All data-driven organizations use data in three ways:
- To report on the past
- To understand the present
- To predict the future
Data warehouses and Business Intelligence (BI) tools support reporting and analytics on historical data while data lakes support newer use cases that leverage data for machine learning, predictions, and real-time analysis.
At Qubole, we have worked with more than 300 market-leading companies to address their data platform needs, and based on our experience, we can net the differences between the two technologies to the following points:
- Support for the diversity of use cases
- Support for the diversity of data types
- Open vs proprietary architecture
Support for the diversity of use cases
Data warehouses are purpose-built and optimized for SQL-based access to support BI but offer limited functionality for streaming analytics and machine learning. They are constrained by the ETL requirement to pre-process data prior to storing it. This makes it impractical, costly, and time-consuming to ingest data in real-time, or streams of data.
Machine Learning:
While some data warehouses extend their SQL-based access to offer machine learning functionality, they do not offer native support to run widely available, programmatic data processing frameworks such as Apache Spark, Tensorflow, and more.
In contrast, data lakes are ideal for machine learning use cases. They not only provide SQL-based access to data but also provide native support for programmatic distributed data processing frameworks like Apache Spark and TensorFlow through languages such as Python, Scala, Java, and more.
Streaming Analytics:
Stream analytics enables the ingestion, processing, and analysis of data in real-time without requiring data to be stored prior to analysis. Unlike other forms of data, the value of streaming data diminishes with the passage of time.
Data warehouses require sequential ETL to ingest and transform the data prior to its usage for analytics, and hence they are inefficient for streaming analytics. Some data warehouses support “micro-batching” to collect data often and in small increments. This stream-to-batch conversion increases the time between the arrival of data to its use for analytics making data warehouses inadequate for many forms of streaming analytics.
Data lakes support native streaming where streams of data are processed and made available for analytics as it arrives. The data pipelines transform the data as it is received from the data stream and trigger computations required for analytics. The native streaming feature of the data lake makes them highly suitable for streaming analytics.
Continuous Data Engineering:
Data warehouses support sequential ETL operations, where data flows in a waterfall model from the raw data format to a fully transformed set, optimized for fast performance,
In contrast, Data lakes are exceptionally strong for use cases that require continuous data engineering. In data lakes, the waterfall approach of ETL is replaced by iterative and continuous data engineering. The raw data that lands in a data lake can be accessed and transformed iteratively via SQL and programmatic interfaces to meet the changing needs of the use case. This support for continuous data engineering is critical for interactive analytics and machine learning.
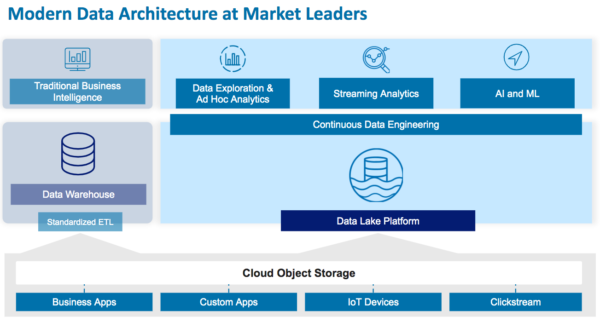
Diversity of Data Types
With the proliferation of new types of data including IoT, social, geospatial, multi-media, click-stream, and log data, the nature of data that we collect and use has greatly diversified. This new type of data that we generate and collect today includes semi-structured data with a partial or frequently changing structure and unstructured data with no defined structure.
The data warehouse, invented in late 1980, was designed for highly structured data generated by business apps. In fact, the data warehouse architecture relies on the structure of the data to support highly performant SQL (Structured Query Language) operations. Some newer data warehouses support semi-structured data such as JSON, Parquet, and XML files, they provide limited support and diminished performance for such data sets compared to structured data sets. Data warehouses do not support the storage of unstructured data.
Data lakes support native storage of all three data types – structured, semi-structured, and unstructured. Structured data is ideally suited for traditional Business Intelligence, while semi-structured and unstructured data is useful for deeper analytics and machine learning.
Open vs Proprietary Data Formats
The data warehouse stores the data in a proprietary format. Once the data is stored in the data warehouse, access to this data is limited to SQL and any custom drivers provided by the data warehouse. Some data warehouses can store XML, ORC, and Parquet files however these files are vendor locked and available through access mechanisms supported by the data warehouse.
In contrast, the data lake stores data in an open and standard format preventing any proprietary lock-in of data. An open data lake ingests data from sources such as applications, databases, data warehouses, and real-time streams. It stores this data in an open format, such as ORC and Parquet, that is platform-independent, machine-readable, optimized for fast access and analytics and made available to consumers without restrictions that would impede the re-use of the data.
Open data lake supports data access through the standards-based implementation of SQL with no proprietary extensions. It enables external tools to access that data through standards such as ODBC and JDBC. Also, the open data lake supports programmatic access to data via standard programming languages such as R, Python, and Scala and standard libraries for numerical computation and machine learning such as TensorFlow, Apache Spark, and MLib, MXNet, Tensorflow, Keras, and SciKit Learn.
An Open Data Lake stores the data in an open format preventing vendor lock-in. Data can be safely ported to any platform on any cloud that can read the open data format.
Conclusion
The increase in volume, velocity, and variety of data, combined with new types of analytics and machine learning is creating the need for an open data lake architecture. Across our customers including market leaders like Expedia, Disney, Adobe, and more, we find that an open data lake is becoming a common feature alongside the Data Warehouse. While the data warehouse has been designed and optimized for SQL analytics, the need for an open, simple and secure data lake platform, that can support new types of analytics and machine learning is driving the open data lake adoption. Unlike the data warehouse’s world of proprietary formats, proprietary SQL extensions, proprietary metadata repository, and lack of programmatic access to data, the open data lake prevents vendor lock-in while supporting a diverse range of analytics. The open data lake provides a robust and future-proof data management paradigm to support a wide range of data processing needs including data exploration, interactive analytics, and machine learning.



