Structured Streaming (SS) is one of the core components of Apache Spark. As part of the Spark on Qubole offering, our customers can build and run Structured Streaming Applications reliably on the QDS platform. One of the most frequent issues with Structured Streaming was related to reliability when running it in a cloud environment, with some object store (usually s3) as checkpoint location. A Streaming Application would often crash with a File Not Found exception while performing the checkpoint operation. We noticed this is a common problem for a number of other users running Structured Streaming on the cloud (see StackOverflow question for more context) and decided to proactively address it.
In this post, we are going to discuss the issue in detail and share how we solved the problem for our customers running streaming and real-time workloads with Apache Spark on Qubole.
Checkpoint in Stream Processing: A Brief Introduction
Checkpointing is a mechanism to ensure fault tolerance and correctness in stream processing, especially in cases of failures and restarts. This is done by saving the metadata of the streaming application to a persistent store. This metadata can be used by the streaming engine to resume from the same point and state where it had been paused/stopped. Checkpointing is one of the key aspects of any reliable stream processing engine. Irrespective of whether a stream processing is stateless or stateful, the checkpoint mechanism is a must.
In Spark Structured Streaming, checkpointing is done via the following two operations:
- Saving offsets/commits by Driver:
The saving of information about incoming stream data by the Driver. In simpler words, the bookkeeping of how much data has been processed so far. It is required for Exactly Once Semantics ensured by Structured Streaming (E.g. saving Kafka/Kinesis offsets). - Saving state data by Executors:
The saving of information/state of processed data is needed for reliable stateful processing. This is done at the Executor level. (E.g. keeping aggregated count of incoming events).
For both of the above checkpoint cases, the system is usually configured to save the information to some distributed file system (or object store) like HDFS, S3, Azure Blob, etc.
Code Sample:
val query = df.writeStream.queryName("AggregationExample")
.format("memory").outputMode("complete")
.option("checkpointLocation","s3://<bucketPath>/<checkpointDirectory>")
.start()Eventual Consistency (EC) Issue with Checkpointing in Structured Streaming:
In Structured Streaming, the checkpoint mechanism has been implemented for an HDFS-compliant file system. Object stores like S3 are not HDFS-compliant and have completely different fundamental properties. Eventually, the consistent nature of such object stores can lead to frequent Streaming application failure when used as the checkpoint location under current open-source Checkpoint implementation. (Refer here for more discussion around this issue.)
The way the open-source implementation of Checkpoint currently works is:
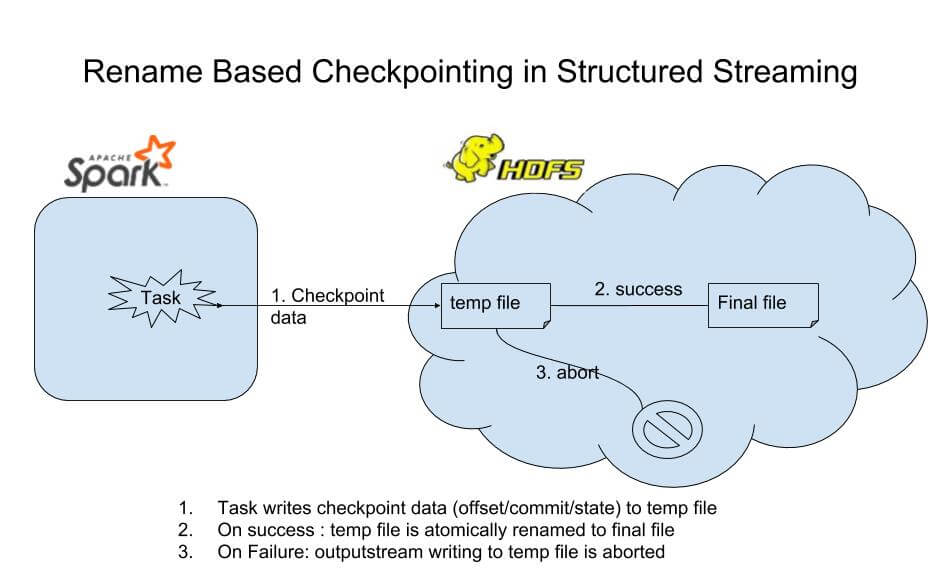
- Checkpoint data (offsets/commits/state) is first written to a temporary file in the file system (or object store). This is done by the driver or an executor task.
- Once the data is completely written, the temporary file is then renamed to the expected file name as part of the commit operation.
This approach is called Rename-Based Checkpointing.
This is a perfectly suitable approach when using HDFS because:
- Writing data directly to the final file should not be done as an intermediate flush/sync operation can make the file visible in the file system while the associated task writing to it is still running and has yet to succeed/abort. This can result in an inconsistent view of checkpoint files in the file system.
- Renaming a file in HDFS is an atomic operation (a synchronized metadata change operation in HDFS namenode). This means we can keep writing intermediate data to a temporary file. If the task succeeds, atomically rename the file. If the task fails, just delete the temporary file — thus atomic visibility of the final file in the file system is ensured.
However, object stores like S3 have different properties and the above points do not hold true.
Few important properties of S3 Object Storage that are worth noting:
- S3 guarantees that any object will be available for reading, only when the write is 100% complete. In case the write operation gets aborted in between, no inconsistent data will be visible in the S3 store.
- Renaming a file in the S3 object store is not an atomic operation. The way Rename works are: it creates a new file, copies content from the old file to a new file, and then deletes the old file. It is a costly operation: O(data).
- Most importantly, due to the Eventual Consistency behavior of S3, internal file operations like rename/list during Checkpointing results in runtime exceptions like FileNotFound/IllegalState. This leads to frequent application failures.
Due to the above limitations, Rename-based Checkpointing in Structured Streaming with an object store is both inconsistent as well as inefficient.
Solving the EC Issue with Direct Write Checkpoint in Structured Streaming:
Before 2.4.0, the Checkpoint abstraction in Apache Spark codebase was not extensible enough to support any new custom implementation. In a recent improvement released in Spark 2.4.0 ( SPARK-23966), Checkpoint code has undergone significant design changes and a new extensible abstraction has been introduced. The current default implementation of the abstraction still follows the Rename-Based approach (suitable for an HDFS-complaint system). But the abstraction makes it easier to extend and write custom implementations as and when required.
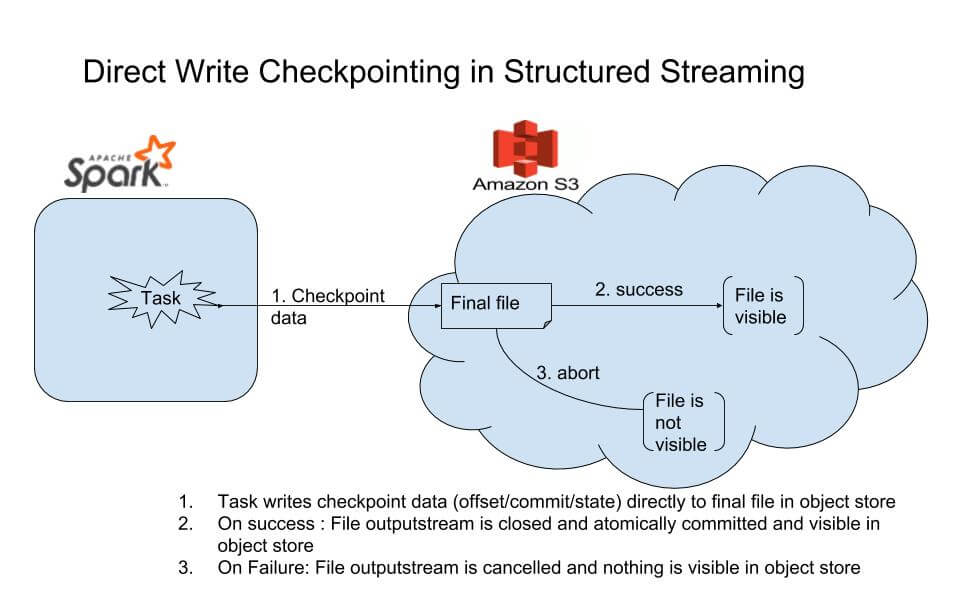
At Qubole, We have extended the above abstraction and implemented different checkpoint logic for S3/object-store. In this approach, instead of writing checkpoint data first to a temporary file, the task writes the checkpoint data directly to the final file. We call it Direct Write Checkpointing.
Once writing data to the file is complete, the associated output stream is closed. S3 guarantees that a file is visible only when the output stream is properly closed. This way the rename operation is avoided, therefore ensuring there is no file listing call while writing data and no consistency issue. Also, it is more efficient as copying the entire content from one file to another file is also avoided.
However, the challenge in this approach is handling the situation when the task gets aborted in the middle of writing checkpoint data to the S3 file. In this scenario:
- If the output stream is closed, partial data will become visible in S3 which will be incorrect and unacceptable.
- If the output stream is not closed, then the file system port will remain open. The number of open ports will increase over time with aborted tasks, which is also not acceptable.
To handle this situation, we take an approach so that there are no side effects of task failures. In the case of failure/abort:
- The output stream is closed. This way no port remains open.
- The file generated from the above step is deleted right away after closing the stream to avoid making it visible. In some cases, this can result in a possible EC issue (such as FileNotFound). We applied a retry logic of attempting multiple times (with configurable increasing time gaps up to certain limits) to ensure deletion is successful. This way both correctness and performance are ensured in the majority of cases. Note that the approach is still on the best effort basis. In a very rare case, if deletion does not succeed until the configured limit because of EC, we let the application crash so that the user can take appropriate action. This ensures that the correctness is not impacted.
Summary:
Checkpointing in Object Stores like S3, Azure, etc. is a primitive requirement for running streaming workloads in the cloud. The EC issue with the current open-source implementation makes it difficult to productionize and run Structured Streaming applications reliably on the cloud.
At Qubole, we have implemented Direct Write Checkpointing for object stores, which ensures correctness as well as performance. The above solution is available in Qubole’s offering of Apache Spark version 2.3 and onwards. There are many more exciting functionalities and enhancements that we are continuously working on in order to make our streaming customers’ lives easy. You can also check out this blog on how to get started with Structured Streaming on Qubole with Amazon Managed Kafka.
Test drive Qubole today to try Apache Spark on Qubole yourself.



