Running Hadoop clusters efficiently is an important customer use case at Qubole. When running in AWS, this often means using Spot instances efficiently. In this post, we introduce the notion of Rebalancing Hadoop clusters to achieve a higher mix of Spot instances – while still maintaining reliability and meeting SLAs.
Spot Instances
At Qubole, many of our customers run their Hadoop clusters on AWS because of the compelling advantages it provides as a leading Cloud Services provider. One of the unique 1 features that AWS offers is Spot Instances, which are spare EC2 instances where the price is set in real-time based on supply and demand. Spot instances operate on a bid-based system where the user bids the maximum that he’s willing to pay for the instance, and if the current Spot price is less than that, the instance is granted to him/her. This can give the user very significant cost savings – especially when running large Hadoop clusters. This is in contrast to the On-Demand instances for which the user pays a fixed, pre-determined price for every hour of usage. For example, the graph below lists the Spot price for m3.xlarge nodes in the us-east-1 region from 28th April – 6th May 2015. One can see that the price has, by and large, been in the range of ~ $0.03 per hour, which is nearly a 90% discount from the on-demand price ($0.280) of the same instance type.
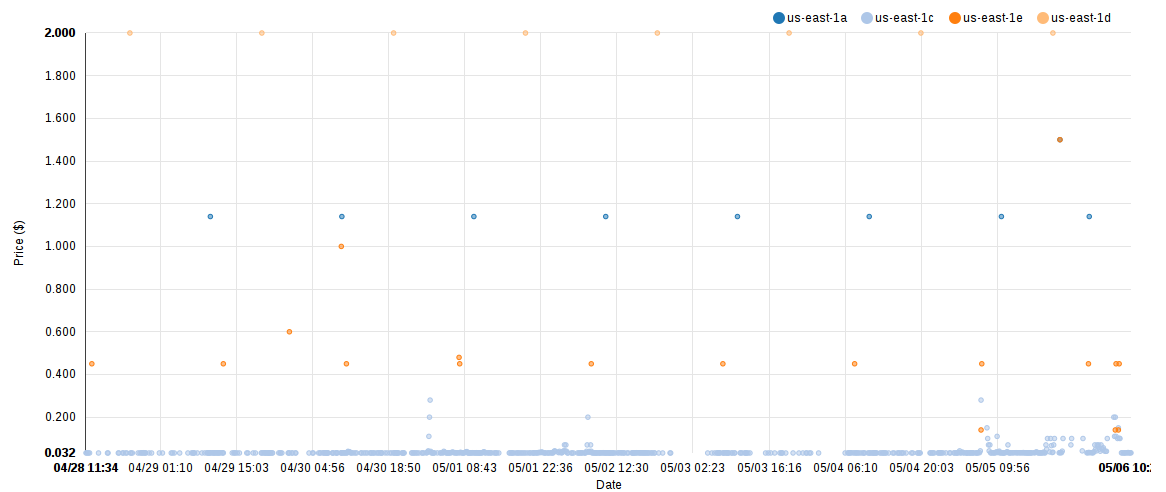
EC2 m3.xlarge Spot Price History 04/28/2015 – 05/06/2015 (image courtesy ec2price.com)
However, like all good things in life, Spot instances do come, for lack of a better phrase, at a price:
- AWS can take the instance away at any time
- If the demand for the Spot instance increases and the Spot Price exceeds the bid price, the Spot instance will be terminated. One way to reduce the probability of this is to use higher bid prices.
- Even with very high bid prices, the instance will be terminated if AWS can no longer spare instances of a specific type.
- There is no guarantee that the Spot instances requested will be granted – if the current Spot price exceeds the bid price, or there is not enough spare capacity, the Spot instance request will be rejected. This is very unlikely with On-Demand instances.
- Spot instances are slow to be granted. Whereas On-Demand instances will be granted almost instantaneously, Spot instances can take several minutes.
Autoscaling Clusters in Qubole – A Recap
Qubole’s unique autoscaling feature enables clusters to start out small and then scale up when the load on the cluster increases. At a high level, each cluster is composed of:
- A minimal set of Core nodes. The cluster starts up with this many nodes, and even when downscaled, does not reduce below this many. For the purposes of this post – we will assume that these are On-Demand nodes.
- A set of Auto-Scaled nodes, which are added when the load on the cluster increases, and are removed when the cluster is comparatively idle. These nodes can be On-Demand instances, Spot instances, or a mix.
Qubole-managed Hadoop clusters tightly integrate Spot instances. One can configure a mix of On-Demand and Spot instances for Auto-Scaled nodes – or go for a 100% Spot or 100% On-Demand composition. A modified HDFS block placement algorithm is used to force placement of one block replica on On-Demand instances – thereby providing a reliable cluster even when Spot price spikes happen. If Spot instances are not available – Qubole’s clusters can when upscaling, fall back to using On-Demand instances. This ensures that the workload completes within a reasonable time, while still making the best attempt to reduce costs by trying to use spot instances when available.
Issues with Falling Back
One issue with falling back to On-Demand instances is that these instances will continue to be used as long as the cluster is busy, thus driving up the cost of the cluster. In the worst-case scenario, the entire cluster could be composed of just On-Demand instances. And it will continue to be so until the cluster is either downscaled (and then up-scaled again) or terminated. In practice though, we have seen the worst-case materialize only for clusters that run hot for a long time. These are a small fraction of the overall usage in Qubole.
In the past, when we have encountered a use case that hits the worst-case scenario, we have worked around by creating a cluster with:
- A relatively large number of Core (On-Demand) nodes (sufficient for running the workload)
- Some additional Auto-Scaled nodes configured in 100% Spot mode
- Fallback disabled
This is, however, not the best configuration from a cost point of view. The user would want to keep the number of On-Demand instances as low as possible while still availing the benefits of the fallback option. The chart below depicts a hypothetical 100-node cluster with such ideal, worst-case, and current scenarios.
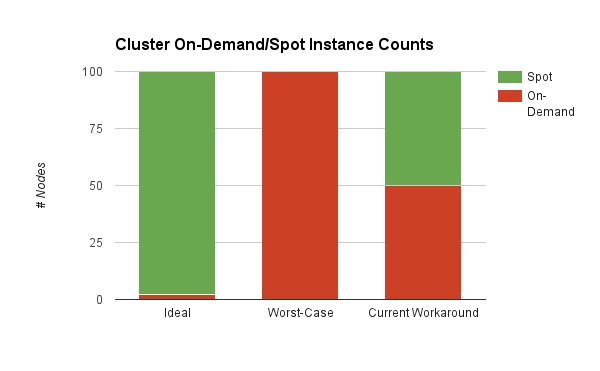
On-Demand/Spot Instance Ratio – various configurations – in a hypothetical 100-node cluster
Node Rebalancing
Qubole clusters now have the ability to rebalance the cluster when the number of On-Demand instances in the Auto-Scaled nodes exceeds the ratio requested by the user. At a high level, this works by swapping out On-Demand instances for Spot instances at opportune moments when the Spot instance availability is higher. This is a multi-step process where the cluster will automatically:
- Identify On-Demand instances that are not heavily occupied in performing tasks or holding too much state – such instances are good candidates for being swapped out
- Provision Spot instances from the AWS market, if available, and
- Initiate termination of the On-Demand instances identified in Step 1
Over time, this self-healing process can drive the cluster from even the worst-case configuration to one that is composed of a healthy mix of On-Demand and Spot instances. This ameliorates the risk of running a cluster with a very small number of On-Demand nodes and enables the customer to use the ideal configuration discussed above. The customer can rest easy in the knowledge that any excess On-Demand nodes will either be removed (due to downscaling) or replaced due to rebalancing.
Map-Output Offloading
One of the issues in removing nodes from running Hadoop clusters is that, aside from running workloads, nodes are also stateful. HDFS state is easy to handle – Qubole makes sure that HDFS data resident on a node is safely backed up before removing it. And this process usually does not take a long time. However, nodes can also hold and serve map-outputs of currently running jobs. Removing such nodes is difficult, as Hadoop responds by re-running all the lost mappers. As such it is not feasible to remove nodes containing map outputs. This means that a single long-running job can obstruct the process of rebalancing.
In order to get around this problem – we have introduced an optional feature to backup map outputs to AWS S3 when performing rebalancing. If we detect that a node is holding map-output for some jobs and that these jobs have finished shuffling data (i.e. the map-output is likely not to be required in the future), then we can back up the map output to S3 and remove the node safely. If in case the map-output is required in the future, Reducers are redirected to the backed-up copy on S3. If this feature is enabled, long-running jobs can no longer obstruct rebalancing.
Managing rebalancing frequency
Over the normal course of a cluster’s lifetime, the On-Demand to Spot instance ratio can get skewed for two reasons:
- We were unable to provision Spot instances during upscaling, or
- We terminated more Spot instances than On-Demand instances when downscaling.
Qubole’s downscaling is aggressive in terminating nodes. If we find that a node is idle at its hour boundary, it will be terminated. This results in maximal cost-saving for our customers, but the downside is that we may sometimes remove many more Spot instances than On-Demand instances because not enough on-demand instances were idle. At this time, if we attempt to rebalance the cluster, we may cause a vicious circle of downscaling-rebalancing events. To prevent such cycles, we attempt rebalancing only if the ratio has been bad for at least an hour. This ensures that rebalancing kicks in only on the sustained imbalance in the Spot/On-Demand ratio – and not because of temporary blips that happen due to regular scaling activities.
Managing the cluster size
When provisioning new spot instances to rebalance the cluster, the number of nodes in the cluster may temporarily exceed the maximum cluster size specified by the user. The number of new nodes that can be provisioned is, therefore, restricted to ensure that the size of the cluster does not exceed a certain percentage (10% by default) of the specified maximum. This can be overridden by the user. A higher percentage can allow the software to rebalance nodes faster when Spot instances become available.
Using Node Rebalancing
Node rebalancing is enabled on Qubole clusters running Hadoop-1 (and is in the process of being adapted to Hadoop-2 and other cluster types). Please get in touch with us if you would like to know more about rebalancing and other aspects of Qubole clusters.
We are also hiring and looking for great programmers to help us build stuff like this and more. Drop us a line at [email protected] or head to our Careers page for more details.



