Data Lakes are a core pillar in an organization’s data strategy. They make organizational data from different sources accessible to various end-users such as business analysts, data engineers, data scientists, product managers, executives, etc. Data lakes are open format, highly durable, and low cost, because of their ability to scale and leverage object storage. The unique ability to ingest unstructured, raw data in a variety of formats (structured, unstructured, semi-structured) along with advanced analytics and machine learning, make a data lake the clear choice for data storage. In fact, many forms of advanced analytics are currently possible only in data lakes – for example, one can store huge amounts of (unstructured) text and run State-of-the-art Natural Language Processing on it. Similarly, one can store video data for Data Science usage.
Data Lake Essentials
Whether you are starting your Data Lake journey, or already operating a data lake, make sure that you check this excellent primer on Data Lake Essentials before continuing.
In this three-part blog, we will build upon the primer and discuss strategies for ingesting data into the Lake.
- Part 1: Ingestion to the Data Lake
- Bulk loading of historical data
- Continuous ingestion
- Part 2: Optimizing the ingestion pipelines
- Usual Challenges and Remediation
- Part 3 – Advances in ingestion: Transactions on the Data Lake
- Using ACID transactions for continuous ingestion
In this edition, we discuss loading existing data into the data lake and historical mechanisms to keep the data lake updated.
Data Lake Implementation
The Data Lake serves as the repository for various kinds of data like Transactional Data from RDBMS, event logs and web server logs, NoSql data, social media data, sensor & IoT data, and third-party data. Depending on the data source, it can be structured, semi-structured, or even unstructured.
The structured data residing in RDBMSs are of particular interest to many teams as they often host the most critical data sources. This data is used for generating business insights and dashboards. Capturing this data into the data lake is an important activity. Let us look into how this data can be reliably and efficiently replicated onto the Data Lake.
The decision to create a Data Lake often comes after a company is financially viable and is looking to use its data to scale the business further. As such, the source transactional systems would have collected a sizable amount of data when the Data Lake is commissioned.
So our strategy should account for
- A historical bulk replication of data from the source to the lake
- An ongoing capture of new data from the source to the lake
Data Lake Storage
When it comes to storage, a “lift & shift” strategy is simple and effective. More often than not, the cloud object stores like Amazon S3, Google Cloud Storage, etc are the storage layer of Data Lakes. They offer highly available, durable, and, most importantly, cheap storage. Hence a lift & shift make sense, considering that it is not going to cost a lot.
As part of the lift & shift, important considerations are to be made:
Analytical Patterns
Knowledge of query patterns and query frequency on these systems influence decisions on data formats, partitioning, and lifecycle rules.
Data Format
The analytical patterns of a data source influence whether data should be stored in Columnar or Row-Oriented formats. Two copies of the same data in different formats catering to varying query patterns are viable options.
Partitioning Scheme
The data lake equivalent of (RDBMS-like) indexing is “partitioning” and “bucketing”. The correct strategy will boost query performance across all engines.
Schema Evolution
Source schemas change and evolve over time. In the data lake, schema evolution is largely a function of the chosen file format. Engines supporting schema-on-read leverage the file format’s evolution capabilities to handle schema evolution gracefully
Managed vs External Metastore Tables
External Tables are the default choice for exposing structured data in the data lake for SQL. However, recent advances have made Managed Tables with ACID transactions on the Data Lake feasible.
The data lake destinations should be carefully designed based on the above considerations. Part 2 of this series deep dives into each consideration and provides recommendations based on our field experience.
In the remainder of this blog, we will step through simulated ingestion scenarios as a warm-up before diving deeper into the weeds.
Prerequisites
- Setup a Source RDBMS Schema and Table(this example uses MySQL)
create table avengers_details( id int(11), first_name text, last_name text, email text, gender text, dob date, address text, city text, state text, create_date timestamp NOT NULL, last_update timestamp NOT NULL, PRIMARY KEY(id) );
INSERT into character_details(id,first_name,last_name,email,gender,dob,address,city,state,team,subteam, create_date,last_update) values ('1001','James','Howlett','[email protected]','Male','1970-01-01','Xavier School for Gifted Youngsters','Salem','NY', 'avengers', 'x-men', NOW(), NOW()), ('1002','Matt','Murdock','[email protected]','Male','1970-01-01','Hells Kitchen','NYC','NY', 'avengers', 'defenders', NOW(), NOW()), ('1003','Bruce','Banner','[email protected]','Male','1970-01-01','NA','Dayton','Ohio', 'avengers', 'fantasic-four', NOW(), NOW()), ('1004','Carol','Denvers','[email protected]','Female','1970-01-01','NA','NYC','NY', 'avengers', 'guardians', NOW(), NOW()); - Register this Source with Qubole: Understanding a Data Store — Qubole Data Service documentation
Apache Sqoop
First, let us look at a demonstration:
As seen in the demonstration,
- We create a staging table in our Data Lake, registered with the Hive Metastore. This table will be an exact copy of the source table.
CREATE EXTERNAL TABLE marvel_universe_db_hive.character_details_staging ( id int, first_name varchar(200), last_name varchar(200), email varchar(200), gender varchar(200), dob date, address varchar(200), city varchar(200), state varchar(200), team varchar(200), subteam varchar(200), create_date timestamp, last_update timestamp ) STORED AS PARQUET LOCATION "s3://<bucket>/marvel_universe_db_hive/character_details_staging";
- We create the desired destination table in our Data Lake. It reflects our chosen data format and desired partitioning strategy.
CREATE EXTERNAL TABLE marvel_universe_db_hive.character_details ( id int, first_name varchar(200), last_name varchar(200), email varchar(200), gender varchar(200), dob date, address varchar(200), city varchar(200), state varchar(200), create_date timestamp, last_update timestamp ) PARTITIONED BY(team varchar(200), subteam varchar(200)) STORED AS PARQUET LOCATION "s3://<bucket>/marvel_universe_db_hive/character_details";
- We use Qubole’s Data Import feature(Apache Sqoop) to lift and shift data from our source to the staging table.
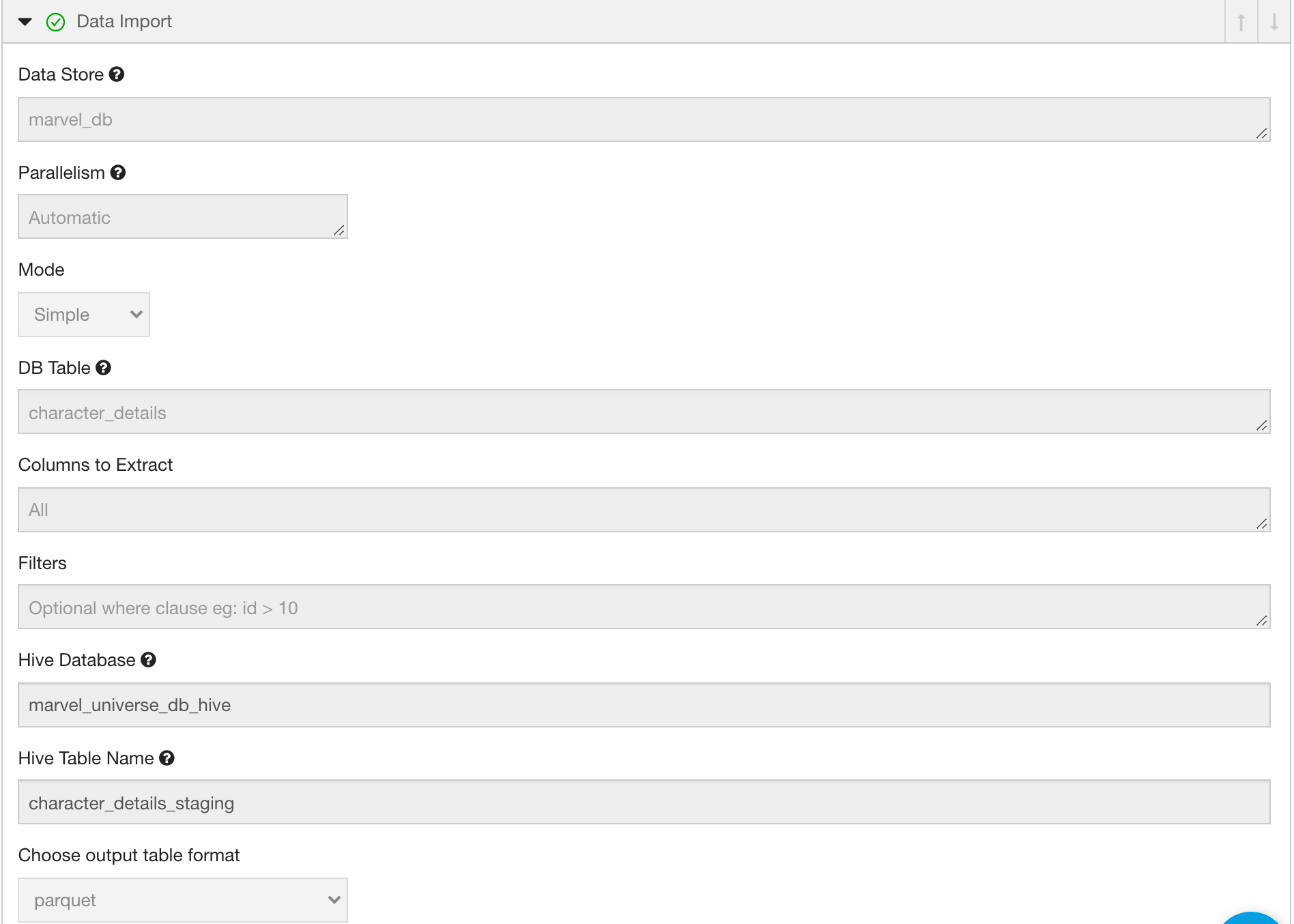

- We use Qubole’s Hive Engine to perform necessary transformations (in this case – partitioning) and write the data to the destination table.
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE marvel_universe_db_hive.character_details PARTITION (team, subteam) SELECT id,first_name,last_name,email,gender,dob,address,city,state,create_date,last_update,team,subteam FROM marvel_universe_db_hive.character_details_staging;
Using a staging pattern is very useful. It will allow easy import of the source data to the lake where Big Data Engines like Hive and Spark can perform any required transformations, including partitioning, before loading them to the destination table.
Apache Sqoop
Sqoop is an excellent purpose-built tool for moving data between RDBMS and HDFS-like filesystems. It uses the robustness of the MapReduce framework to perform its tasks reliably.
However, at times, it can lack the programmatic flexibility that frameworks like Apache Spark can provide. In such cases, we can easily use Apache Spark to perform the same migration of data.
Let us look at a demonstration:
As seen in the demonstration,
- We create the desired destination table in our Data Lake. It reflects our chosen data format and desired partitioning strategy.
CREATE EXTERNAL TABLE marvel_universe_db_hive.character_details ( id int, first_name varchar(200), last_name varchar(200), email varchar(200), gender varchar(200), dob date, address varchar(200), city varchar(200), state varchar(200), create_date timestamp, last_update timestamp ) PARTITIONED BY(team varchar(200), subteam varchar(200)) STORED AS PARQUET LOCATION "s3://<bucket>/marvel_universe_db_hive/character_details";
- We use Qubole’s Spark with its built-in Qubole DBTap mechanism to seamlessly and securely read the source RDBMS Data into a distributed Spark Dataframe.
- We use Spark’s programmatic flexibility to perform all the transformations we need without resorting to a staging table on the S3 Data Lake.
- The transformed and partitioned table is directly written to the Hive Table on the Data Lake, using Qubole’s innovations on Direct Writes to Amazon S3.
import org.apache.spark.sql.qubole.QuboleDBTap import org.apache.spark._ import org.apache.spark.sql._ val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) val catalogName = "marvel_db" val databaseName = "marvel_universe_db" val quboleDBTap = QuboleDBTap.get("marvel_db",sqlContext)val includes = List() val excludes = List()quboleDBTap.registerTables("$marvel_universe_db", includes, excludes) val tableName = "character_details"val characters_df = sqlContext.sql(s"select id,first_name,last_name,email,gender,dob,address,city,state,create_date,last_update,team,subteam from `marvel_db.marvel_universe_db.character_details`")characters_df.write.mode(SaveMode.Overwrite).insertInto("marvel_universe_db_hive.character_details")quboleDBTap.unregister()
Apache Spark provides tremendous programmatic flexibility to process and load data into the Data Lake and is a viable alternative to Apache Sqoop. However, it trades off the ease of use (read configuration and a simplified UI) offered by Apache Sqoop for more programmatic flexibility and power.
Apache Hive
Another not-so-known method of doing the historical load is via Apache Hive. We can create EXTERNAL Tables on top of storage systems like RDBMS in Hive using the appropriate Storage Handlers. Once created, we can use simple SQL-like syntax to lift and shift the data.
Let us see this in action:
- Create an External Table pointing to the source RDBMS
CREATE EXTERNAL TABLE marvel_universe_db_hive.character_details_ext( id int, first_name varchar(200), last_name varchar(200), email varchar(200), gender varchar(200), dob date, address varchar(200), city varchar(200), state varchar(200), team varchar(200), subteam varchar(200), create_date timestamp, last_update timestamp ) STORED BY 'org.apache.hive.storage.jdbc.JdbcStorageHandler' TBLPROPERTIES ( "hive.sql.database.type" = "MYSQL", "hive.sql.jdbc.driver" = "com.mysql.jdbc.Driver", "hive.sql.jdbc.url" = "jdbc:mysql://<rdbms_host>/marvel_universe_db", "hive.sql.dbcp.username" = "<user_name>", "hive.sql.dbcp.password" = "<password>", "hive.sql.query" = "select * from character_details", "hive.sql.dbcp.maxActive" = "1" );
- Use SQL to copy data from source to destination
INSERT INTO marvel_universe_db_hive.character_details(id, first_name, last_name, email, gender, dob, address, city, state, team, subteam, create_date, last_update) SELECT id, first_name, last_name, email, gender, dob, address, city, state, team, subteam, create_date, last_update FROM marvel_universe_db_hive.character_details_ext;
To sum up, there are plenty of mature open-source tools that can help perform this initial migration and priming of the data lake. Qubole provides these in a managed form so that your data lake can be functional with minimal operational overhead and provide quick time to value.
Data Pipeline Engineering
Once the baseline data has been primed onto the data lake, it needs to be continually synced and updated with the source systems. Data Lake Storage Layers are usually HDFS and HDFS-Like systems. Hence they are limited by the constraints of the immutability of data that is written onto them. This creates data engineering challenges in how to keep the Data Lake up-to-date.
There are two distinct challenges when engineering these data pipelines:
Capturing the delta
Here, “delta” refers to the data that has been changed, appended, or deleted. There are two ways we can approach this:
- Data Timestamps
- Useful for capturing inserts and updates
- Cannot capture deletes
- Requires a high level of confidence in the timestamps (accuracy and availability)
- Will make direct queries and hence use RDBMS compute resources
- In this method, delta records are retrieved by a query on the source database. This query uses the created_at and updated_at timestamps to get the delta records.
- Using database binlogs
- RDBMS relies on logs for processing transactions. Internally they are represented as binary logs or binlogs. Binlogs capture Insert, Update, and Delete events.
- Binlogs can be read asynchronously to capture deltas.
- They are more reliable and complete than the timestamp method
- They do not involve queries on the RDBMS and hence do not consume compute resources
- Additional infrastructure is required to capture and process the binlogs into the Data Lake
In this method, specialized tools read the binary logs and publish them to messaging queues or file systems.
Synchronizing the delta
Once the delta has been captured and staged, it needs to be merged with the destination tables.
Recent advances have enabled ACID-compliant transactions (CRUD – Create, Read, Update, Delete) at a row level as well as in bulk forms on HDFS-Like systems. Their syntactic simplicity and the novelty factor cannot be ignored. This makes it easy to gravitate toward adopting these technologies as a mechanism for Change Data Capture (CDC) to the Data Lake. We cover them in Part 3 of this blog series.
However, it is essential to evaluate the requirements of the change data capture across the data sources. More often than not, traditional methods will suffice. So what are these “traditional methods” of change data capture?
The traditional methods are based on two core pillars.
- Timestamp Columns: for capturing row creation and row update times.
- Partitions as the lowest level of transactions: Only the partitions that have received changes will be recomputed (or refreshed).
To see whether this method of change capture can suffice, we can consider the following:
- Data refresh SLAs
The consumer’s SLAs should drive change capture schedules. All the changes in an observation period can be gathered and merged. Such bulk updates are likely to span across partitions, and traditional methods will be suitable. ACID capabilities are suited for Near Real-Time capabilities. - Types of changes(Inserts/Updates/Deletes)
The traditional methods are well-suited for capturing Inserts and Updates. However, they cannot handle Deletes. ACID capabilities unlock Delete capture. - Consumer Privacy Laws & Enforcements
With consumer data privacy laws and enforcements, customers get right-to-forget and delete-my-data rights. This requires SLA-bound row-level transaction capabilities. In such cases, ACID capabilities are a must.
Prerequisites
- The steps in the previous section are completed successfully:
- There should be a source table initialized with some data
- There should be a Hive table on the Data Lake as the destination
- A historical(baseline) load has been performed, and the source and destination are in sync.
- Introduce some change events. In this case, we will stick to INSERT and UPDATE events (In Part III of this blog, we will provide a delete example). Capturing DELETEs requires capturing the delete event from the Database’s binlogs and merging them with our Data Lake. This capability is unlocked with the introduction of ACID capabilities and it will be explored in part 3 of the blog series.
cdc_source_tbl_user_demographics SET address = '417 5th Avenue, Apartment 10B, 10016', last_update = NOW() where id = '1004';
INSERT into character_details(id,first_name,last_name,email,gender,dob,address,city,state,team,subteam, create_date,last_update)
values
('1010','Nick','Fury','[email protected]','Male','1970-01-01','NA','Huntsville','Alabama', 'avengers', 'shield', NOW(), NOW()),
('1011','Peter','Quill','[email protected]','Male','1970-01-01','NA','St. Charles','Missouri', 'guardians', 'ravagers', NOW(), NOW()),
('1012','Frank','Castle','[email protected]','Male','1970-01-01','Hells Kitchen','NYC','NY', 'avengers', 'defenders', NOW(), NOW());Apache Spark
Capturing change data on Qubole, using Apache Spark is straightforward, as seen in this demonstration:
As seen in the demonstration,
- We captured the partitions that received Inserts or Updates in the given observation period(1 day) based on the create and update timestamps.
- We used Spark’s Hive Overwrite Partition mechanism to refresh only the required partitions
import org.apache.spark.sql.qubole.QuboleDBTap
import org.apache.spark._
import org.apache.spark.sql._
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
val quboleDBTap = QuboleDBTap.get("marvel_db",sqlContext)val includes = List()
val excludes = List()quboleDBTap.registerTables("marvel_universe_db", includes, excludes)
val tableName = "character_details"val changed_data_df = sqlContext.sql("select id,first_name,last_name,email,gender,dob,address,city,state,create_date,last_update,team,subteam from `marvel_db.marvel_universe_db.character_details` where (team, subteam) in (select team, subteam from `marvel_db.marvel_universe_db.character_details` where create_date BETWEEN '<cdc_start>' AND '<cdc_end>' or last_update BETWEEN '<cdc_start>' AND '<cdc_start>')"
)changed_data_df.write.mode(SaveMode.Overwrite).insertInto("marvel_universe_db_hive.character_details")quboleDBTap.unregister()Apache Spark is an excellent tool to recompute partitions and perform any required transformations on the captured change data and register it with Hive. It can efficiently process Inserts and Updates using reliable timestamp columns.
Apache Sqoop is also an excellent alternative. It provides incremental capture modes that can capture inserts and updates based on reliable timestamps as well. The reader can take it as an exercise to achieve the same on the Qubole Platform.
Data Lake Ingestion patterns from the field
There is no one-size-fits-all approach to designing data pipelines. Every team has its nuances that need to be catered to when designing the pipelines. However, if we look at the core, the fundamentals remain the same. Here are some common patterns that we observe in action in the field:
Pattern 1: Batch Operations
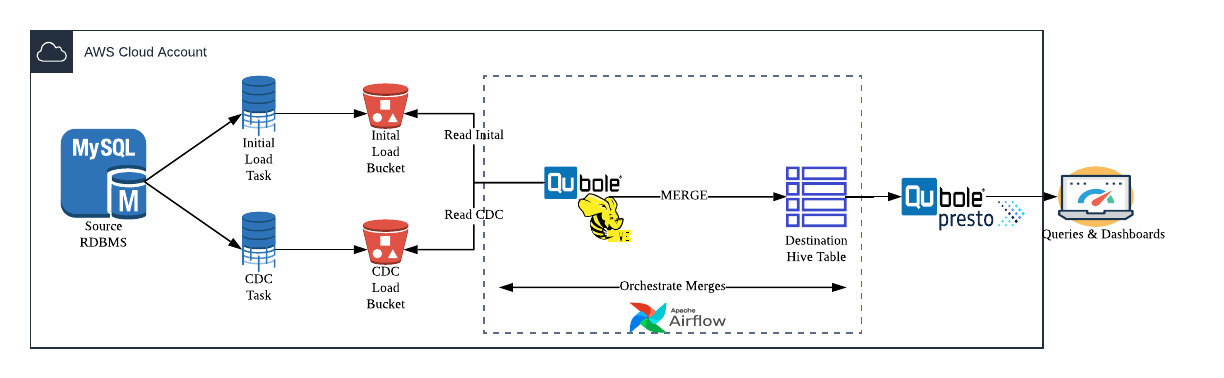
This pattern primarily focuses on batch operations where the data lake destination need not be in near real-time synchronization with the source system.
Here, the fundamental concept is having an initial batch load task that captures a baseline slice of data and uploads it to the Data Lake destination. Simultaneously, there is a CDC task that switches on once the initial load is complete and feeds Inserts and Updates to the destination in the Data Lake. All the components here are pluggable. One can use DIY approaches as discussed above to build the tasks or use pre-built services like AWS DMS to do them for you. The engine responsible for merging the data can be Hive, Spark, Sqoop, or any other tool on your tech stack.
Pattern 2: Near Real-Time Operations
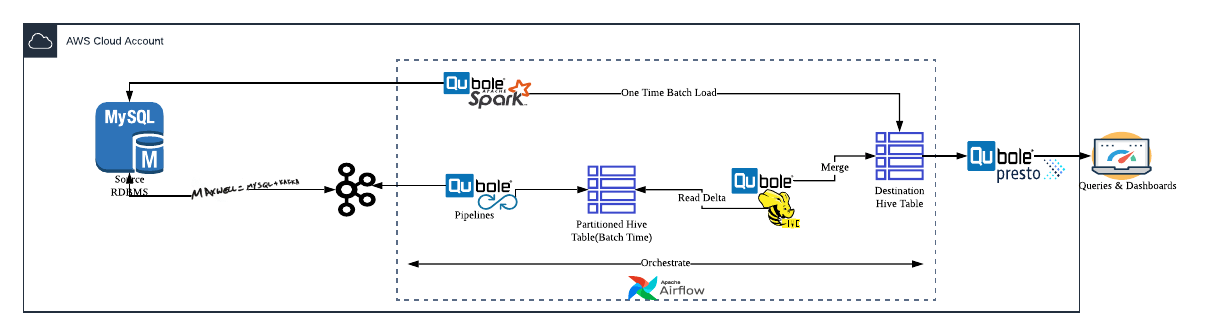
This pattern focuses on near real-time operations where the data lake destination needs to be in sync with the source systems.
Here, the focus lies in building a real-time feed of the changes in the source system. One can use binlog readers like Maxwell or Debezium to feed captured changes to a messaging system like Kafka. This can be picked up by real-time or near real-time systems like Apache Spark Structured Streaming (Qubole Pipelines Service provides an enhanced version) and then merged into destination tables using Apache Hive or Apache Spark-based Merge constructs.
These patterns are all-encompassing in no way, but they expose the fundamental building blocks that can be employed to suit needs.
Now that we have seen how Qubole allows seamless ingestion mechanisms to the Data Lake, we are ready to deep dive into Part 2 of this series and learn how to design the Data Lake for maximum efficiency.



