Co-authored by Jeffrey Ellin, Solutions Architect, Qubole.
In our previous post, we wrote about the on-demand ETL pipeline with AWS Lambda and Qubole to facilitate event-based processing of long-running ETL processes. In this blog post, we will show you how to do the same using AWS Data Pipeline and Qubole.
AWS Data Pipeline
AWS Data Pipeline helps you in moving data between different compute and Amazon resources. It has robust functionality for retries and conditional branching logic. This functionality, when coupled with ETL capabilities of the Qubole Data Service (QDS) platform, is an ideal combination for creating resource-optimized and cost-efficient ETL pipelines.
Big Data Analytics Use Case
To demonstrate this, we will review a fairly common big data analytics use case where the data is processed in S3 using Hive or Spark, and the output is published to Redshift. Storing the output in Redshift enables you to provide real-time analytical capabilities to end-users via visualization tools such as Tableau–while delegating the heavy lifting of ETL processes to Hive or Spark running on Hadoop.
In the diagram below, our example data pipeline is scheduled to run daily. The first thing it does is startup a t1.micro instance to process the workload. (Note that this pipeline could also be invoked with an AWS Lambda function.)
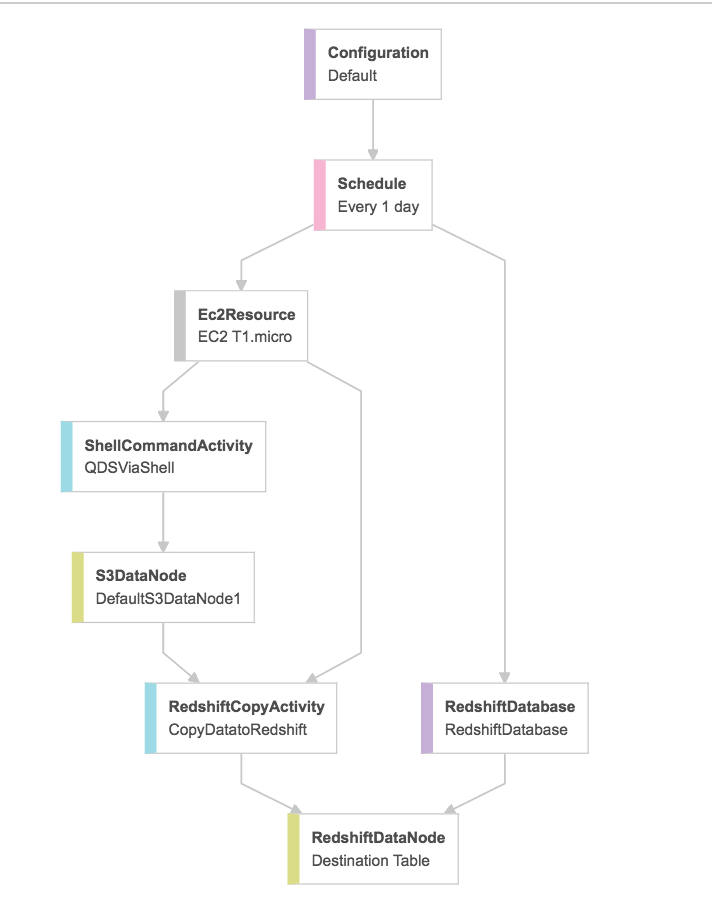
Once the cluster is up and running a shell command is invoked. This is the integration point between AWS Data Pipeline and QDS.
#!/bin/bash
#Qubole API Key
AUTH="redacted"
#Database Name
request_body=$(cat <<EOF
{
"input_vars":"[]"
}
EOF
)
#run template
curl -s -X POST \
-H "X-AUTH-TOKEN: $AUTH" \
-H "Content-Type:application/json" \
-d $(request_body) https://api.qubole.com/api/v1.2/command_templates/345/runThe above shell command will execute the ETL query and when it finishes, the data pipeline will begin exporting data to Redshift. Note that here there’s no need to manage the state of the cluster. If the cluster is not running, it will be started automatically and scaled appropriately by QDS. After the process is complete, the EC2 resources used by the pipeline will be released. The QDS Hadoop cluster will also begin to scale down or terminate altogether depending on how it’s configured.
One thing to keep in mind is that, unlike AWS Lambda, AWS Data Pipeline is not a server-less architecture. Generally speaking, your processing logic will run on an EC2 instance, and, at a minimum, you will pay for the resources that particular instance uses for 1hr. In the above scenario, the instance used to control the pipeline must remain up for the entire time it is executing. This is because of the polling step towards the end of the shell script. We must continue to block until the ETL process is complete and only then we can hand it off to the next step in the pipeline.
Drawbacks
Here are a couple of drawbacks of this server-less architecture approach:
- The EC2 resource used for the data pipeline will need to be running for the entire time the EC2 process is executing. This can add unnecessary cost to the process as the only thing happening on the EC2 instance is polling for job completion.
- If the resources that are required to launch the command are not available, you must wait for them to be finished and pay for a full hour of their existence.
Hadoop ETL
A more cost-effective and resource-efficient approach is to use the AWS Lambda function to execute a Hadoop ETL process when new data arrives in S3.
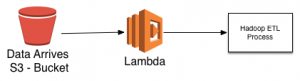
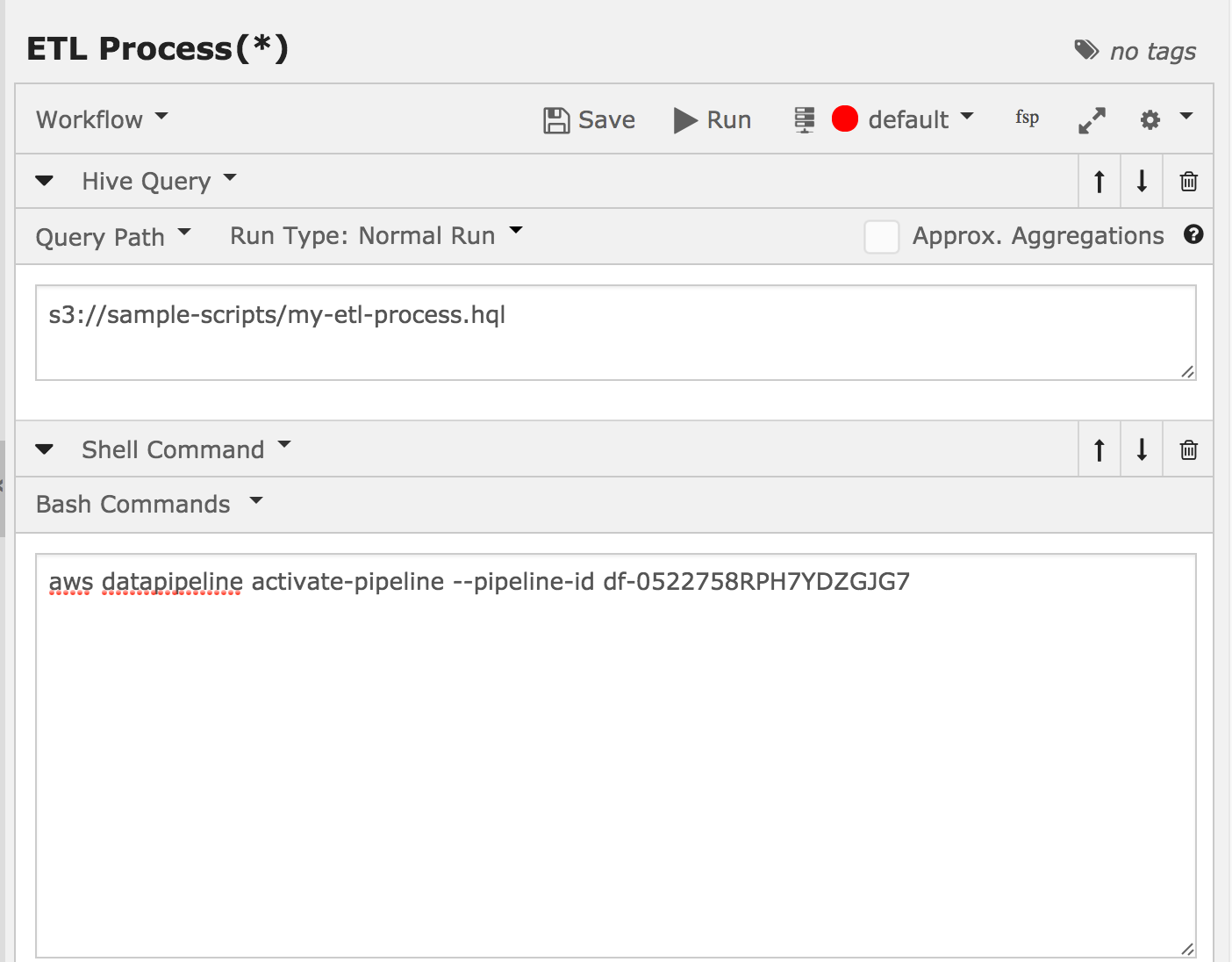
To achieve this, you can use the Workflow component of QDS which allows you to chain together multiple commands in sequence. Using Workflow, you can run your ETL script followed by an Amazon S3 API call to activate the data pipeline. (QDS will activate the pipeline when ETL process is complete.)
Since QDS does the heavy lifting, the Shell Command node in longer needed and can be removed from the data pipeline as shown below.
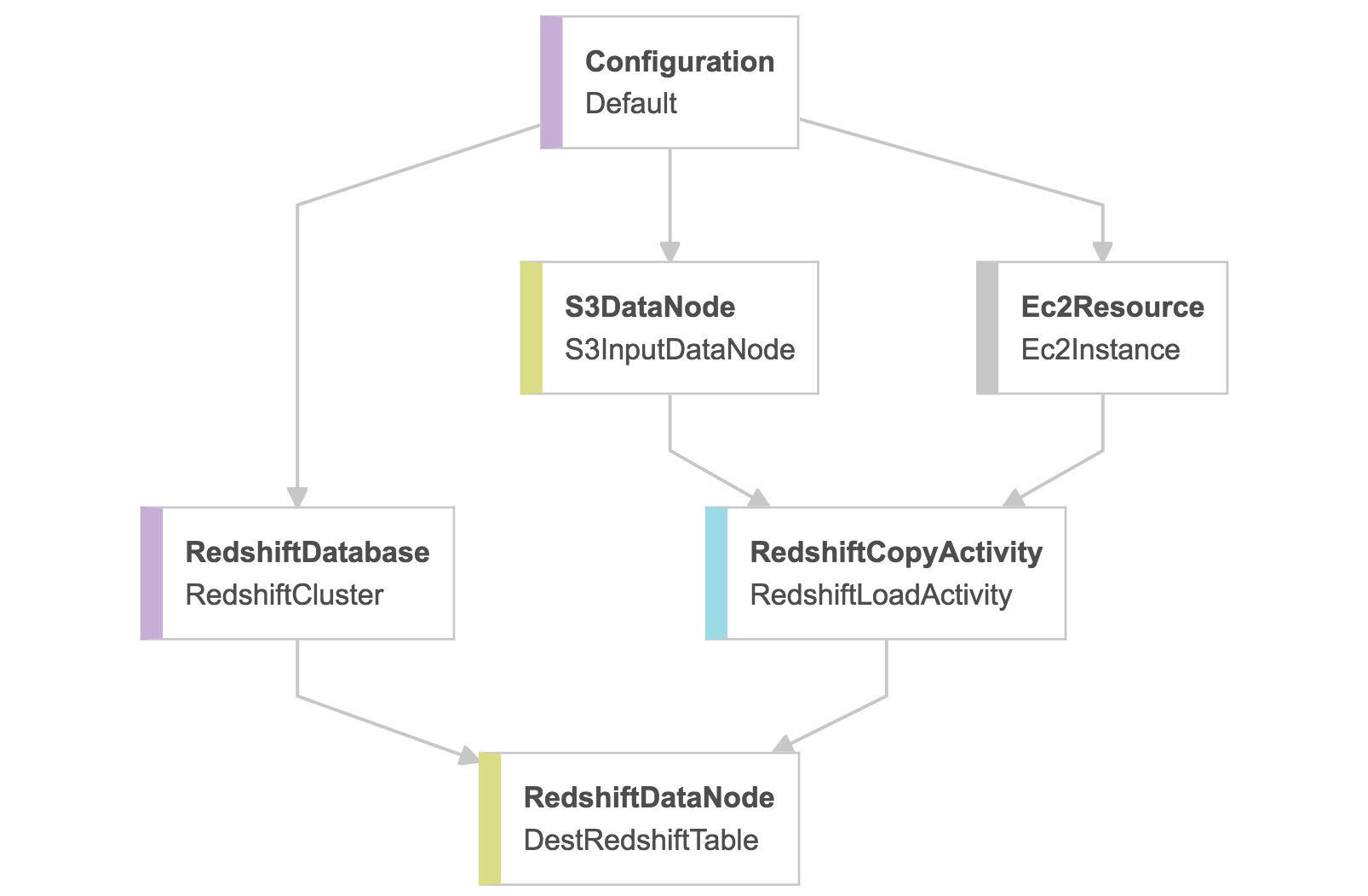
This approach allows you to keep EC2 resource usage to a minimum by starting the data pipeline instance only after the long-running ETL process is complete. In addition, the AWS Lambda function will automatically start the cluster on QDS if it is not already running and scale it appropriately. Once the process is complete, the cluster will automatically scale down and/or terminate if there are no other workloads.
Summary
In this post, we’ve shown you how to leverage and combine technologies to efficiently process Big Data workloads while reducing the number of resources consumed.
If you’re interested in QDS, sign up today for a free trial! To get an overview of QDS, click here to register for a live demo.



