Customers often configure a small minimum size when autoscaling Presto clusters to save on costs. However, scheduling queries on a small cluster leads to query failures and degraded performance, since autoscaled nodes can take some time to join a cluster. To avoid this, some customers resort to configuring a higher minimum size for the cluster, which results in a higher cloud bill for these users. Furthermore, since Spot nodes are not supported in the core nodes of a cluster (i.e. nodes that comprise minimum nodes in the cluster), the cost impact of a high minimum size cannot be mitigated by using Spot nodes.
By default, Presto schedules all tasks of a query on the cluster as soon as the query has finished planning. Since the scheduler does not have awareness of the peak resource requirements of a query, it can end up executing a query on a cluster that does not have sufficient resources to finish the query. Automatic query retry in Presto on Qubole and Spill to Disk features can mitigate query failures in some cases, but they will still result in performance degradation. Current implementations of autoscaling in Presto clusters cannot solve this problem fully, because only source stage tasks of a query may utilize newly added nodes during the execution of a query.
Delaying Query Execution for Autoscaling
The Presto open source project recently introduced a mechanism in Presto to delay query execution until the cluster has a sufficient number of workers available to successfully execute the query. This feature introduces a cluster configuration override “query-manager.required-workers” that can be used to indicate the required number of worker nodes in the cluster before a query is scheduled for execution on the cluster. The feature also adds another configurable “query-manager.required-workers-max-wait” that controls the maximum time the Presto coordinator will wait for the worker nodes requirement to be met before failing the query. This mechanism is used as a building block in Presto on Qubole to solve the problems outlined above.
Qubole’s autoscaling has been modified to detect queries waiting to be scheduled for execution due to a minimum workers’ requirement not being met and can upscale the cluster to meet this demand. While nodes are being requested from the cloud provider and added to the cluster, queries will be queued on the Presto coordinator node. These queries will be visible as queries in the “Waiting for Resources” state in the Presto UI.
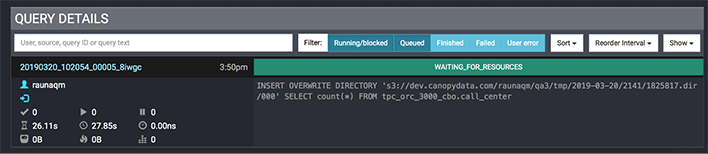
This feature enables users to reduce the minimum size of a cluster to one worker node. “query-manager.required-workers” can then be set to the older (and somewhat higher) value of the minimum size that was kept to ensure queries did not fail. This configuration enables cost savings with minimal impact on performance: the cluster will scale down to one node during idle periods and bring up the required nodes before executing the first batch of queries after an idle period.
Node bring-up times for on-demand EC2 instances in the Qubole Data Platform are typically in the range of 120 to 150 seconds. Depending on the availability of nodes from the cloud provider and the usage of Spot nodes in a cluster composition, we may fail to meet the minimum worker nodes requirement in the specified maximum waiting time. Therefore, we have modified our implementation to schedule queries on the cluster after the maximum waiting time has expired rather than failing the queries.
When the cluster upscales to meet the “query-manager.required-workers” requirement, the composition of the upscaled nodes will adhere to the existing Spot ratio configuration. This allows higher utilization of Spot nodes in the cluster as compared to a cluster with a high minimum size, which does not make use of this feature. Additionally, we have lowered the minimum configurable value of Spot request timeout for acquiring Spot nodes from your cloud provider to one minute. In case Spot nodes are not available, a lower value of Spot request timeout allows fallback to on-demand instances to happen sooner and reduces the waiting time for queries. When Spot nodes do become available, they are acquired and the extra on-demand nodes are gracefully removed from the cluster through the Spot node rebalancer available in Presto on Qubole.
External monitoring tools set up by customers as well as Qubole’s internal cluster monitoring systems often make use of trivial queries like “SELECT 1” and “SHOW SCHEMAS” for cluster health checks. Queries on JMX and system connectors may also be used for monitoring purposes. The current open-source implementation of this feature delays execution of all queries until the minimum workers’ requirement is met.
Queries on JMX, System, and Information schema connectors and queries like “SELECT 1”, “SHOW SCHEMAS”, “SHOW TABLES”, and other Data Definition Language (DDL) queries do not require multiple worker nodes to execute. We have modified our implementation to detect such queries and avoid delaying their execution or scaling up the cluster unnecessarily for them.
Qubole’s autoscaling will ensure that while queries are running on the cluster, “query-manager.required-workers” nodes will be maintained in the cluster. The cluster will downscale back to the configured minimum size after a cooldown period when there are no active queries.
Query Benchmarks on Presto
The test benchmark consists of a workload where the incoming load increases progressively for some time followed by an idle period. This is followed by another burst of queries where the load decreases progressively for some time followed by another idle period. The final part of the workload consists of a constant incoming load.
We perform three runs of this test benchmark with the following configurations:
- Minimum size 2, maximum size 12
- Minimum size 6, maximum size 12
- Minimum size 1, maximum size 12, and query-manager.required-workers set to 6
All three configurations make use of aggressive downscaling with the same node cooldown period of 10 minutes to take advantage of per-second billing and utilize the same target latency–based autoscaling heuristic.
The “Query Counters” graph on the left below plots the number of running queries observed over a period of time. The second graph on the right plots the number of worker nodes in the cluster over a period of time.
Config A: Low minimum size (2), Max Size (12)

Using low minimum size is the worst choice – results in the highest query latency (total time) and incurs the highest cost (node runtime)
Config B: High minimum size (6), Max Size (12)

Using a high minimum size provides good query latency (total time taken) but incurs a high cost (node runtime)
Config C: Low minimum size (1), Required workers (6), and Max size (12)

Using required workers results in the least cost (lowest node runtime) while still providing overall good query latency (total time taken is almost as good as Config B with high minimum size)
Total time taken records the time taken to finish the entire workload. A shorter time indicates better performance. Total node runtime records the cumulative runtime across all nodes in the cluster. With per-second billing, this number directly translates into the cost of running the entire workload. See the table below for a complete comparison of Configurations A, B, and C:
| Config A | Config B | Config C | |
| Total time taken | 5h 12m | 4h 26m | 4h 37m |
| Total node runtime seconds | 143137 | 134664 | 124351 |
| Min size | 2 | 6 | 1 (6 required nodes) |
Config A with a low minimum size exhibits poor performance because queries often arrive when the cluster is at its minimum size of two nodes. Although autoscaling is triggered in an attempt to meet target latency, its impact is limited as Presto is not able to redistribute non-source stages like join, aggregation, and sorting operations in a query onto newly added nodes after the query has started executing.
Config B with a high minimum size exhibits the best performance, but at the cost of always keeping six nodes up.
Config C using required workers is able to save costs by downscaling the cluster to one node during idle times. The waiting time introduced for acquiring nodes from your cloud provider is compensated by the queries executing more quickly on a larger cluster.
Conclusion
The required workers feature enables significant cost savings by providing a way to reduce the minimum size of autoscaling Presto clusters to one worker node and increase Spot node utilization in the cluster with limited impact on query performance. This feature is now available for use in Presto on Qubole versions 0.193 and 0.208. Check out our documentation for details on how to enable this feature.



