Last week, during the Deep Learning Summit at AWS re:Invent 2017, Terrence Sejnowski (a pioneer of deep learning) succinctly said “Whoever has more data wins”. He was echoing a premise that has been repeated many times in many ways by many people: machine learning requires big data to work. Without large, well maintained training sets, machine learning algorithms—especially deep learning algorithms—fall far short of their potential. That’s why here at Qubole we believe that enabling data scientists starts with giving them a platform to quickly select, clean, and aggregate datasets on a massive scale.
The recent surge in impactful applications of deep learning algorithms has misled many people to believe that there has been a corresponding upswell in innovation in this field. Although there are indeed new bleeding edge algorithms being released (most recently Geoffrey Hinton’s milestone capsule networks), most of the deep learning algorithms used in innovative technologies are actually decades old. What’s truly driving these new applications of artificial intelligence and machine learning isn’t new algorithms but bigger data. As Moore’s law predicted, data scientists now have incredible compute and storage capabilities which enable them to begin to leverage the massive amounts of data that are being collected.
The view that machine learning systems rely significantly on non-machine learning tools is visually explained by a simple diagram from the seminal paper “Hidden Technical Debt in Machine Learning Systems“:
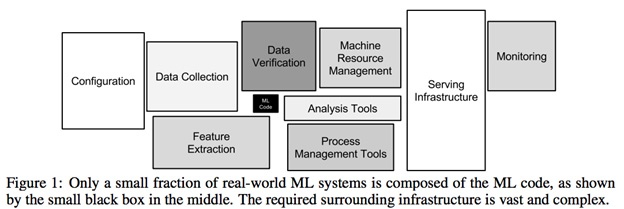
In this image, the Google engineers who wrote the paper are illustrating that actual machine learning code makes up a tiny portion of the overall system required to support ML algorithms at scale. Without all of these other aspects of the system, a standalone block of ML code would be all but useless.
Qubole’s holistic view of the data science workflow has enabled us to take advantage of cutting edge tools for data preparation. Whether it’s using Hive for simple SQL data selections and aggregations or Spark for feature extraction and engineering, Qubole Data Service provides the tools that a data scientist needs in order to successfully leverage their big data for big results.
FREE QDS BUSINESS EDITION
Sign up for free* QDS Business Edition by visiting https://www.qubole.com/products/pricing/.
*Qubole offers Qubole Data Service (QDS) Business Edition at no cost, but usage is limited by Qubole compute hours per month, which is approximately a $1000/month value. You must provide your own cloud account and you are responsible for the infrastructure costs managed by Qubole on your behalf.



