Machine Learning Juggernaut
Machine learning continues to be on a tear, fueled by the availability of data and compute capacity – especially in the cloud. A wide range of industry metrics points to the same conclusion. Here are some that I found insightful
- International Data Corporation (IDC) forecasts that spending on AI and ML will grow from $12B in 2017 to $57.6B by 2021.
- Machine learning patents grew at a 34% Compound Annual Growth Rate (CAGR) between 2013 and 2017, the third-fastest growing category of all patents granted.
- Deloitte Global predicts the number of machine learning pilots and implementations will double in 2018 compared to 2017, and double again by 2020.
In our customer base, I see a similar growth trend in machine learning use cases. Of our 200+ customers, almost everyone is already using Qubole for machine learning or is in the process of doing so to identify new revenue opportunities, drive process efficiencies or curtail risks.
Does machine learning need structured, semi-structured, or unstructured data?
Whether it’s a human being or a machine, the reality is that structured data is far easier to use. However, with the volume, variety, and velocity of data that gets created, the prevalence of unstructured data or semi-structured data is also a reality. This means that machine learning programs will access both structured and unstructured data and regardless of the vendor rhetoric (and sometimes we are guilty of that too), data lakes and data warehouses will play a pivotal role in machine learning.
Enabling Machine learning on the data warehouse with Qubole
As one of the world’s leading cloud-native platforms for machine learning, Qubole enables machine learning using Apache Spark on data stored in any data warehouse.
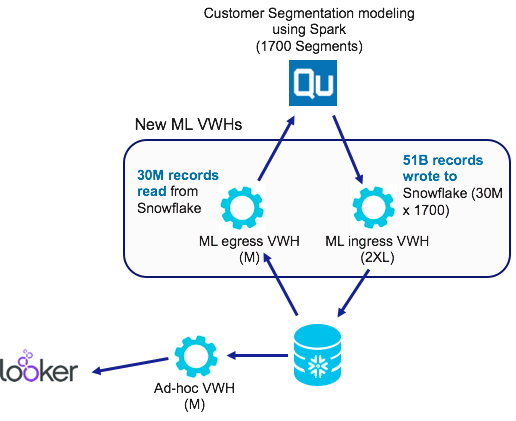
Earlier this year we jointly built a Qubole-Snowflake Apache Spark integration with Snowflake to enable data teams to build, train, and put in production powerful Machine Learning (ML) and Artificial Intelligence (AI) models in Spark using information stored in Snowflake. The integration also enables data engineers to use Qubole to read and write data in Snowflake for advanced data preparation such as data wrangling and data augmentation to refine existing Snowflake data sets.
Since its launch, the Qubole-Snowflake integration is used by several of our joint customers to deploy machine learning on Snowflake data leveraging Qubole’s Apache Spark capabilities. We also enable access to popular cloud data warehouses such as Azure SQL Data Warehouse or AWS Redshift.
I want to share a real-life example to demonstrate machine learning in the data warehouse. One of our retail customers is using machine learning to create customer segmentation for their next-generation personalization engine. They are using the Qubole-Snowflake connector to read 30 million records, classify these into 1700 different segments based on numerous attributes and write them back into the data warehouse. These granular segments are used for creating highly personalized product and promotion offers.
The future
As modern data management practices embrace the co-existence of data lakes and data warehouses, we will continue to see a trend where machine learning platforms evolve to access and process data from multiple disparate platforms for structured and unstructured data to support the digital enterprise.
At Qubole, we continue to pioneer innovation that breaks down the silos that prevent organizations from reaching their data activation potential.



