Presto, Apache Spark, and Apache Hive can generate more efficient query plans with table statistics. For example, Spark, as of version 2.1.1, will perform broadcast joins only if the table size is available in the table statistics stored in the Hive Metastore (see spark.sql.autoBroadcastJoinThreshold). Broadcast joins can have a dramatic impact on the run time of everyday SQL queries where small dimension tables are joined frequently. The Big Bench tuning exercise from Intel reported a 4.22x speedup by turning on broadcast joins for specific queries.
In QDS, all the query engines use Hive Metastore as the catalog. If the Hive Metastore contains statistics, then all query engines can use them for query planning as exemplified above. But table statistics collection is not automatic. One of the goals of the Qubole platform is to apply automation to help users achieve maximum performance and efficiency. This blog post describes how we have automated Table Statistics collection in Qubole Data Service (QDS).
Table Statistics in Hive
The Apache Hive Statistics wiki page contains a good background on the list of statistics that can be computed and stored in the Hive metastore. Since statistics collection is not automated, we considered the current solutions available to users to capture table statistics on an ongoing basis. These are described below:
| Solution | Pros | Cons | |
| 1 | User sets hive.stats.autogather=true to gather statistics automatically during INSERT OVERWRITE queries. |
|
|
| 2 | User schedules ANALYZE TABLE COMPUTE STATISTICS User picks up a few tables they want to keep stats updated and then uses Qubole Scheduler (or an external cron job) to run the COMPUTE STATISTICS statement on these tables periodically. |
|
|
As we can see, both of the available approaches have major gaps. This prompted us to build statistics collection into the QDS platform as an automated service.
Statistics Collection Service
The requirements for the collection service are:
- Use ANALYZE COMPUTE STATISTICS statement in Apache Hive to collect statistics.
- ANALYZE statements should be triggered for DML and DDL statements that create tables or insert data on any query engine.
- ANALYZE statements should be transparent and not affect the performance of DML statements.
ANALYZE .. COMPUTE STATISTICS comes in three flavors in Apache Hive. The three flavors are described in the table below.
| SQL Statement Example | Metadata Colfulected | Impact on Cluster | |
| 1 | ANALYZE TABLE [db_name.]tablename [PARTITION(partcol1[=val1], partcol2[=val2], …)] COMPUTE STATISTICS NO SCAN |
| Very fast, nearly zero impact on the cluster running workloads |
| 2 | ANALYZE TABLE [db_name.]tablename [PARTITION(partcol1[=val1], partcol2[=val2], …)] COMPUTE STATISTICS | (in addition to the above)
| Will scan entire table or partition specified, moderate impact |
| 3 | ANALYZE TABLE [db_name.]tablename COMPUTE STATISTICS FOR COLUMNS |
| Significant Impact |
Each flavor requires different compute resources. Another requirement for this feature is then:
- Allow users to decide the statistics appropriate for each table.
In the first version, users can choose the flavor at the account level. In the future, we will let users configure the flavor at a table or schema level.
Architecture Diagram
The diagram below shows how to ANALYZE COMPUTE STATISTICS statements are triggered in QDS (In Hive Tier case):
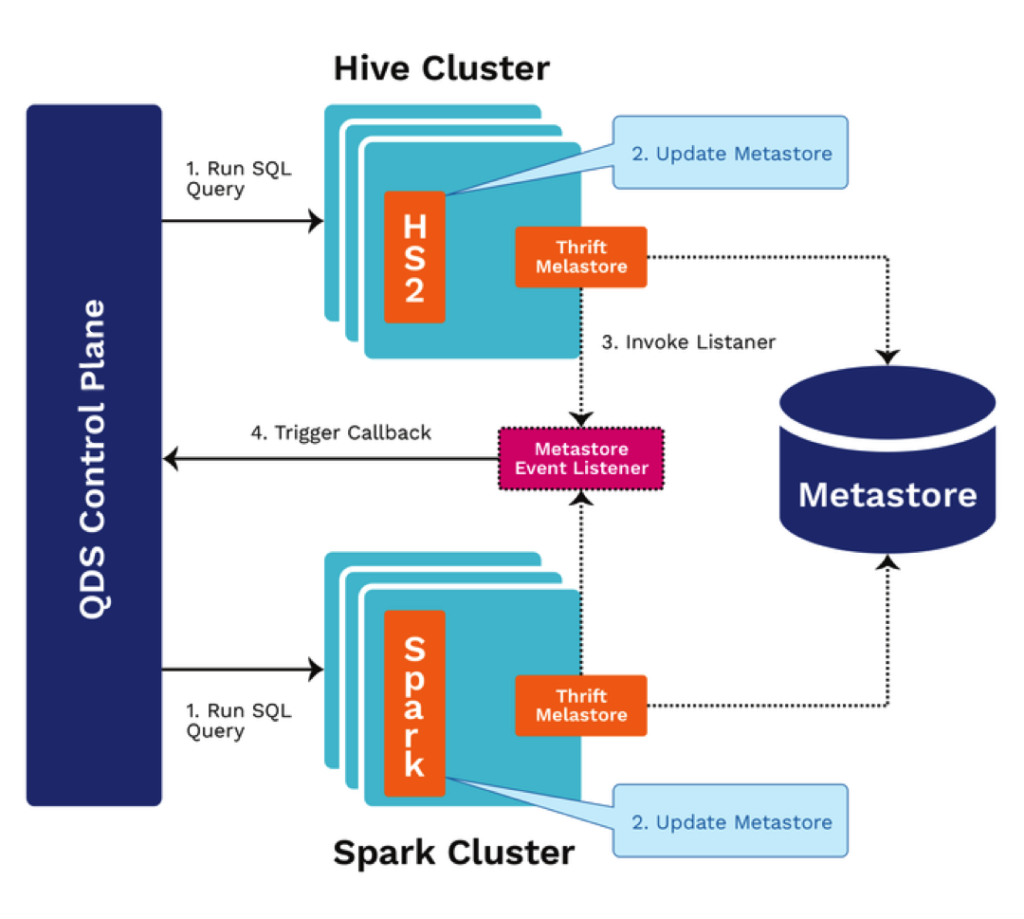
- A user issues a Hive or Spark command.
- If this command is a DML or DDL statement, the metastore is updated.
- A custom MetastoreEventListener is triggered.
- The triggers call back to the QDS Control plane and launch an ANALYZE command for the target table of the DML statement. Internally, the ANALYZE query will be executed like any other Hive command on the cluster on which the user issued the original command.
Throttling & Batching
As we have described before – running Analyze commands takes compute bandwidth and has cost and performance implications (for other applications). There are limits on the number of concurrent ANALYZE COMPUTE STATISTICS commands. There are three tiers:
- Global limit: Controls concurrency across the QDS control plane
- Account limit: Controls concurrency within each QDS account
- Table limit: Controls concurrency for each table
Limits at the account and table level are not exposed to administrators right now – but will eventually be.
If the service receives multiple triggers for the same table/partition/column, the triggers will be consolidated into one ANALYZE command. For example, if a DML statement adds many partitions, multiple requests are received by the QDS control plane within a very short time span. These requests will be batched up and a single command will compute statistics for all the new partitions.
Status and Future work
Automatic Statistics Collection is now available on the QDS Platform for Beta usage. Please contact Qubole Support at [email protected] to try this out. We have seen a significant performance boost for analytic queries in Apache Hive and SparkSQL using table statistics and we are working with the Presto community to incorporate statistics in Presto query planning as well.
Qubole recently announced AIR (Alerts, Insights, Recommendations) in Data Platforms 2017. Automatic Statistics Collection will play a key part in our autonomous data platform. Some examples of use cases within AIR are:
- Users will be able to see table statistics in the preview.
- The QDS platform can give recommendations and insights on better partitioning or data organization strategies to data engineers, architects, or admins based on statistics.
References
- Tuning and Optimizing an end to end benchmark, Yi Zhou, Intel SSG/STO/Big Data Technology
- Apache Hive Statistics – Apache Hive Wiki



