Structured Streaming API, introduced in Apache Spark version 2.0, enables developers to create stream processing applications. These APIs are different from DStream-based legacy Spark Streaming APIs. Yaroslav Tkachenko, a Software Architect from Activision, talked about both of these implementations in his guest blog on Qubole. While Structured Streaming came as a great improvement over legacy Spark streaming, support for in-built data sources is still limited.
In particular, there is no support for Kinesis as an input source or output sink in Structured Streaming, unlike legacy Spark Streaming. A lot of our customers at Qubole use AWS Kinesis to collect data, and it was not an option for them to move away from Kinesis to use Structured Streaming. To meet this demand, we built a connector for Structured Streaming to read from Kinesis. We open sourced the connector, which is available on Github as kinesis-sql module.
Structured Streaming in Apache Spark
Structured Streaming has a micro-batch model for processing data. The user can specify a trigger interval to determine the frequency of the batch. In each trigger, the Spark driver first determines the metadata to construct a new batch, plans its execution, and then finally converts the plan into tasks that are executed by the Spark executors.

Structured Streaming provides an interface that a new data source connector needs to implement to provide read support. In particular, a data source connector needs to implement methods to:
- Determine the range of records that need to be processed in a batch
- Read data from the source during batch execution
Implementation of Kinesis Connector
User applications push data into different shards of a Kinesis Stream. A Spark cluster consists of a driver process, which acts as a coordinator, and various executor processes that perform the task execution.
At the beginning of each trigger interval, the connector determines the latest description of all available shards in the stream using describeStream API. It then determines the position to read from in each shard.
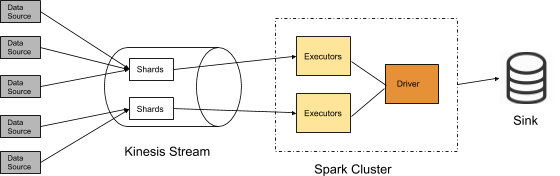
During a micro-batch execution, each shard is mapped to one worker responsible for reading data. The worker uses the GetRecords API to fetch records from the starting position for a shard.
A real-time application must provide insights faster, often within milliseconds to seconds from the micro-batch trigger. We need to make sure that the input data is read, processed, and available to the output sink immediately. So we have added some configurable constraints while reading data. By default, the reader task:
- Reads up to 100,000 records per trigger
- Spends less than 1 second per trigger
- Stops looking for more records if it has hit the tip of the stream or if the shard is closed
At the end of each task, each worker records the metadata about the last record read for each shard in some centralized storage. This information is used by the driver in the construction of the next micro-batch.
How to Use the Connector
Kinesis Setup
Refer to Amazon Docs for more options.
Create Kinesis Stream:
$ aws kinesis create-stream --stream-name test --shard-count 2Add records in the stream:
$ aws kinesis put-record --stream-name test --partition-key 1 --data 'Kinesis' $ aws kinesis put-record --stream-name test --partition-key 1 --data 'Connector' $ aws kinesis put-record --stream-name test --partition-key 1 --data 'for' $ aws kinesis put-record --stream-name test --partition-key 1 --data 'Apache' $ aws kinesis put-record --stream-name test --partition-key 1 --data 'Spark'
Example Streaming Job
Referring $SPARK_HOME to the Spark installation directory. You can compile the connector for Spark version 2.4.
git clone [email protected]:qubole/kinesis-sql.git git checkout 2.4.0 cd kinesis-sql mvn install -DskipTests
Open Spark-Shell:
$SPARK_HOME/bin/spark-shell --jars target/spark-sql-kinesis_2.11-2.4.0.jar
Subscribe to Kinesis Source
// Subscribe the "test" stream
scala> :paste
val kinesis = spark
.readStream
.format("kinesis")
.option("streamName", "spark-streaming-example")
.option("endpointUrl", "https://kinesis.us-east-1.amazonaws.com")
.option("awsAccessKeyId", [ACCESS_KEY])
.option("awsSecretKey", [SECRET_KEY])
.option("startingposition", "earliest")
.load
Check schema:
scala> kinesis.printSchema root |-- data: binary (nullable = true) |-- streamName: string (nullable = true) |-- partitionKey: string (nullable = true) |-- sequenceNumber: string (nullable = true) |-- approximateArrivalTimestamp: timestamp (nullable = true)
Word count:
// Cast data into string and group by data column
scala> :paste
kinesis
.selectExpr("CAST(data AS STRING)").as[(String)]
.groupBy("data").count()
.writeStream
.format("console")
.trigger(Trigger.ProcessingTime(“2 seconds”)
.outputMode("complete")
.start()
.awaitTermination()
Congratulations! You have just created your first Spark Structured Streaming query against the Amazon Kinesis stream. You can see the output in Console:
+------------+-----+ | data|count| +------------+-----+ | for| 1| | Apache| 1| | Spark| 1| | Kinesis| 1| | Connector| 1| +------------+-----+
You can also try out another example using the following notebook.
Configuration for Production Use Cases
- Resharding of Kinesis Streams
Kinesis Streams support merge and split shards operations. The connector uses DescribeStream API to check for new shards during every micro-batch creation. This API has a limit per AWS account. If re-sharding is not frequent in your stream, you can avoid such checks by increasing the value of kinesis.client.describeShardInterval to a higher value (say 3600s). - Throughput versus latency
kinesis.executor.maxFetchTimeInMs and kinesis.executor.maxFetchRecordsPerShard controls the time spent during batch executions. If the event ingestion rate into Kinesis is high, we can increase the value of these configurations. If end-to-end latency is of higher importance, we can decrease the value.
The list of other configurations with its default values can be found here.
Conclusion
The connector is open source (Apache license) and available on GitHub, and is actively used by data engineers. The README file describes how you can build the connector against a specific version of Spark and install the binaries. We have already received multiple contributions from users in this project, including the support of Kinesis as output sink. If you have any questions or suggestions, please leave a comment on GitHub.
At Qubole, there are many more exciting functionalities and enhancements that we are continuously working on to make our streaming customers’ lives easy. You can also check out how to get started with Structured Streaming on Qubole with Amazon Managed Kafka and how we have handled reliability in managing streaming workloads in the cloud.
Test drive Qubole today to try Apache Spark Streaming on Qubole yourself.



