AWS recently announced Managed Streaming for Kafka (MSK) at AWS re:Invent 2018. Apache Kafka is one of the most popular open source streaming message queues. Kafka provides a high-throughput, low-latency technology for handling data streaming in real time. MSK allows developers to spin up Kafka as a managed service and offload operational overhead to AWS.
In this post, we will demonstrate how you can quickly build a stream data processing pipeline using Amazon MSK with Apache Spark Structured Streaming on Qubole. We will walk through the minimal setup steps and provide a working code example with detailed explanation.
Amazon MSK + Spark Streaming on Qubole
Prerequisite Steps:
First, you must execute a few steps to set up a Kafka cluster in AWS MSK:
- Create VPC for MSK cluster:
https://docs.aws.amazon.com/msk/latest/developerguide/create-vpc.html - Enable HA and fault tolerance for Kafka:
https://docs.aws.amazon.com/msk/latest/developerguide/add-subnets.html - Create Kafka cluster:
https://docs.aws.amazon.com/msk/latest/developerguide/create-cluster.html - Create Kafka topic:
https://docs.aws.amazon.com/msk/latest/developerguide/create-topic.html
See AWS documentation for MSK for detailed information.
After the above steps, we will have a Kafka cluster ready in Amazon VPC.
Important Information:
We need a few details from the above setup, which will be used to connect Spark on Qubole with MSK:
- VPC name (e.g. quboleMskSampleVPC )
- VPC ID (e.g. vpc-0e0e80……… )
- VPC security group ID (e.g. sg-0b08……….. )
- VPC security group name (e.g. default )
- Kafka topic name (e.g. quboleMskSampleTopic )
- Zookeeper Info of Kafka Cluster (e.g. “ZookeeperConnectString”: “10.0.0.254:2181,10.0.2.85:2181,10.0.1.110:2181”).
This can be fetched using command:
aws kafka describe-cluster –cluster-arn <clusterArn>
Refer to this AWS documentation for more detail. - Broker Info of Kafka Cluster (e.g. “BootstrapBrokerString”: “10.0.0.59:9092,10.0.1.86:9092,10.0.2.68:9092”)
This can be fetched using the following command:
aws kafka get-bootstrap-brokers –cluster-arn <clusterArn>
Refer to additional AWS documentation for more details.
Now that we have our environment configured and ready, use the following steps to build a Spark structured streaming application on top of MSK using Qubole Notebooks:
- Login into your Qubole account
- Go to the clusters page. Create a new Spark cluster or edit an existing cluster using the configurations below:“Advanced Configuration” tab -> “EC2 Settings”:
Enter the MSK VPC value (i.e. quboleMskSampleVPC ) in the VPC field. Choose any of the subnets from the VPC in subnet field.  Click on the “Update” button to update cluster settings.
Click on the “Update” button to update cluster settings.- Get the Security Group name of the Spark cluster (e.g. sc-qa3_qbol_acc2345_……). Go to “Security Groups” in the AWS console and search for the security group for Kafka VPC (with vpc id):
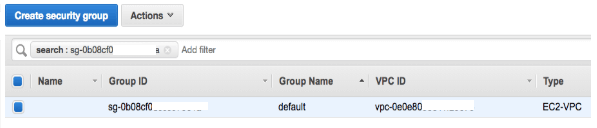
 Edit “Inbound Rules”: Add a new entry for the security group to the Spark cluster to allow all Traffic.*
Edit “Inbound Rules”: Add a new entry for the security group to the Spark cluster to allow all Traffic.*
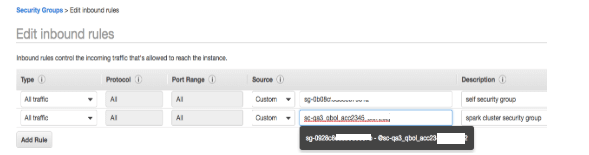
*This is required for the Spark cluster to send/receive data from the Kafka cluster in AWS VPC and is similar to this step in the AWS guide.
- Start the cluster, wait until it is up and running.
- Create a new notebook in Qubole, and associate it with the newly created cluster. Now add and run the following Scala paragraphs one by one in the notebook.
Define MSK/Kafka parameters with values from the “Important Info” section. We only need to get information about Kafka brokers and Kafka topics to start processing.
1. AWS MSK params
val topics = "quboleMskSampleTopic" val brokers = "10.0.1.86:9092,10.0.0.59:9092,10.0.2.68:9092"
Now, write Spark streaming code to process the data. Also, add a Kafka producer utility method to send sample data to Kafka in Amazon MSK and verify that it is being processed by the streaming query.
In our example, we have defined that incoming data from Kafka is in JSON format and contains three String type fields: time, stock, price.
We will extract these fields from the Kafka records and then aggregate over to the stock field to find the number of records per stock.
2. Code for Structured Streaming and Kafka Producer
import sys.process._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming._
import org.apache.spark.sql.types._
import org.apache.kafka.clients.producer.{ProducerConfig, KafkaProducer, ProducerRecord}
import java.util.HashMap
object QuboleKafka extends Serializable {
val topicMap = topics.split(",").map((_, 4)).toMap
val topicToSend = topics.split(",")(0)
val group = "group"
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
@transient var producer : KafkaProducer[String, String] = null
var messageId : Long = 1
@transient var query : StreamingQuery = null
val spark = SparkSession.builder.appName("MSK streaming Example").getOrCreate()
import spark.implicits._
def start() = {
//Start producer for kafka
producer = new KafkaProducer[String, String](props)
//Creare a datastream from Kafka topics.
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", brokers)
.option("subscribe", topics)
.option("startingOffsets", "latest")
.load()
df.printSchema()
// define schema of data
val schema: StructType = new StructType().add("time", "string").add("stock", "string").add("price", "string")
// covert datastream into a datasets and apply schema
val ds = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as[(String, String)]
val output = ds.select(from_json($"value", schema).as("data")).select("data.*").groupBy("stock").count()
output.printSchema()
output.explain(true)
// write stream to sink
val query = output.writeStream.queryName("AggregationExample")
.format("memory")
.outputMode("complete")
.option("checkpointLocation", "/tmp/test")
.trigger(Trigger.ProcessingTime("1 seconds"))
.start()
}
// Send message to kafka
def send(msg: String) = {
val message = new ProducerRecord[String, String](topicToSend, null, s"$msg")
messageId = messageId + 1
producer.send(message)
}
}Next, we will start the streaming query :
3. Start streaming
QuboleKafka.start
We can also send some sample data into Kafka brokers in the expected JSON schema format by running a Kafka producer in the notebook to verify the streaming query is processing Kafka data correctly:
4. Send data to Kafka
val input: String = "{\"time\":\"1545342455623\",\"stock\":\"fb\",\"price\":\"400.0\"}"
QuboleKafka.send(input)Verify the processed data:
5. Verify output of streaming query
spark.sql("select * from aggregationExample limit 10").show()Lastly, stop the streaming query:
6. Stop streaming
spark.stop
We can restart the query again by starting from Paragraph 2. It will resume with the same state of data from where it left off using the checkpoint location.
The complete code for the above notebook example can be found here.
Conclusion
Qubole provides excellent support for running Spark Structured Streaming jobs on AWS. Learn more about in our Spark Streaming on Qubole webinar. It is very easy to quickly integrate Spark Structured Streaming on Qubole with AWS MSK, as shown above, to continuously process streaming data in near real time.
Start a free trial to get started.



