Execution engines like M/R, Tez, Presto, and Spark provide a set of knobs or configuration parameters that control the behavior of the execution engine. In this article, we will describe an approach to determine a good set of parameters for SQL workloads and some surprising insights that we gained in the process.
It is tricky to find a good set of parameters for a specific workload. The list of parameters is long and many of the parameters are correlated in unexpected ways. For example, in M/R, mapper memory and input split size are correlated since a good value for the memory parameter depends on the split size.
Typically the ETL engineer will determine a set of parameters after analyzing a few important workloads. These parameters may not be optimal for all workloads. Moreover, as the queries and data change, the parameters may not be optimal over time. An automated approach that can recommend an optimal set of configuration values for each workload is the only scalable option.
The summary of our research is:
- The optimization function should be a function of dollar cost and throughput. Admins typically focus on one of them leading to sub-optimal configurations.
- In general, execution engine configuration is sub-optimal in the field. In every experiment, a large fraction of the queries could be optimized by > 60%. This points to the fact that manual efforts to choose optimal configuration falls short in most cases.
- Optimal configuration can be determined by running a workload iteratively with different values but the methodology is too expensive and impractical.
- A simple model of the execution engine provides very good recommendations for SQL workloads. The model eliminates the need for actual execution.
- The model is generic and is applicable to all of M/R, Tez, Presto and Spark engines.
- The model can be used to automate and provide insights and recommendations for engine configuration.
Related Work
Existing approaches to search for optimal configuration can be broadly classified into two types:
- Iterative Execution: In this approach, jobs are executed multiple times with different configuration parameters to arrive at the optimal configuration. As the parameter space is huge, these approaches focus on techniques to converge towards a good configuration using a lesser number of steps. For example, Sandeep et al [3] use a gradient named `noisy gradient` to converge to a solution and apply stochastic optimization to parameter tuning.
- Mathematical Model: In this approach, a mathematical model is used to predict the runtime/cost of jobs for a particular configuration. The search over the parameter space to find the optimal configuration can then be performed using the model, without having to actually run the job. Examples of this approach are Starfish[1] and BigExplorer[2].
Qubole study for SQL workloads
The above methods optimize configuration from the perspective of an engine. The methods do not consider the type of workload – SQL or Programmatic (M/R or Scala code). The major advantage is that the methods are generally applicable. The major disadvantage is that the number of parameters is huge. The Spark Configuration page list more than 100 parameters. The list makes searching the parameter space or building a model hard. SQL workloads are easier to model because there are a finite set of operators and a small set of parameters are important as described in Model-Based Execution below.
Since a large fraction of customer workloads at Qubole are SQL queries run via Hive, Spark, and Presto, we focused on SQL Workloads.
Optimization methodology
We explored two options to search the space of configuration values: iterative execution and model-based execution.
The optimization function for both methodologies is
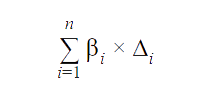
where n is the number of containers launched, ![]()
![]() and are container memory and execution time for ith container launched for the job respectively. The product is a proxy for the cost of running a container. The sum is a proxy for the cost of running a query.
and are container memory and execution time for ith container launched for the job respectively. The product is a proxy for the cost of running a container. The sum is a proxy for the cost of running a query.
We chose this metric as it represents the memory and CPU resources consumed and correlates to both the dollar cost and throughput of the big data stack.
We focused on parameters that control parallelism and memory per task. These classes of parameters have the biggest impact on SQL workloads. The specific parameters for M/R and Spark engines is given in the table below:
| M/R | SPARK |
| mapreduce.map.memory.mbmapreduce.reduce.memory.mb mapreduce.input.fileinputformat.split.maxsize mapreduce.input.fileinputformat.split.minsize hive.exec.reducers.bytes.per.reducer | spark.executor.coresspark.executor.memory spark.hadoop.mapreduce.input.fileinputformat.split.maxsize spark.hadoop.mapreduce.input.fileinputformat.split.minsize spark.sql.shuffle.partitions spark.sql.autoBroadcastJoinThreshold |
Iterative Execution
In this method, we ran Hive queries with various configuration parameters and chose the best among them. We employed the following strategies to reduce the parameter space:
- Parameter reduction: As described above, we focused on a small set of configuration parameters.
- Discretization: We further discretized each parameter so that we try few values rather than all possible values for each parameter.
- Reduce search range: For each parameter, there could be a large range of values that are significantly worse. We limited the search to within a good range for each dimension using heuristics. We identified a range by talking to experts.
- Assume dimension independence: To prevent parameter space explosion due to correlation we ignored their dependence on each other.
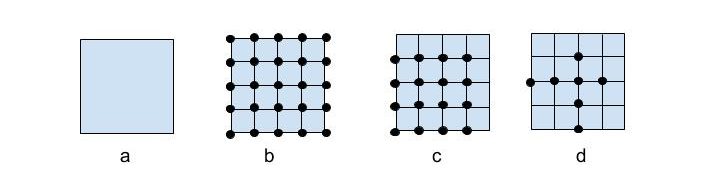
We implemented an iterative algorithm that searched the space of all configuration values based on these constraints. The figure above shows the steps to search optimal values for two parameters.
- The search space for two parameters
- Discrete values are explored in both axes
- Search space is restricted based on domain knowledge
- The algorithm iterates through each parameter to choose the optimal point and then moves to the next parameter.
Experimental Results:
We used the algorithm to optimize 3 customer Hive Queries. We observed the following percentage reduction over settings chosen by the Database Admins :
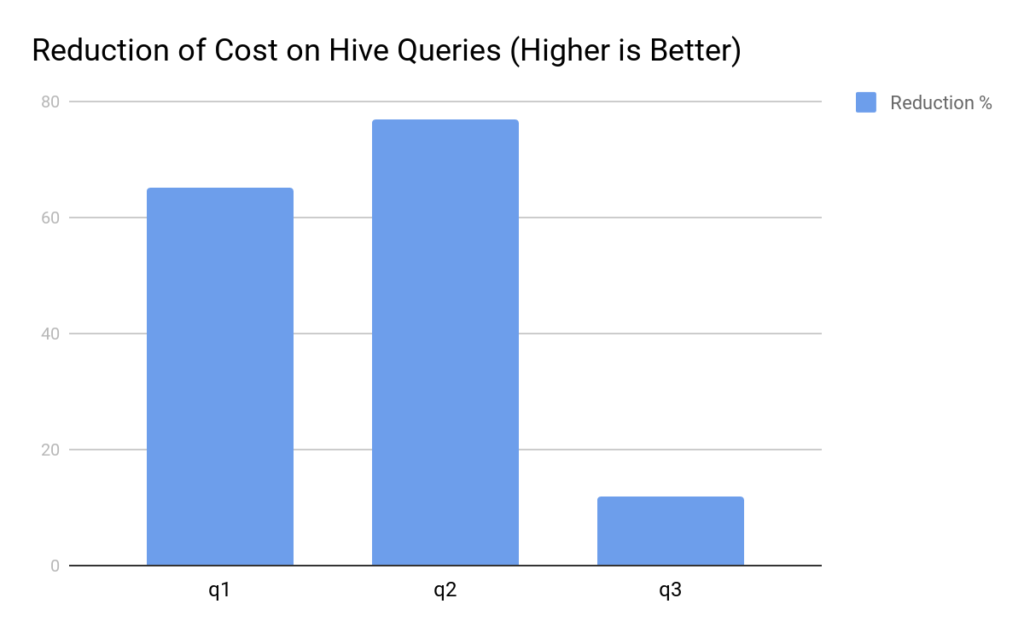
We saw very good improvement in our cost metric. However, this method has two major disadvantages:
- Cost: The experiment cost $5000. The customer had 1000 more queries. It is possible to make the search more efficient and reduce the number of iterations. Since customers have 100s or 1000s of queries, even a 10 or 50 fold reduction is not sufficient to make the approach economical.
- Shadow clusters and tables: For ETL queries, the approach requires shadow clusters and queries. The queries had to be reviewed multiple times to make sure production clusters and tables were not affected. The cost in terms of man-hours was also exorbitant.
Model-Based Execution
Since iterative execution is impractical at scale, we considered a model-based approach to eliminate the execution of queries. We created an execution model that replicated an execution engine. The model is based on the reduced set of parameters only and is therefore relatively simpler to other approaches.
The cost model also takes statistics about data sizes and selectivities of various operators as input. There are two ways to get these statistics:
- Collect metrics from a previous run. This approach is suitable for ETL or reporting queries. In QDS, these metrics are available in the Qubole Data Warehouse.
- Statistics from database catalog. This approach is suitable for ad-hoc queries. In QDS, customers can collect these statistics by turning on Automatic Statistics Collection.
The model outputs the result of the optimization function described above.
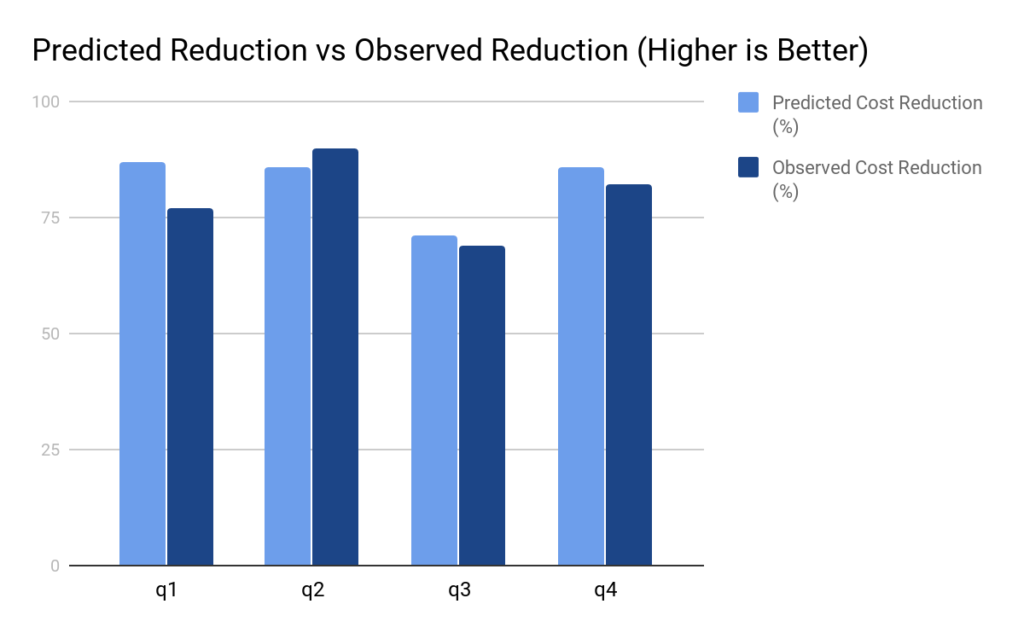
Experimental Results:
To quantify the prediction error by the model, we ran an experiment on 4 queries of a customer. The graph below shows the benefit predicted by our model and the actual observed benefit for these queries. The actual savings closely match the predicted savings indicating that the model is sufficiently accurate.
Key Insights to optimize workloads
We gained a few key insights to optimize SQL workloads through multiple experiments and trials on customer queries. These are in order of priority:
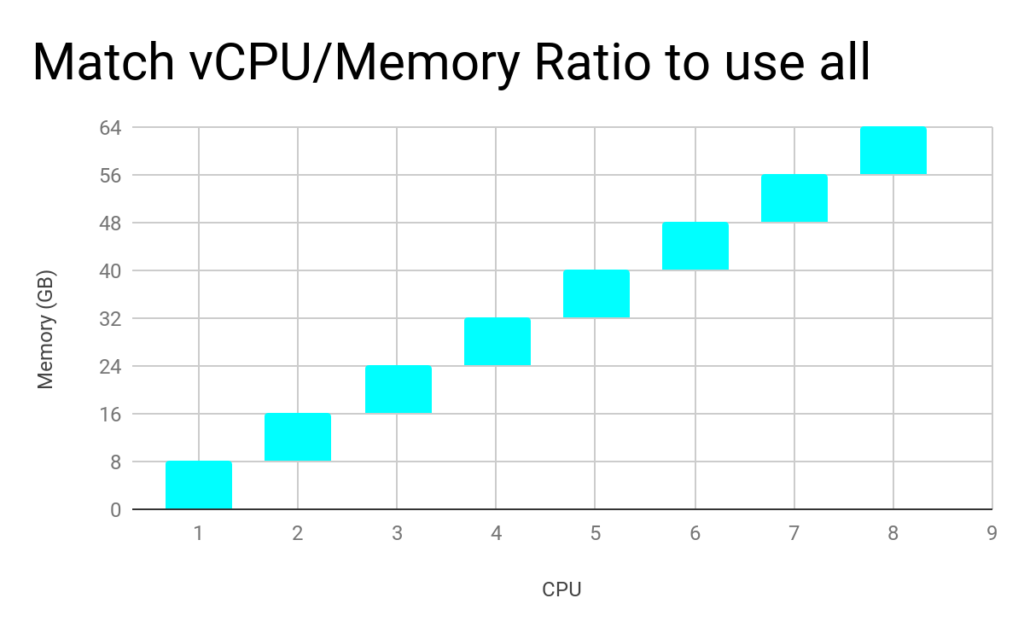
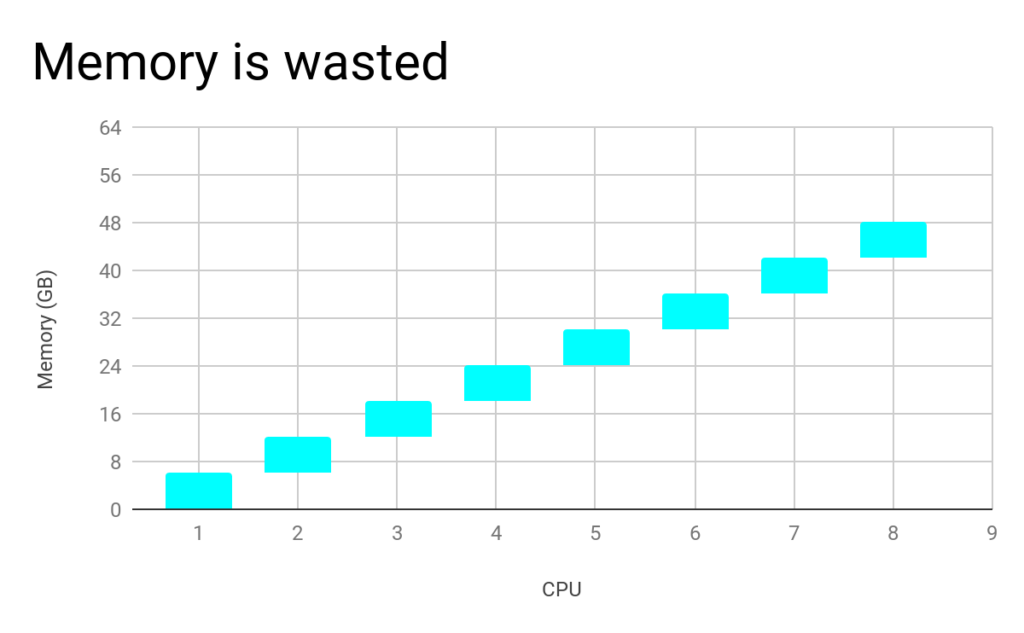
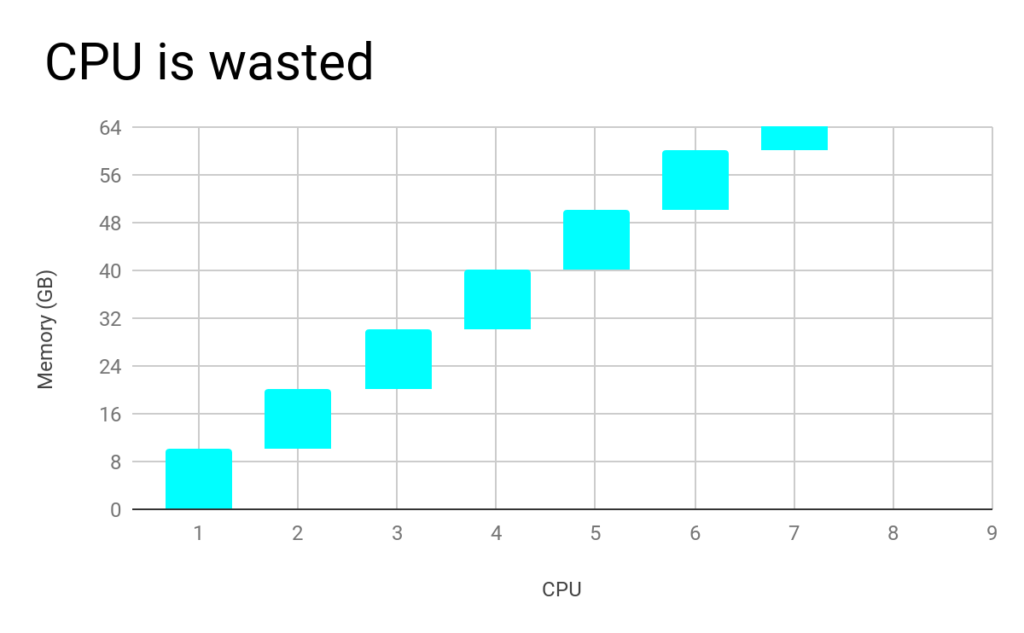
- Container Shape should match the Instance Family shape
Yarn allocates containers on two dimensions – memory and vcpu. Each container is given 1 vcpu and some memory. The memory/vcpu of the containers should match the memory/vcpu ratio of the machine type. Otherwise, resources are wasted!
- Avoid spills in tasks
Spills are expensive because each spill leads to an extra write and read of all the data. Spills should be avoided at all costs. Spills can be avoided by providing adequate memory to each task.
- Decrease memory per task to choose a cheaper instance type
On cloud platforms, machines with higher memory/CPU are more expensive for the same CPU type. Decrease the memory per task and consequently increase parallelism to choose a cheaper instance type. As long as tasks do not spill, the total work done in terms of IO, CPU, and network traffic is independent of the parallelism factor of the tasks. For example, the total data read and processed will be the same if the number of mappers is 100 or 1000.
If a job can be tuned to avoid spills on a cheaper instance with the same compute but lesser memory than the original instance, then it is generally a good idea to move to a cheaper instance for saving cost without any performance degradation.
- Beware of secondary effects of high parallelism
On the other hand, parallelism cannot be increased indefinitely. There are secondary effects of increasing the number of tasks. For example, every task has to pay the cost of JVM start if applicable. Also, there is an increase in a number of communication channels. Thus parallelism should be not be set so high that secondary effects drown the increase in performance. This limit is specific to a workload or query and cluster configuration and can be determined algorithmically.
- For Spark, prefer fat executors
This insight is specific to Spark, where there is an additional parameter of cores per executor. Given a certain number of cores per machine, we have a choice of either running many executors with fewer cores per executor (thin executors), or fewer executors with more cores per executor (fat executors). We have observed that for Spark, fat executors generally provide better performance. This is because of several reasons such as better memory utilization across cores in an executor, reduced number of replicas of broadcast tables, and lesser overheads due to more tasks running in the same executor process.
Stay Tuned
This automated discovery of insights using the simple cost model for SQL workloads, the data collected through AIR Infrastructure, and automatic statistics collector will also be implemented for non-SQL workloads such as data science and machine learning.
If you’re interested in QDS, sign up today for a risk-free trial.
References
- Herodotou, H., Lim, H., Luo, G., Borisov, N., Dong, L., Cetin, F.B. and Babu, S., 2011, January. Starfish: A Self-tuning System for Big Data Analytics. In Cidr (Vol. 11, No. 2011, pp. 261-272).
- Chao-Chun Yeh, Jiazheng Zhou, Sheng-An Chang, Xuan-Yi Lin, Yichiao Sun, Shih-Kun Huang, “BigExplorer: A configuration recommendation system for big data platform”, Technologies and Applications of Artificial Intelligence (TAAI) 2016 Conference on, pp. 228-234, 2016, ISSN 2376-6824.
- Sandeep Kumar, Sindhu Padakandla, Chandrashekar L, Priyank Parihar, K Gopinath, Shalabh Bhatnagar: Performance Tuning of Hadoop MapReduce: A Noisy Gradient Approach https://arxiv.org/abs/1611.10052



