APACHE AIRFLOW
What is Apache Airflow?
Apache Airflow is an open-source tool to programmatically author, schedule, and monitor workflows. It is one of the most robust platforms used by Data Engineers for orchestrating workflows or pipelines. You can easily visualize your data pipelines’ dependencies, progress, logs, code, trigger tasks, and success status.
With Airflow, users can author workflows as Directed Acyclic Graphs (DAGs) of tasks. Airflow’s rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed. It connects with multiple data sources and can send an alert via email or Slack when a task completes or fails. Airflow is distributed, scalable, and flexible, making it well-suited to handle the orchestration of complex business logic.
What is Airflow Used For?
Apache Airflow is used for the scheduling and orchestration of data pipelines or workflows. Orchestration of data pipelines refers to the sequencing, coordination, scheduling, and managing of complex data pipelines from diverse sources. These data pipelines deliver data sets that are ready for consumption either by business intelligence applications and data science or machine learning models that support big data applications.
In Airflow, these workflows are represented as Directed Acyclic Graphs (DAG). Let’s use a pizza-making example to understand what a workflow/DAG is.
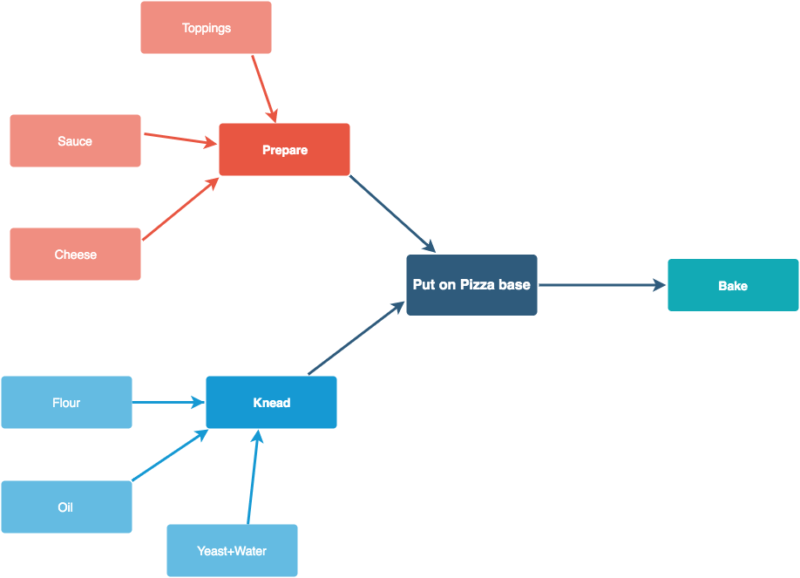
Workflows usually have an end goal like creating visualizations for sales numbers of the last day. Now, the DAG shows how each step is dependent on several other steps that need to be performed first. Like, to knead the dough, you need flour, oil, yeast, and water. Similarly, for Pizza sauce, you need its ingredients. Similarly, to create your visualization from the past day’s sales, you need to move your data from relational databases to a data warehouse.
The analogy also shows that certain steps like kneading the dough and preparing the sauce can be performed in parallel as they are not interdependent. Similarly, to create your visualizations it may be possible that you need to load data from multiple sources. Here’s an example of a Dag that generates visualizations from previous days’ sales.
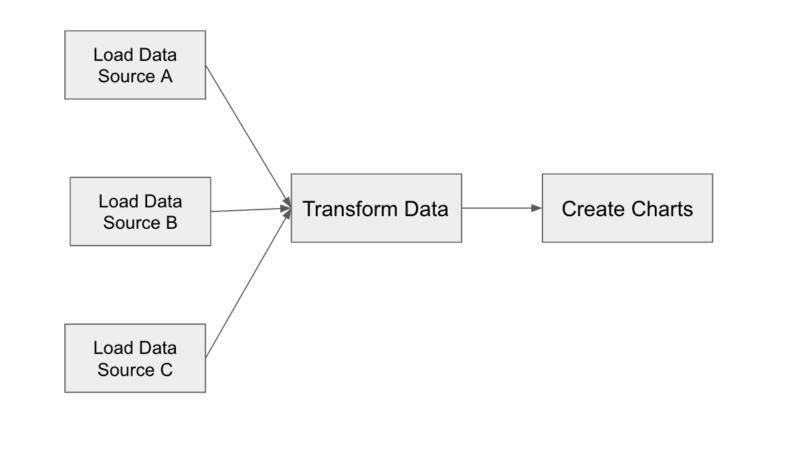
Efficient, cost-effective, and well-orchestrated data pipelines help data scientists develop better-tuned and more accurate ML models because those models have been trained with complete data sets and not just small samples. Airflow is natively integrated to work with big data systems such as Hive, Presto, and Spark, making it an ideal framework to orchestrate jobs running on any of these engines. Organizations are increasingly adopting Airflow to orchestrate their ETL/ELT jobs.
Airflow Architecture
Understanding the components and modular architecture of Airflow allows you to understand how its various components interact with each other and seamlessly orchestrate data pipelines.
- Dynamic: Airflow pipelines are configured as code (Python), allowing for dynamic pipeline generation. This allows users to write code that instantiates pipelines dynamically.
- Extensible: Easily define your operators and executors, and extend the library so it fits the level of abstraction that suits your environment.
- Elegant: Airflow pipelines are lean and explicit. Parameterizing your scripts is built into the core of Airflow using the Jinja templating engine.
- Scalable: Airflow has a modular architecture and uses a message queue to communicate with and orchestrate an arbitrary number of workers.
Read about each of these components in detail here.
Apache Airflow Tutorial
There are multiple ways to set up and run Apache Airflow on one’s laptop. In this blog, we explain three different ways to set it up. In each approach, one can use one of three types of executors. We pick one executor per approach to explain:
- Basic setup using a virtualenv and pip. In this setup, we run SequentialExecutor, which is ideal for testing DAGs on a local development machine.
- Setup using Docker, in which we run CeleryExecutorusing Redis as a queue.
- Kubernetes setup using Helm, for running KubernetesExecutor.
Why You Should Use Apache Airflow for ETL/ELT
Airflow Pipeline
Here are a few reasons why Airflow wins over other platforms:
- Community: Airflow was started back in 2015 by Airbnb. The Airflow Community has been growing ever since. We have more than 1000 contributors contributing to Airflow, and the number is growing at a healthy pace.
- Extensibility and Functionality: Apache Airflow is highly extensible, which allows it to fit any custom use cases. The ability to add custom hooks/operators and other plugins helps users implement custom use cases easily and not rely on Airflow Operators completely. Since its inception, several functionalities have already been added to Airflow. Built by numerous Data Engineers, Airflow is a complete solution and solves countless Data Engineering Use Cases. Although Airflow is not perfect, the community is working on a lot of critical features that are crucial to improving the performance and stability of the Airflow platform.
- Dynamic Pipeline Generation: Airflow pipelines are configuration-as-code (Python), allowing for dynamic pipeline generation. This allows for writing code that creates pipeline instances dynamically. The data processing we do is not linear and static.
Airflow models more closely with a dependency-based declaration as opposed to a step-based declaration. Steps can be defined in small units, but that breaks down quickly as the number of steps becomes larger. Airflow exists to help rationalize this modeling of work, which establishes linear flow based on declared dependencies. Another benefit of maintaining pipelines using code is that it allows versioning and accountability for change. Airflow lends itself to supporting roll-forward and roll-back much more easily than other solutions and gives more detail and accountability of changes over time. Although not everyone uses Airflow this way, Airflow will evolve along with you as your data practice evolves.
Apache Airflow on Qubole
With Airflow on Qubole, you can author, schedule, and monitor complex data pipelines. Eliminate the complexity of spinning up and managing Airflow clusters with one-click start and stop. Furthermore, seamless integrations with Github and AWS S3 ensure your data pipeline runs as smoothly as possible. Also, with Qubole-contributed features such as the Airflow QuboleOperator, customers have the ability to submit commands to Qubole, thus giving them greater programmatic flexibility.
At Qubole, we introduced the following features that make using Qubole Airflow even easier:
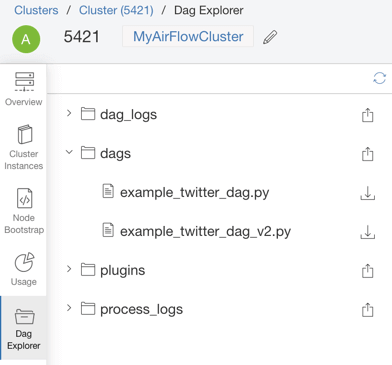
DAG Explorer
For the continuous development, integration, and deployment of Airflow DAGs, Qubole has introduced tooling to upload Airflow Python DAG files to Amazon S3, edit them in place, and periodically sync them with Airflow clusters (in the background). You can also download other relevant Airflow files such as process and log files from the Airflow cluster page. This aids the quick, iterative development of complex workflows and keeps the files in sync. For more information, click here.
Watch this video to learn about DAGs, tasks, and how to write a DAG file for Airflow. This episode also covers some key points regarding DAG runs and Task instances.
Anaconda Virtual Environment
You can now run Airflow on an Anaconda virtual environment. Users have the option of choosing the Python version while creating an Airflow cluster. Selecting Python 3.5 triggers the Airflow setup on the Anaconda environment along with support for package management (ability to install/uninstall packages on the cluster from the Qubole UI) for the cluster. More information can be found here.
Running Airflow on the Anaconda environment provides users with the simplicity of running machine learning and data science tasks by building complex data pipelines. It also gives them the flexibility to install various packages optimized for data science tasks available within the Anaconda environment on the go with Qubole’s package management feature. Read more on how to run Airflow on Anaconda with Qubole here.
Apache Airflow As a Service on QDS
Airflow on QDS allows data teams to focus on creating dynamic, extensible, and scalable data pipelines while leveraging Qubole’s fully managed and automated cluster lifecycle management for Airflow clusters in the cloud.

Automated Cluster Lifecycle Management: Airflow clusters on QDS leverage Qubole’s automated cluster lifecycle management infrastructure currently in production and shared across Hadoop, Spark, Presto, and HBase clusters. As a result, you can take advantage of one-click cluster provisioning, specify Airflow specific settings, configure clusters to launch securely within your VPCs and Subnets, and select from 40+ AWS instance types.

Integration between QDS and Airflow: In this blog, we introduced the Qubole Operator, which allows you to integrate Airflow with your data pipelines in QDS. Using this operator, you will be able to use Airflow to create and manage complex data pipelines while submitting jobs directly to QDS.

Monitoring: You can monitor the status of your workflows via the Airflow web server that is readily available upon launching Airflow clusters. In addition, Qubole also provides monitoring through Ganglia and Celery Dashboards.

Reliability: We’ve extended the codebase to make it more reliable. So in the unlikely event that causes Airflow to become unresponsive, restarting the Airflow cluster will automatically bring Qubole Operator jobs back to their original state.

Better User Experience: We’ve implemented a solution to cache assets, which significantly reduces the Airflow web server’s loading time. In addition, we have added the ability to navigate from the Airflow web interface to QDS easily. These enhancements are important because monitoring data pipelines is a crucial part of processing Big Data workloads.

Security and Accessibility: All the actions on Airflow clusters go through existing roles, users, and groups based on security currently in production on QDS. This eliminates the need to implement other/custom ACL or security mechanisms to authorize access to your Airflow clusters and workflows.
For technical details on setup, configuration, deploying, and using Airflow as a service on QDS, please refer to our documentation.


