AMAZON WEB SERVICES (AWS)
AWS on Qubole
Qubole has built the first cloud-native data platform for analytics, Artificial Intelligence (AI), and Machine Learning (ML) that is revolutionizing the way companies put their data to work on AWS.
Natively designed for Amazon Web Services (AWS) and tightly integrated with its storage, compute, security and other key architectural elements, Qubole Data Service (QDS) on AWS enables rapid deployment and on-demand scalability at a significantly lower cost than other solutions for implementing big-data projects in the cloud.

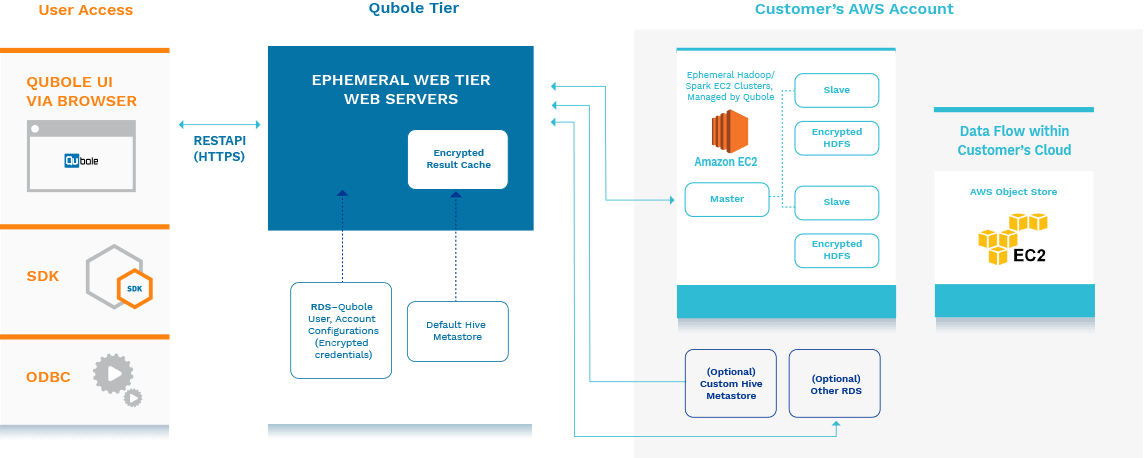
The Qubole Application Tier orchestrates resources on the customer’s AWS account using customer-provided and revocable IAM roles. Meta-data describing the data on S3 is stored in the Hive Metastore in the Qubole tier or, if required, on the customer’s account. Workload requests are submitted by users via a web-based Workbench or via Spark Notebooks, by external applications via REST APIs, and by third-party Business Intelligence products via ODBC/JDBC drivers. Query results are cached locally by Qubole for future re-use to minimize the use of computing resources.
Qubole on AWS Marketplace
Sign up for Qubole on the AWS Marketplace


