Big Data Analytics Storage
In today’s dynamic business environment, new data consumption requirements and use cases emerge rapidly. By the time a requirements document is prepared to reflect requested changes to data stores or schemas, users have often moved on to a new set of schema changes. In contrast, the entire philosophy of a data lake revolves around being ready for an unknown use case. When the source data is in one central lake, with no single controlling structure or schema embedded within it, supporting a new additional use case is a much more straightforward exercise.
Data Lake Architecture
Data Lake architecture is all about storing large amounts of data, which can be structured, semi-structured, or unstructured, for example, web server logs, RDBMS data, NoSql data, social media, sensors, IoT data, and third-party data. The primary purpose of a data lake is to make organizational data from different sources accessible to various end-users like business analysts, data engineers, data scientists, product managers, executives, etc., to enable these personas to leverage insights in a cost-effective manner for improved business performance. Today, many forms of advanced analytics are only possible on data lakes. And having the right platform and engine means that projects are better positioned to find significant value from data in less time.
One of the first considerations in building a data lake is storage. There are three basic types of data storage:

Immutable Raw Storage Bucket

Optimized Storage

Scratch database
The type of data and how you use it will determine which data goes where.
Immutable Storage
Data stored in immutable storage cannot, and should not, be altered after it has been written. In an immutable raw storage area in your data lake, you store data that hasn’t been scrubbed. You might never have even looked at it. But it should have sufficient self-descriptive language, or metadata, around it – such as table names and column names – so that you can determine where the data came from. You might store it in a text format such as JavaScript Object Notation (JSON) or comma-separated values (CSV), or perhaps even Apache Avro. Most people prefer to store it in either JSON or CSV files.
JSON, a lightweight data-interchange format based on a subset of JavaScript, is easy for humans to read and write and easy for machines to parse and generate. The following is a quick sample:
{ “title”:”Programming Hive”
“authors”:[“Edward Capriolo”,”Dean Wampler”,”Jason
Rutherglen”],
“isbn-10″:”1449319335” }
CSV format files are delimited plain-text files in which each record consists of one or more fields that are separated by commas. The commas separate values of tabular data:
title,authors,isbn-10
“Programming Hive”,”Edward Capriolo,Dean Wampler,Jason
Rutherglen”,”1449319335″
Immutable raw storage fills many data storage needs. Three of the most important are:
- Disaster recovery: If anything ever happens to the original data stores, you have a replica.
- Forensic analysis: Immutable raw storage records can be used to trace problems, such as when bugs were introduced into a program.
- Ability to re-create and update optimized formats: Immutable raw storage ensures that the data is always there in its original state, to be used again if needed.
For example, if your transactional tables are dumped every morning into the immutable raw storage area, you would have snapshots of data, which is very important for the three reasons mentioned above. Financial companies may need these snapshots to review data and see how it has changed over time. You might need these tables if you’re ever audited, or if transformed files become corrupted. After you have an audit table, transactional systems become unwieldy and difficult to manage—that’s why you want a raw data bucket. You shouldn’t change the data in it; after all, it’s raw, static, slow, and pretty damn dirty. But you can query and optimize it.
Data Partitioning
As your raw data grows, your queries into it become slower. No one likes waiting hours to see whether their query succeeds, only to find that it failed. Data scientists and analysts need their questions answered to turn data into insights faster than that. To gain this speed, transforming your data by storing it using one of the many optimized formats available. Three open-source choices are Parquet, optimized row-column (ORC), and Avro.
Parquet Data Format
Apache Parquet is an open-source, column-oriented storage format for Hadoop. Parquet is optimized to work with complex data in bulk and includes methods for efficient data compression and encoding types.
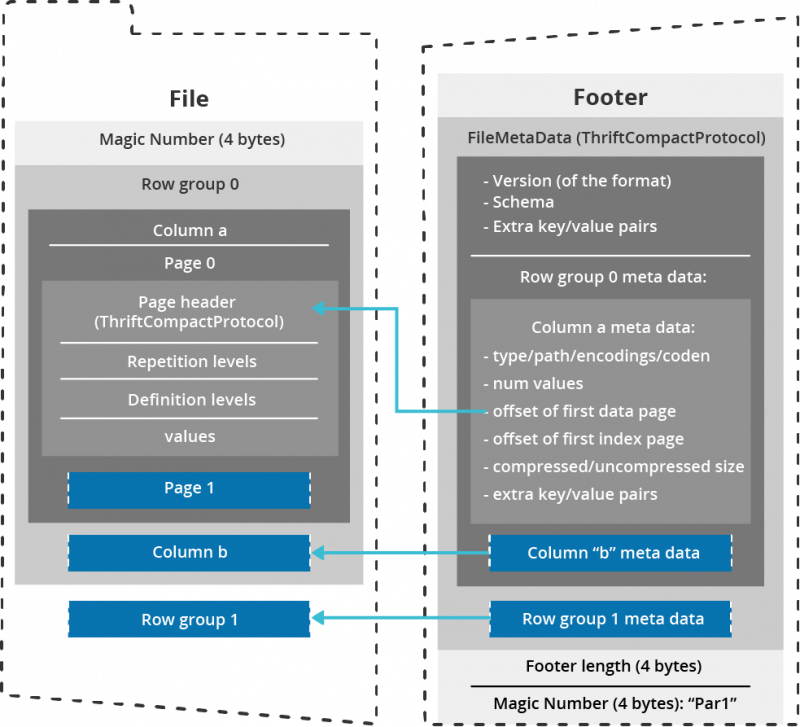
Optimized Row Column (ORC)
ORC stores collections of rows in one file, with the row data stored in a columnar format. This allows parallel processing of row collections across a cluster. Each file with the columnar layout is optimized for compression. Skipping data and columns reduces both read and decompression loads.
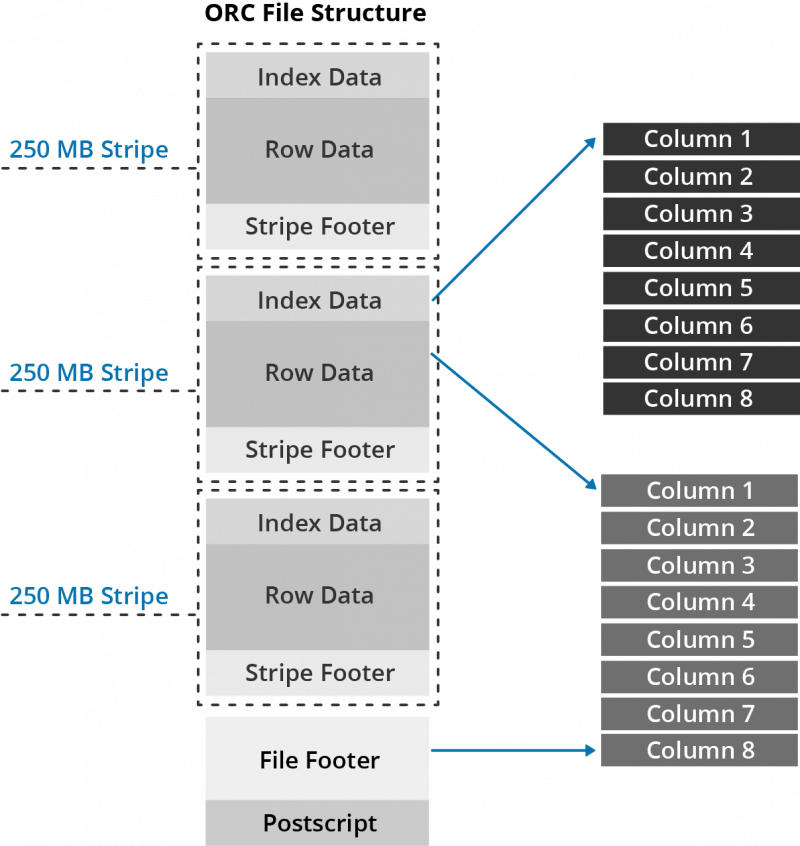
Avro
Avro is a remote procedure call and data serialization framework. Developed within Apache’s Hadoop project, it uses JSON to define data types and protocols and serializes data in a compact binary format.
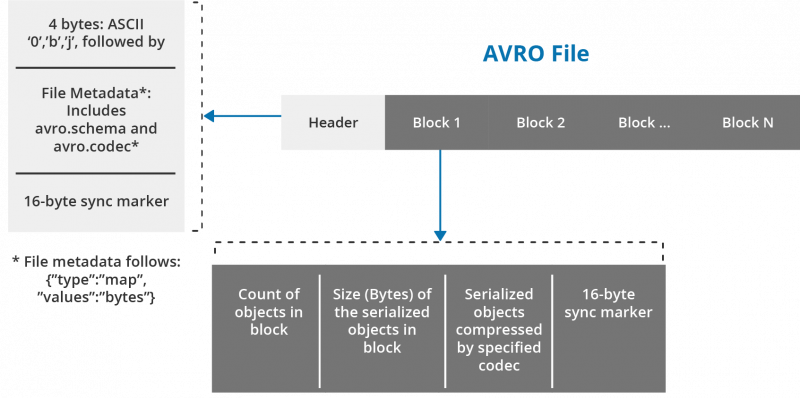
You can split files stored in Parquet, ORC, and Avro formats across multiple disks, which enables scalability and parallel processing. JSON and XML files cannot be split, which seriously limits their usefulness.
All three formats carry the data schema within the files themselves, which is to say they’re self-described. You can take an ORC, Parquet, or Avro file from one cluster and load it on a completely different machine, and the machine will know what the data is and be able to process it. In addition to being file formats, Parquet, ORC, and Avro are also on-the-wire formats, which means you can use them to pass data between nodes in your Hadoop cluster. The below table compares the characteristics of the formats.

Scratch Database
Finally, you will usually create what are called user scratch databases. These are necessary because data scientists and analysts will want to take data out of the optimized schema and build test tables for their purposes. But because you don’t want anyone to inadvertently mess up your data lake—or turn it into a data swamp—you need a place where users can have their little sandboxes to play in that won’t mess up the clean, well-defined, and well-structured data in the optimal data space. For this, too, you need governance. How big can these databases be? How do you monitor them? Do you need an automated report fired off each week to remind people to clean up their data? There’s a lot of housekeeping to perform when you have scratch databases in your data lake.
Here are some of the benefits of a scratch database:
- Users can do their work without fear of overwriting sources of truth.
- DataOps can manage resources by user, team, or product.
- The business has the ability to place governance controls at the user level.
Data Lake Storage
Here are some key considerations while evaluating technologies for cloud-based data lake storage are the following principles and requirements:
Data Lake Scalability
An enterprise data lake is often intended to store centralized data for an entire division or the company at large; hence it must be capable of significant scaling without running into fixed arbitrary capacity limits.
Data Lake Durability
As a primary repository of critical enterprise data, a very high durability of the core storage layer allows for excellent data robustness without resorting to extreme high-availability designs.
Unstructured, semi-structured, and structured data
One of the primary design considerations of a data lake is the capability to store data of all types in a single repository. For example, XML, Text, JSON, Binary, CSV etc.
Schemaless Architecture
Schema evolution is common in the big data age. The ability to apply schema on read, as needed for each consumption purpose, can only be accomplished if the underlying core storage layer does not dictate a fixed schema.
Separation from compute resources
The most significant philosophical and practical advantage of cloud-based data lakes as compared to ‘legacy’ big data storage on Hadoop/HDFS, is the ability to decouple storage from compute and enabling independent scaling of each.
Data Lake and Data Warehouse
Data warehouse and data lake can work in conjunction for a more integrated data strategy.
Cost-effective Data Lake Storage
NEW! Spark 3.3 is now available on Qubole. Qubole’s multi-engine data lake fuses ease of use with cost-savings. Now powered by Spark 3.3, it’s faster and more scalable than ever.
Open source has zero subscription costs, allowing your system to quickly scale as data grows. Handling cold/hot/warm data and data models and appropriate compression techniques helps prevent cost growth exponentially.
Given the requirements, object-based stores have become the de facto choice for core data lake storage. AWS, Google, and Azure all offer object storage technologies. For example, S3, Blob storage, ADLS, etc.
Big Data
Big data is quickly becoming a more vital component of any business, and using it to the fullest requires storage capabilities. In much the same way companies came to realize the benefits of big data, they’ll likely come to understand why storage option is a necessary move if they hope to unlock all of the big data’s potential. With the right strategy, it won’t be long before all of that potential is realized.
Qubole
Multi-cloud offering:
Qubole helps you avoid cloud vendor lock-in by offering a native multi-cloud platform along with support for their corresponding native storage options: AWS S3 Object Store, Azure data lake and Blob, Google Cloud Storage.
Intelligent and automatic response:
To both storage and compute needs of bursty and unpredictable big data workloads. It evaluates the current load on the cluster in terms of compute power and intelligently predicts how many additional workers are needed to complete the workload within a reasonable time. Qubole automatically upscales the storage capacity of individual nodes that are nearing full capacity.
Unified data environment:
With connectivity to traditional Data Warehouses and NoSQL databases (on-premise or in the cloud).
Support for various mechanism:
For Encrypting data at rest in coordination with your choice of the cloud vendor.
Multiple distributed big data engines:
Spark, Hive, Presto, and common frameworks like Airflow. Multiple engines allow data teams to solve a wide variety of significant data challenges using a single unified data platform. User-friendly UI for data exploration (Workbench) – as well as a built-in scheduler for sequential workflows to accelerate time to value.
Support for Python/Java SDKs and REST APIs:
Allows easy integration to your applications.
Ingestion and processing from real-time streaming data sources:
Allowing your data teams to address use cases that call for immediate action and analysis.
Integration with popular ETL platforms:
Such as Talend and Informatica accelerates adoption by traditional data teams.
Multiple facilities for Data Import/Export:
Using different tools and connectors, data teams can import the data into Qubole, run various analyses and then export the result to your favorite visualization engine.


