Data Engineers and Enterprises continue to struggle with Stream Processing at scale. In our extensive discussions with customers and partners, we repeatedly found the following problems:
- Software development life-cycle can be hard and daunting – especially to non-experts
- Reliable operations at scale are hard to achieve. Observability and data quality are major issues for production deployments.
- Achieving high performance and reliability at a low cost is challenging.
- Data management problems like small files and inconsistent data continue to persist.
Solving these problems comprehensively is a big undertaking. Over the last couple of years, we worked with early customers across Marketing, Entertainment, Crypto, and Fintech to make them successful with streaming applications. Today we are proud to officially launch the Qubole Pipelines Service to the whole world.
Introducing Qubole Pipelines Service
With an aim to solve the above problems – we built a Streaming Service with these salient features:
- Accelerated Development Cycle: Numerous built-in connectors, code generation wizard, dry run framework, and quick-start options accelerate the software development lifecycle. A pipeline can be developed within minutes without writing even a single line of code and be deployed instantly.
- Robust and Cost-Efficient Stream Processing Engine: We chose Apache Spark Structured Streaming as our streaming engine of choice and made numerous enhancements – Rocksdb State Storage, Direct Writes, Executor Taint Management – to reliably productionize long-running streaming applications.
- Comprehensive Operational Management: Broad set of APIs and Interfaces for engineers to holistically manage the lifecycle of various applications and get continuous operational insights.
- Data Management and Consistency: The Pipelines Service uses Qubole’s ACID framework to compact data in the background and allow readers to query the latest data in a performant yet consistent manner.
In the following sections, we will dive deeper into each of these features.
Accelerated Development Cycle
The complexity of developing a streaming application can be daunting. The following features help users get started much faster:
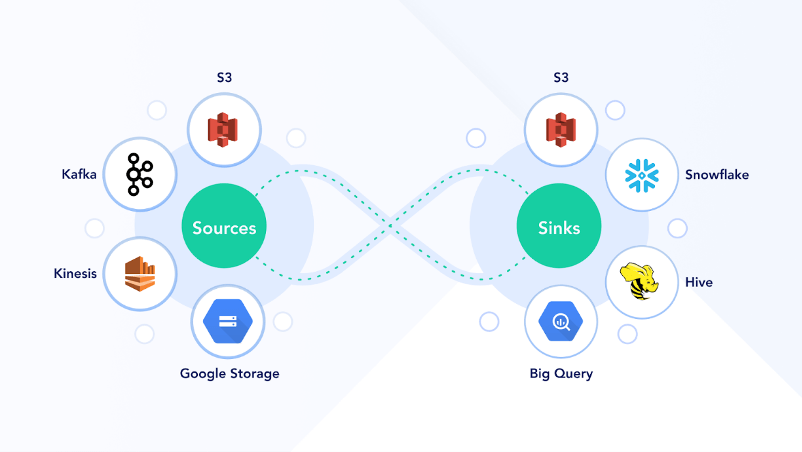
- Pre-Packaged Connectors: Pipelines Service comes packaged and enterprise support for Kafka, Kinesis, S3, S3-SQS, GCS, HIVE, HIVE-ACID, Snowflake, BigQuery, ElasticSearch, MongoDB & Druid. It also helps in discovering data and connecting to it.

- Ease of Development: One of our focus areas has been helping users author streaming pipelines faster. We have done this through mechanisms:
- Assisted Pipelines help in discovering data, connecting to it, and building the business logic through a UI-driven interface. The Pipelines Service generates code from this input that can then be edited by users if required.


- Bring your own Jar/Code: Users can compose the streaming application in the IDE of their choice. They can deploy the application by providing either the code or the compiled jar through UI, REST APIs, or Python SDK. We have added some sample spark streaming examples to help users in getting started
- Ease of Testing and Debugging: We have added the test framework to dry-run a streaming application with a smaller set of input data for a few minutes. This helps in verifying the connectivity, and completeness of the business logic.
- Seamless Upgrades: Pipelines Service provides simple mechanisms to iteratively develop streaming applications, upgrade them, and re-deploy them with near-zero downtime and no event loss. Similarly – users can also move their application from one Apache Spark cluster to another. On cluster upgrade, the application seamlessly auto-starts and picks from the last checkpoint.
Robust and Cost-Efficient Stream Processing Engine
Apache Spark Structured Streaming provides a fast, scalable, fault-tolerant, end-to-end exactly-once stream processing platform that allows users to program at a higher level. Qubole Pipelines Service adds the following capabilities to this platform:
- Scalable Stateful Streaming Applications: Apache Spark supports all sorts of stateful Applications – aggregation, deduplication, stream-stream join, etc. We have added support for pluggable state storage backed by RocksDB. The default memory-based state storage implementation in Open Source Apache Spark fails to scale when the state size increases beyond a point. With RocksDB state storage, the application can scale to billions of state records without any failures.
- Reliable Checkpointing: Checkpointing is a mechanism to ensure fault tolerance and correctness in stream processing by saving the metadata of the streaming application to a persistent store. We have added Direct-Writes and S3-Guard support to handle any eventual consistency issues during checkpointing.
- Enhanced Fault Tolerance: Qubole’s Apache Spark offering comes with executor taint management which prevents executor’s memory issues from crashing the application. In addition, the managed solution handles logs rolling and aggregation on the underlying file system and thereby prevents out-of-disk errors. Finally, we have added retries-on-failure to handle any intermittent but recoverable errors such as network connectivity, and system failures.
- Alert on Failures: Even after multiple retries, the application can fail because of bad data or any other fatal errors. Users can configure a notification channel – slack, pager-duty, email, webhooks – to get alerts on such failures.
Comprehensive Operational Management
- Cost Optimization: The managed solution leverages the goodness of spot nodes/preemptible nodes provided by various cloud providers. Users can select heterogeneous clusters of different instance types with any mix of on-demand and spot nodes. We have added graceful node decommissioning which utilizes spot loss signal to effectively adjust task scheduling and minimize the impact of the spot loss. This helps in running the workloads in the most cost-effective way.
- Monitoring and Alerting: We have added out-of-the-box integration with Prometheus/Grafana for monitoring streaming applications. Users can track key metrics such as micro-batch latency, processing rate, and state store size. In addition to that, we have added offset lag for various common input data sources to indicate how far the application is behind the tip of the input stream. This will help in tuning the application. Users can set up alerts on these metrics from the Grafana dashboard.


- Streaming Application Insights: We have added an event pane to provide 360-degree insights into the streaming applications. We keep a track of the streaming application and provide key information about it – How is the application performing? Is it waiting for any input data? Is the cluster size adequate or do you need to re-balance worker nodes to meet your SLAs?
- Access Controls: The Pipelines Service allows granular access controls on CRUD operations over the Pipeline artifacts. These controls facilitate the creation and governance of the administrator.
Data Management and Consistency
- Auto Compaction: Over a period of time, a streaming application can create a lot of small files in the data lake which impacts downstream read operations. We have added auto-compaction to periodically merge these small files into larger base files. The managed service has deep integration with Qubole ACID tables which enables such compaction without blocking concurrent reads and writes. This significantly simplifies the data lake operations and improves the performance of downstream SQL analytics.
- Error Sink: Schema evolution in the input data sources can lead to data inconsistency. We had added support for detecting schema mismatch and invalid records in the input data stream. We filter such records and write the metadata of the bad record along with the exception message in a configurable cloud storage location. The user can set alerts, and prevent data loss by cleansing and reprocessing these erroneous records.
Summary
Qubole Pipelines is an enterprise-grade stream processing service that complements your data lake with advanced capabilities to help you quickly ingest and process streaming data from various sources, accelerate the development of streaming applications, and run highly reliable and observable production applications in a managed environment at the lowest cost. It is available on all public clouds (AWS, GCP, Azure).
For a free 14-day test drive on Qubole, Start Free Trial now. To create your first pipeline on Qubole – follow this user guide. You can also get your hands dirty on our streaming analytics and other offerings, by registering for our upcoming events and workshops.



