This post is a guest publication written by Wesley Goi, a Data Scientist at Honestbee. A version of this post first appeared on Medium’s Data Science blog.
Honestbee is an online grocery and food delivery service featuring items from 10,000+ restaurants, supermarkets, and specialty stores. Honestbee 🐝 stores event logs capturing user data in AWS S3 as a part of our data lake, which is delivered from Segment at 40-minute intervals. Learning how to retrieve such data is important because the data science team uses these logs to evaluate the performance of our machine learning models (AKA canonical A/B testing). In addition, we also use the same logs to track business Key Performance Indicators (KPIs) like Click-Through Rate, Conversion Rate, and Gross Merchandise Volume (GMV).
What should the go-to weapon of choice be when you have a large number of event logs to parse? Below I share my experience of using Apache Spark/Sparklyr to tackle this problem. In this article, I will share how we leverage high-memory clusters running Spark to parse such logs generated from Honestbee’s Food Recommender System.
Case Study: Food Recommender System
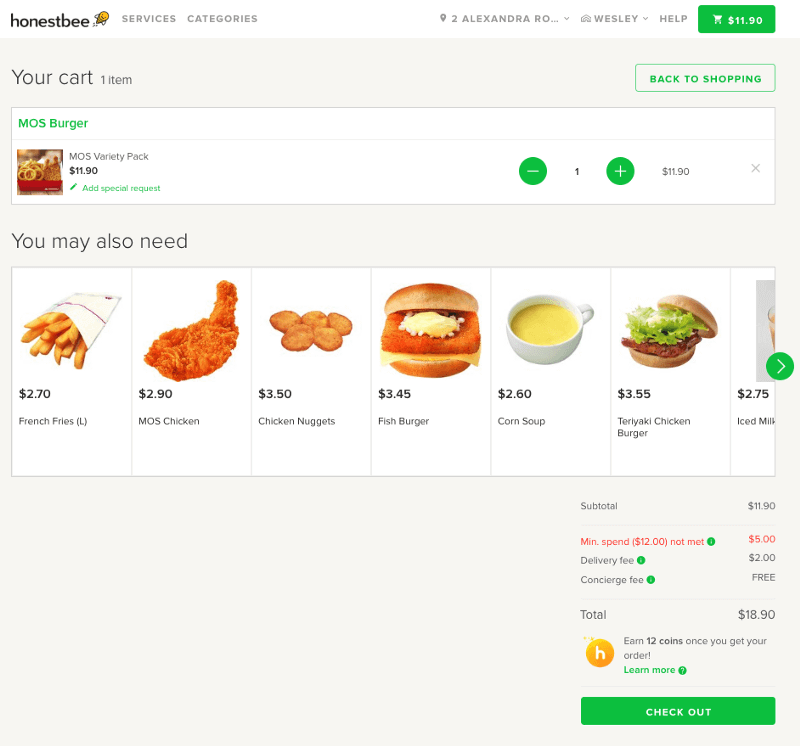
When an Honestbee customer proceeds to checkout, our Machine Learning (ML) models make personalized predictions about which items the customer is most likely to add to their cart, especially items they may have missed. The screenshot below demonstrates these models at work, in this case offering additional food recommendations to a customer with a burger in their cart.
Let’s dive into how I used Spark/Sparklyr to analyze event logs from the Food Recommender System. A postmortem will require us to look through the logs to see which treatment group, based on a weighted distribution, a user has been assigned to. First, we need to import the necessary libraries:
Connecting to the High-Memory Spark Cluster
Next, we’ll need to connect with Spark, the master node. I recommend playing with a local machine before moving on to a local cluster and finally a remote one.
Installing Spark
If you haven’t already installed Spark, sparklyr includes a built-in function to help with the installation:
spark_install( version = "2.4.0", hadoop_version = "2.7" )
Notice that we are also installing Apache Hadoop with Spark because the jar required to read files from the S3 filesystem comes with it.
Local Cluster / Single Node Box
Next, you’ll connect to the Spark cluster — i.e. establish a Spark Connection, often abbreviated as SC.
If you’re connecting to a locally installed Spark cluster/single-node box, you’ll set the master parameter as local. (See below for details about connecting to a local Spark cluster.)
You might need to play around with the memory consumption. I’ve set it to 150 GB, but your mileage might vary depending on your box.
Running Spark on a laptop, or as a single-node installation on a larger cloud instance, is perfectly fine. Honestbee’s data science team does not own or manage a cluster; instead, we run Spark on a really large single-node EC2 instance mainly for prototyping and Exploratory Data Analysis (EDA). However, when the job becomes too large, you’ll probably want to consider something more heavy-duty like a proper cluster.
Remote Clusters
The option of connecting with a remote Spot cluster might be appealing if you’re running a JupyterHub / Rstudio server, especially if you want one cluster provisioned for each data scientist. In such cases, the Python / R process is not running on the same master node of the cluster. Third-party Spark-as-a-Service providers like Qubole and Databricks can alleviate much of this. At Honestbee, we have also chosen to go with this option and the clusters are provisioned by Qubole under our AWS account. (P.S. Qubole’s a pretty good steal!)
The gist above sets up the Spark connection sc; you will need to use this object in most of the functions.
Separately, because we are reading from S3, we must set the S3 access keys and secret. This has to be set before executing functions like:
spark_read_json
Local clusters are generally good for EDA since you will be communicating through a REST API (LIVY).
Reading JSON logs
There are essentially two ways to read logs. You can read them as whole chunks or as a stream (as they get dumped into your bucket). You can use one of two functions: spark_read_json or stream_read_json.The former option is batched and the later creates a structured data stream. There’s also the equivalent of reading your Parquet files.
Batched
To read logs using the batched function, the path should be set with the s3a protocol: s3a://segment_bucket/segment-logs/<source_id>/1550361600000.
json_input = spark_read_json( sc = sc, name= "logs", path= s3, overwrite=TRUE )
Below is where the magic begins:
As you can see, it’s a simple query that requires the following steps:
- Filter for all
Added to Cartevents from theFoodvertical - Select the following columns:
CartIDexperiment_idvariant(treatment_group) andtimestamp
- Remove events where users were not assigned to a model
- Add new columns:
fulltime(readable time), andtime(the hour of the day) - Group the logs by service
recommenderand count the number of rows - Add a new column event with the value
Added to Cart - Sort by time
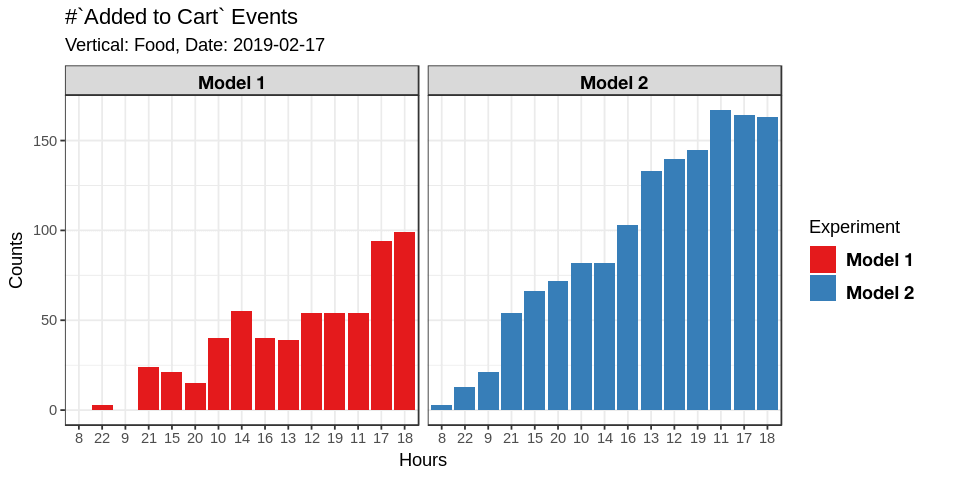
Here’s a plot of the output. We see that Model 2 is getting more clicks than Model 1.
Spark Streams
Alternatively, you could also write the results of the above manipulation to a structured Spark stream. You can preview these results from the stream using the tbl function coupled to glimpse.
sc %>%
tbl("data_stream") %>%
glimpseConclusion
And that’s it, folks! We’ve now successfully parsed event logs from the Food Recommender System using Spark/sparklyr and high-memory clusters. With this information in hand, the data science team can review how our machine learning models are performing and fine-tune the models based on those insights. We can also better measure KPIs like those mentioned earlier (click-through rate, conversion rate, and GMV).
Check out more use cases and firsthand stories from Qubole customers in the Customer Stories section of the blog.



