Qubole is a leading provider of Hadoop as a service with the mission of providing a simple, integrated, high-performance big data stack that businesses can use to derive actionable insights from their data sources quickly. Qubole Data Service offers self-service and auto-scaled Hadoop in the cloud along with an integrated library of data connectors and an easy-to-use GUI designed to help users focus on their data and transformations while enabling data teams to provide a superior service to the consumers of analysis. Now, Qubole is partnering with Google Compute Engine to provide a fully elastic Hadoop service to Compute Engine featuring several advantages.
Auto-scaling and self-managed Hadoop
This elasticity is particularly useful in big data workloads as they are inherently bursty e.g. a 10 node cluster may be sufficient during certain times of the day while peak workload may require a 1000 node cluster. With Qubole Data Services’ auto-scaling abilities, this dynamic scaling up and scaling down of clusters becomes a reality leading to better resource utilization and hence users pay only for the resources that they truly need.
Performance and reliability
By taking advantage of Compute Engine’s fast spin up of virtual machines and consistent performance, Qubole Data Service brings increased data processing throughput to Hadoop workloads. A strong and performant infrastructure further amplifies the already superior performance of Apache Hadoop provided as part of the Qubole Data Service.
Fully integrated tools for Big Data
Qubole Data Service offers an integrated set of query tools, data pipeline and workflow tools and resource monitoring and management tools to enable a large number of analytic use cases. Qubole Data Service promotes the usage of data by a larger set of users in an organization by simplifying common analytics related tasks. Qubole Data Service can take advantage of the same cloud and datacenter infrastructure that powers Google’s services to handle large and ever-increasing workloads.
We present our findings of running Qubole Data Service and Hadoop on Compute Engine vs. a leading cloud provider (CloudX). In these performance experiments, we used the popular TPC-H dataset. We generated a TPC-H 75GB dataset using the dbgen utility. The data was in delimited text format and uploaded to CloudX’s object store and Google Cloud Storage.
We created external Hive tables against these datasets and used Hadoop’s filesystem implementations to access files in the object stores. As Hive does not support the original form of TPC-H queries, we ran a modified form of TPC-H queries in sequential fashion against both clusters. The complete set of DDLs and hive queries used is available in our public bitbucket repository via the following git command:
git clone ‘https://bitbucket.org/qubole/tpc…‘
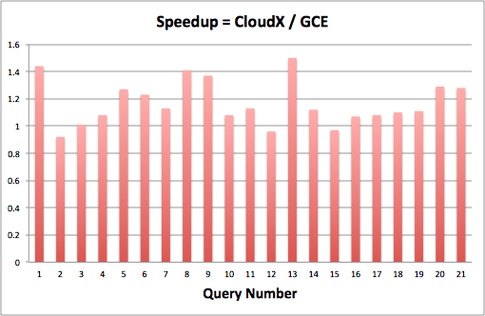
In the above graph, speedup is calculated as ratio of execution time in CloudX vs Compute Engine. Therefore, a value > 1 indicates that Compute Engine was faster. On an average, Compute Engine is 1.21x faster compared to CloudX. Most queries consistently showed better performance in Compute Engine compared to CloudX.
In conclusion, Qubole brings its Qubole Data Services to Compute Engine so that users looking for big-data solutions can take advantage of Compute Engine’s high-performance, reliable and scalable infrastructure and QDS’ auto-scaling, self-managing, integrated, Hadoop as a Service offering and reduce the time and effort required to gain insights into their business.
Are you interested in running Hadoop on Google Compute Engine? You may be eligible for $500 in Proof of Concept funding. Learn more about the program.
Note: Hadoop is a trademark of the Apache Software Foundation



