In this blog post, we will talk about Deep Learning (DL) in relation to data science: its use and business implications. We will then give an overview of the R&D efforts that Qubole is conducting in this area with respect to GPU support and distributed training.
Artificial Intelligence and Machine Learning
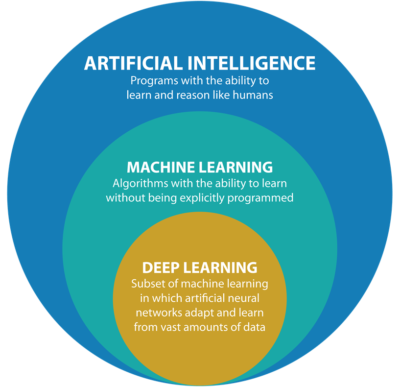
The last few years have seen considerable interest in Artificial Intelligence (AI) and Machine Learning (ML), specifically in the area of deep learning. These terms are used interchangeably and very often confused with each other. Let’s take a look at the relationship between these technologies and the reason for the popularity of DL.
Artificial intelligence refers to a set of technologies that allow machines — computers or robotic systems — to process information the way humans would. The current resurgence of AI is arising from weak or narrow AI, which is a machine that can do specific tasks intelligently, e.g. self-driving cars, detecting fraud, or understanding human text and speech. We are still far away from strong AI, which refers to the ability of machines to make causal inferences about the world without any past observations (See this article from The Atlantic for more details).
A key building block of a narrow AI system or software is the ability to learn from past occurrences, i.e. historical data. Machine learning is the process of programming computers to learn from historical data, and practitioners use a combination of computer programming and statistical techniques to create software models that learn from historical data to make predictions on new data.
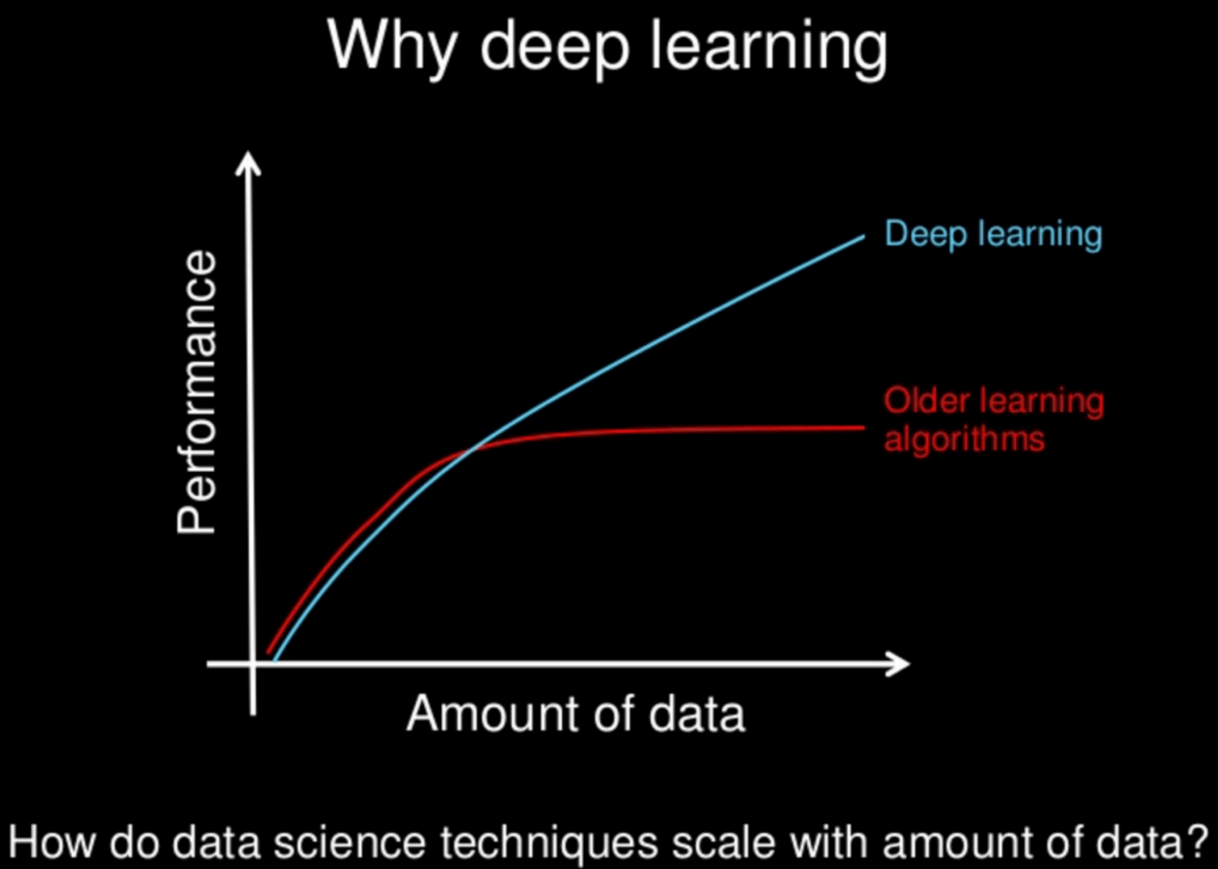
DL is a subset of machine learning that operates on large volumes of unstructured data such as human speech, text, and images. A deep learning model is an artificial neural network that comprises multiple layers of mathematical computation on data, where results from one layer are fed as inputs into the next layer in order to classify the input data and/or make a prediction.
DL is not a new field; in fact, many of these algorithms have been around for the last 50-plus years. The availability of and ability to process large datasets has resulted in a renewed commercial interest in deep learning due to its ability to train large datasets.
Typical Use Cases For Deep Learning
A few examples of tasks accomplished with DL are speech to text transcription, voice identification, image classification, facial or object recognition, analysis of sentiment or intent from text, etc. These lead to a variety of use cases: self-driving cars where input from the car sensors is processed to detect objects in front of the car, understanding user sentiment in an email or chat interaction, analyzing thousands of transactions to detect fraudulent transactions, and more.
Qubole Deep Learning Clusters
Qubole offers a deep learning cluster on Amazon Web Services (AWS)**. With this product we are providing our customers with two key features:
- Graphics Processing Unit (GPU) support
- Distributed training
GPU Support
Compiling TensorFlow (TF) and Keras with appropriate GPU drivers and libraries such as cuDNN and CUDA toolkit is very time-consuming and is not something data scientists want or should do. Our engineering team has spent a lot of time compiling the required versions matching the hardware of the machines available in AWS (Azure support is coming soon).
We currently support all AWS GPU instances available (p2, p3, and g3):
| Model | # of GPUs | # of vCPU | Mem (GB) | GPU Mem (GB) | GPU Card |
| p3.2xlarge | 1 | 4 | 61 | 16 | NVIDIA Tesla V100 |
| p3.8xlarge | 4 | 32 | 244 | 64 | NVIDIA Tesla V100 |
| p3.16xlarge | 8 | 64 | 488 | 128 | NVIDIA Tesla V100 |
| p2.xlarge | 1 | 4 | 61 | 12 | NVIDIA K80 |
| p2.8xlarge | 8 | 32 | 488 | 96 | NVIDIA K80 |
| p2.16xlarge | 16 | 64 | 732 | 192 | NVIDIA K80 |
| g3.4xlarge | 1 | 16 | 122 | 8 | NVIDIA Tesla M60 |
| g3.8xlarge | 2 | 32 | 244 | 16 | NVIDIA Tesla M60 |
| g3.16xlarge | 4 | 64 | 488 | 32 | NVIDIA Tesla M60 |
GPUs are an option to shorten the training time of deep learning models. Depending on the usage and the GPU card used, GPUs can be 50x to 1,000x times faster than CPUs for floating-point operations, such as matrix multiplication. Matrix operations are at the core of solving optimization problems to estimate coefficients in these types of models.
We ran a test on a Qubole deep learning cluster using a p3.2xlarge instance (NVIDIA Tesla V100) to understand the performance gain of using GPUs when training models on a single processing unit. By increasing the size of a randomly generated matrix in discrete steps and running a tf.matmul (matrix multiplication) with devices “/gpu:0” and “cpu:/0”, we kept track of the time that the operation takes with CPU vs GPU:
import tensorflow as tf with tf.device(device_name): r1 = tf.random_uniform(shape=shape, minval=0, maxval=1, dtype=data_type) r2 = tf.random_uniform(shape=shape, minval=0, maxval=1, dtype=data_type) dot_operation = tf.matmul(r2, r1)
Here is the result:
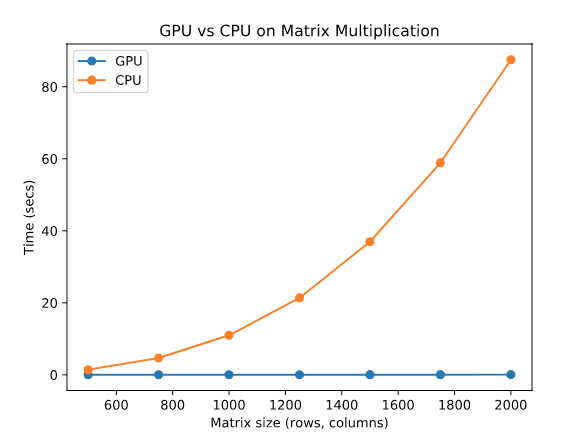
We see how the CPU computation time increases much faster than the GPU computation time. If we take the ratio of the time of CPU computation to the time of GPU computation, we obtain how many times faster the GPU is as a function of the problem size:
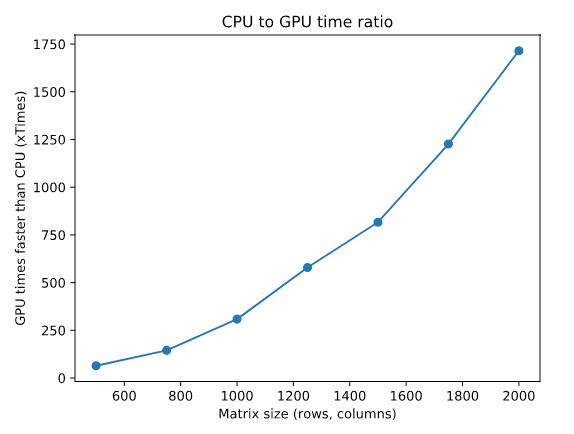
Of course, GPU instances are much more expensive than CPU instances, so ultimately data scientists and machine learning engineers face a cost/performance trade-off when training models on a single processing unit. One way to accelerate training further and widen the choices available is to utilize distributed training.
Distributed Training
A distributed training job comprises three elements:
- Network graph
- How are the workers configured to work together (e.g. parameter server, ring-all-reduce)?
- Data model
- Which workers are reading and processing which part of the data?
- Resource manager
- How are workers being scheduled and coming up?
Distributed training for a deep learning model is an area of intense research. We have found many competing frameworks such as TensorFlowOnSpark (TFoS), Horovod, native distributed TensorFlow, distributed Keras, and others. Most of these frameworks have not come up with frameworks to address the above problem areas in a systematic way, putting a heavy onus on the user when writing distributed training jobs.
For instance, native TensorFlow requires large code changes when distributing as compared to a single processing unit, specifying the network graph, the data model, and the resources directly in the code of the training job (see this page for reference).
On the other hand, established resource managers such as YARN have not fully supported GPUs until version 3.1. As a consequence, joining the Hadoop and TensorFlow world has proved challenging. For instance, TFoS does not fully utilize GPUs when training because of this limitation.
The result is that distributed training for deep learning is largely out of reach of most companies because of the complexity involved. Beyond the pure hardware cost, writing and configuring a distributed job can take a team of highly paid researchers working on the same problem, making the use of this technology prohibitively expensive.
We are actively developing an engine that would make it easy for companies to run distributed training using TensorFlow and Keras both on CPUs and GPUs. The goal is to give users choice and let companies decide their optimal cost/performance trade-off when training DL models at scale.
Conclusion
This is an introductory brief, and in the coming weeks, we will be publishing a series of benchmark studies for single- and multi-node distributed training — with plans to go GA on our deep learning cluster soon. If you want to enroll in our beta program, you can become a Qubole customer today! Plus, you can learn more about Qubole for data science on our website.



