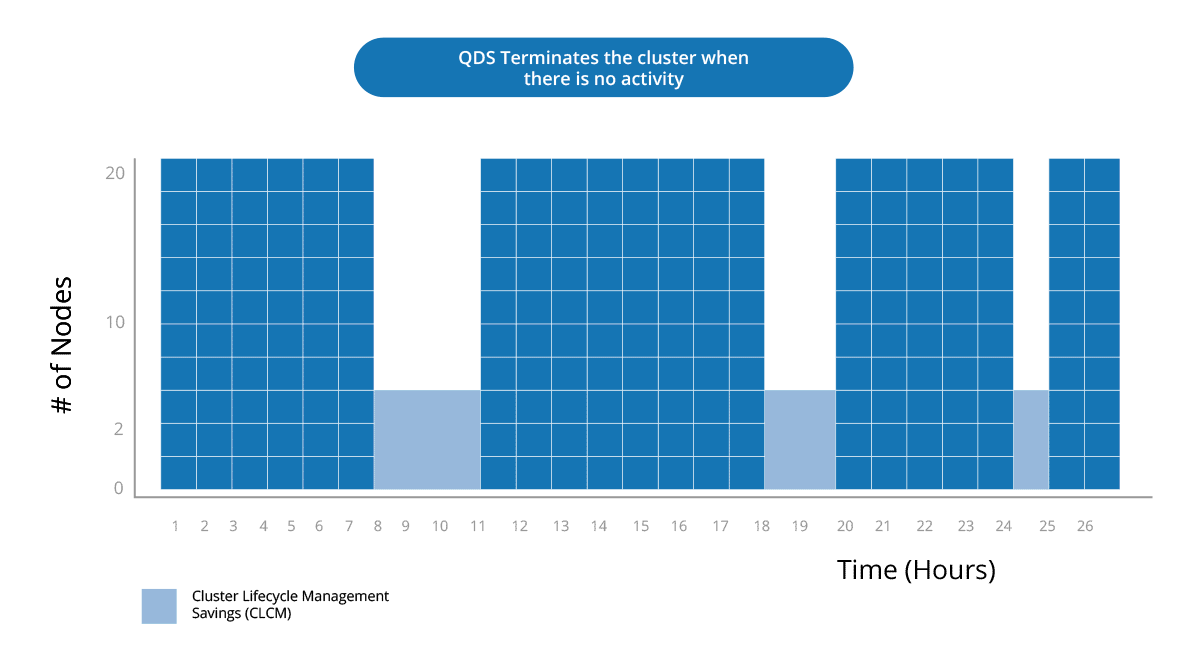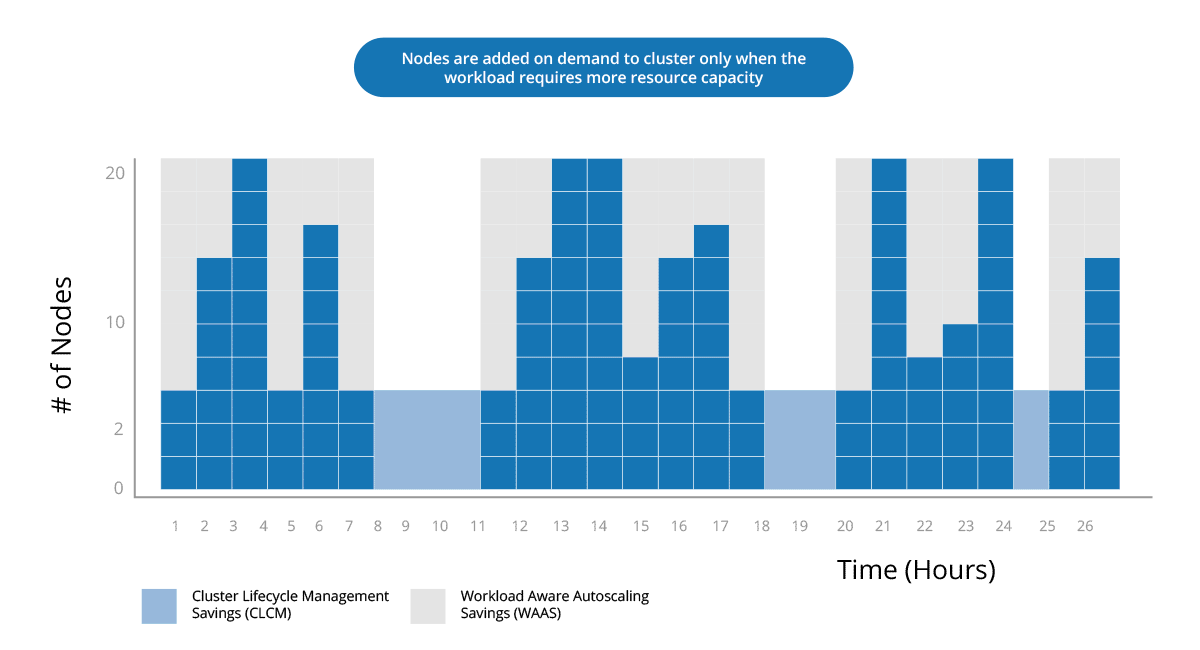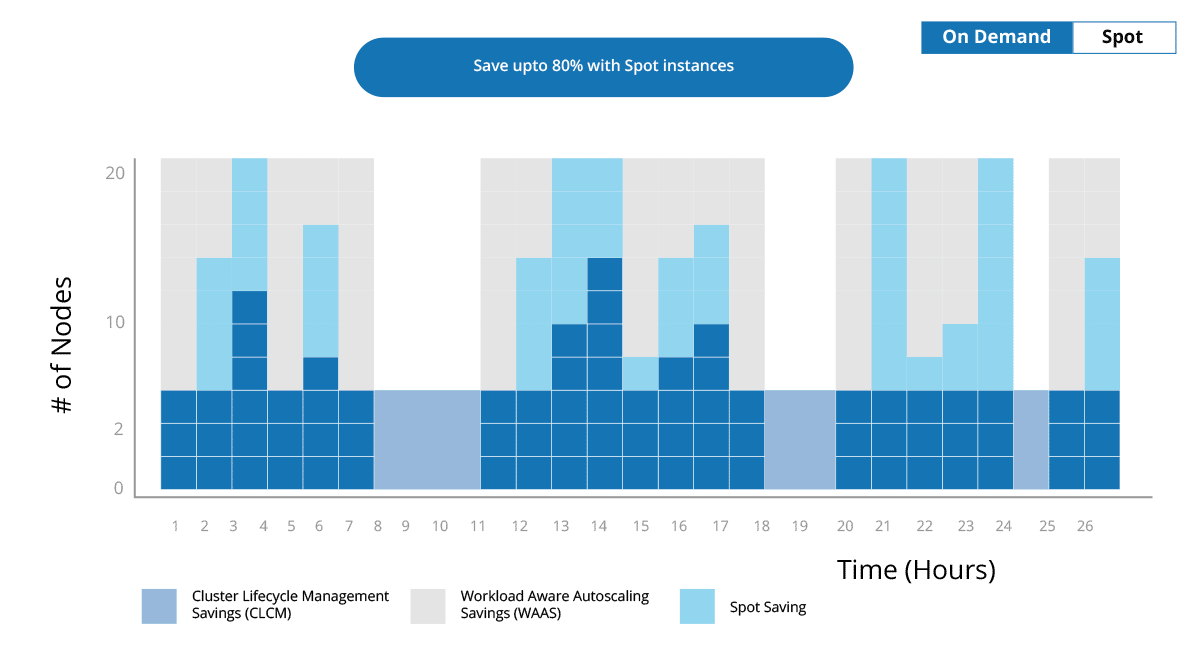
Reduce Data Lake Cost by 50%
Qubole’s Workload-aware autoscaling and real-time spot buying drives down compute costs dramatically. Pre-configured financial governance policies and built-in optimization lower data lake cloud computing costs continuously while providing administrator overrides to accommodate special needs.


