Container Packing for Resource Scheduling in the Cloud
In this post we describe a new algorithm for allocating resources among long-running distributed applications. When applied to big data workloads running on an elastic compute cluster, this algorithm has been seen to result in hardware savings of more than 40 percent.
YARN Resource Allocation
Many big data frameworks such as MapReduce, Tez, and Spark use YARN for resource allocation and management. By default, YARN tries to allocate resources according to capacity on each node and locality constraints attached in the resource request. If multiple nodes satisfy these constraints, YARN will allocate resources uniformly among qualified nodes.
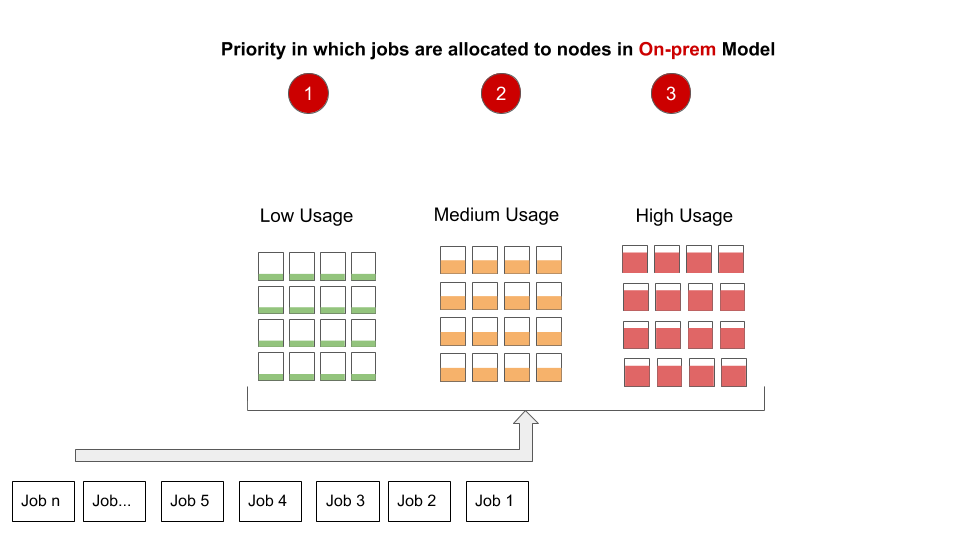
This design works well in on-premise, fixed-size cluster deployments, ensuring that a single node failure doesn’t have much impact on running jobs. It also helps to utilize as many nodes as possible and avoids over-utilization of a single node. While YARN tries its best to keep track of resource utilization, it is inherently difficult to account for the usage of resources like network links accurately, and spreading the load around is an easy way to avoid resource hot spots.
Hadoop In The Cloud
In a cloud deployment, it is common to have an elastic cluster such as Qubole’s autoscaling Hadoop/Spark clusters [1]. Users configure a minimum and maximum cluster size, and the cluster automatically scales up and down according to the workload and other factors.
Critical to downscaling is finding nodes that can be removed from the cluster. Unlike HTTP requests to a web application, big data applications are frequently long running. Moreover, tasks run by such applications are not stateless (unlike HTTP requests). They leave behind state on local disks that may be needed for the lifetime of the application.
In such a scenario, a uniform resource allocation strategy becomes a huge drawback. Incoming tasks are evenly distributed to all available and qualified nodes. Most nodes are either running active tasks or have a state from previous ones that blocks Qubole’s cluster management from de-provisioning the nodes and downscaling. As a result, once the cluster scales up, it’s difficult to downscale — even if the current workload can be run on a much smaller number of nodes.
Another way to characterize this behavior is through the utilization percentage of the entire cluster. This can often hover at 20 to 30 percent and is clearly not cost-effective.
Container Packing
Container Packing is a new resource allocation strategy that makes more nodes available for downscaling in an elastic computing environment, while at the same time preventing hot spots in the cluster and trying to honor data locality preferences. In this section we describe how the new allocation strategy works.
Node Categorization
We first divide all of the active cluster nodes into three categories:
- High Usage Nodes: These are the nodes with resource usage (memory) greater than HIGH_NODE_THRESHOLD (configurable, defaults to 60 percent)
- Medium Usage Nodes: These are the nodes with resource usage less than HIGH_NODE_THRESHOLD but greater than zero percent (meaning at least some containers are running on the nodes)
- Low Usage Nodes: Remaining nodes, which don’t have any running containers (usage = zero percent)
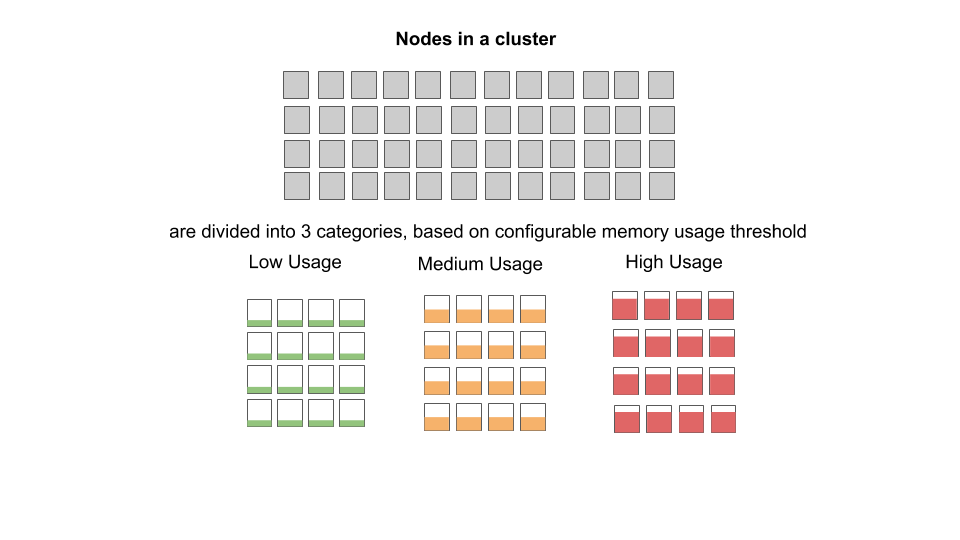
The system’s goal is to give Medium Usage Nodes first priority when distributing containers. We cache each node’s state and update it during every heartbeat check (in one second intervals).
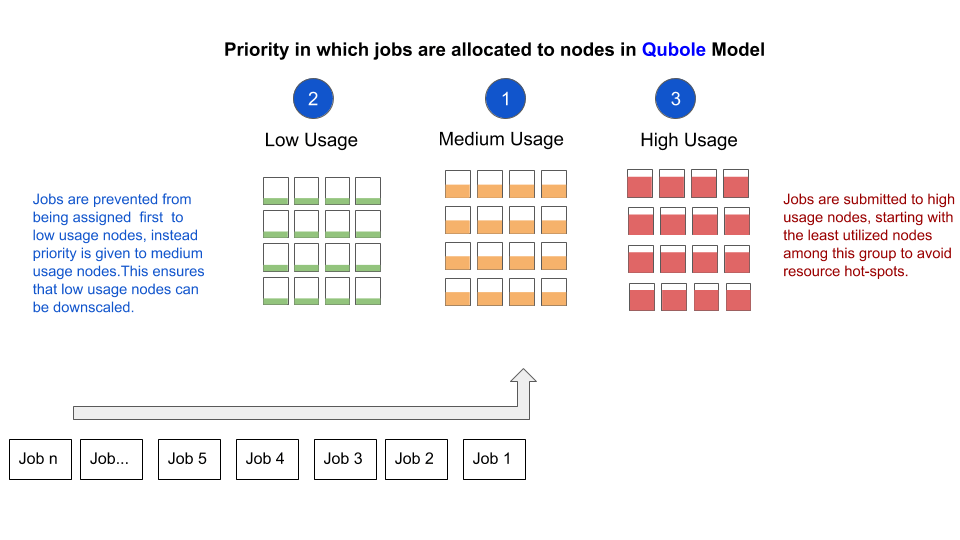
Scheduling Protocol
When requests for task scheduling arrive on YARN:
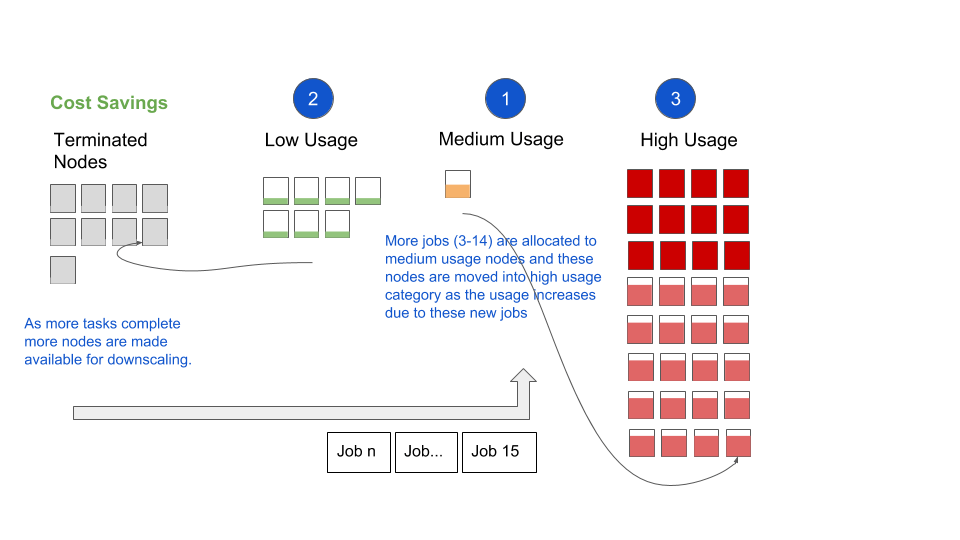
- We first consider the Medium Usage Nodes to schedule the task. This takes into account the resource requirements and locality constraints of the task. Higher utilization nodes from among this set are given preference, so the remaining nodes in this category may become Low Usage Nodes over time and trigger downscaling.

- If container requests cannot be satisfied in Step 1, we try to schedule them on Low Usage Nodes. In this step we pick nodes randomly.
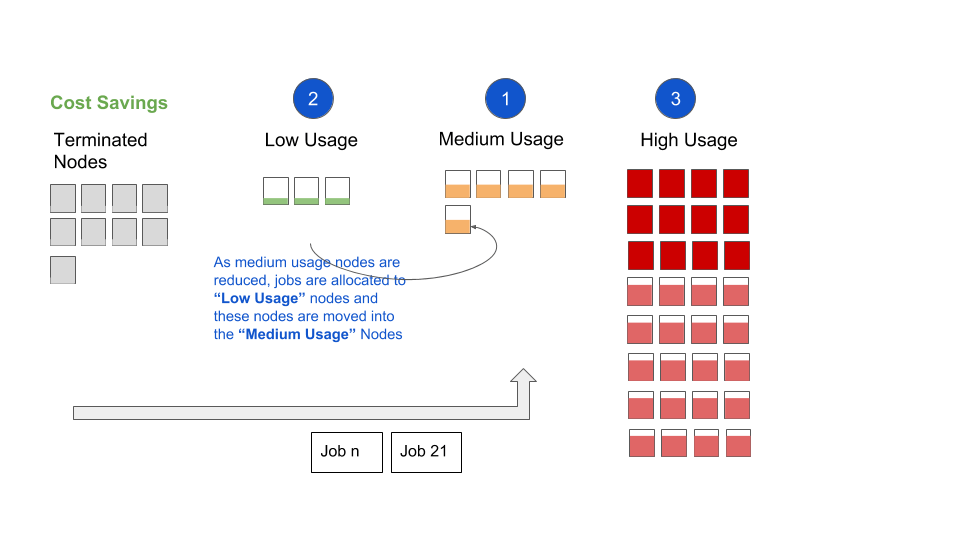
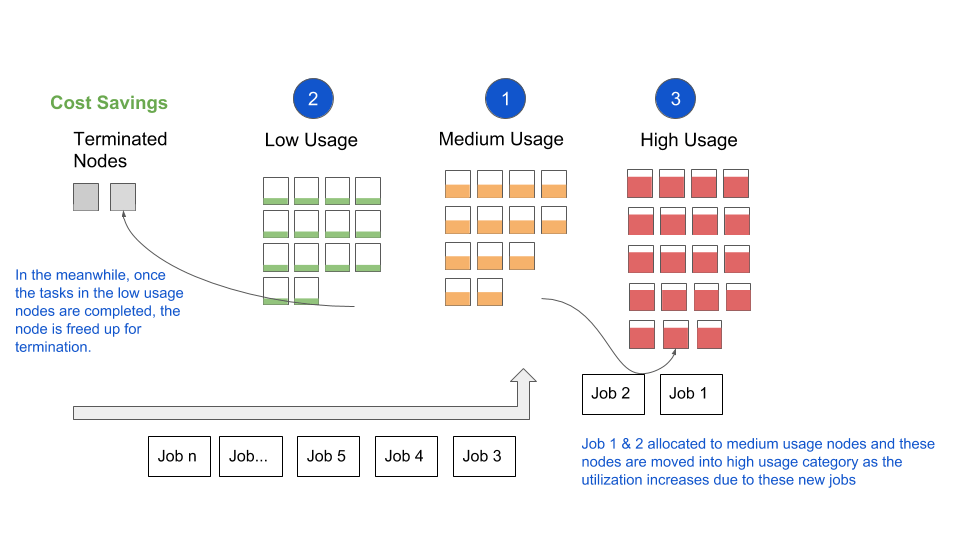
- Finally, any requests that are not satisfied by Medium or Low Usage Nodes are scheduled against High Usage Nodes. First priority among High Usage Nodes is given to nodes with lower usage to avoid hot spots in the system.
- As the tasks are completed and memory utilization decreases, High Usage Nodes are once again moved back into either the medium usage or low usage category.
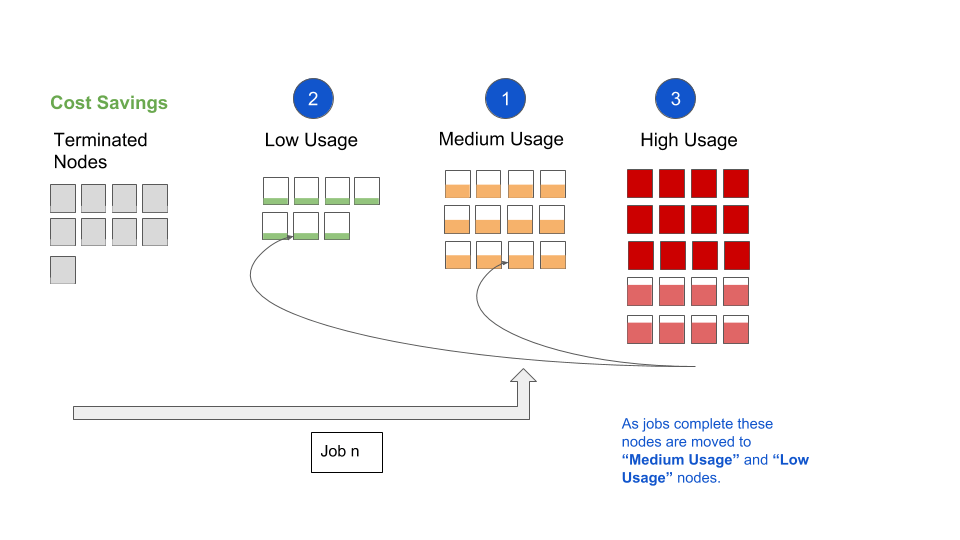
Note that container packing has no impact on upscaling. Upscaling in Qubole’s YARN clusters is triggered by container requests waiting for more than three minutes. This ensures that we allow requests enough time to get scheduled on any available nodes (Medium, Low, or High) before triggering upscaling. Note also that by default container packing is automatically disabled if the cluster is at its minimum size.
Container Packing Examples
Let’s consider a 10-node cluster in which each node has the capacity to schedule 10 containers. So essentially we have a capacity of 100 containers, and we have 20 container requests.
Without container packing, each node would be running two containers, and we wouldn’t find any candidates for downscaling. In this case the cluster utilization is only 20 percent.
With container packing (assuming 80 percent as HIGH_NODE_THRESHOLD), two nodes would be running eight containers each and one node would be running four containers to satisfy a 20-container request. We would have eight nodes that weren’t running any containers. We can downscale these eight nodes and cluster utilization will be 67 percent.
Qubole
Qubole uses FairScheduler in YARN to schedule containers, and container packing is implemented via the FairScheduler. The following configuration options are relevant to using container packing in Qubole:
| Option Name | Default Value | Description |
| yarn.scheduler.fair.continuous-scheduling-enabled | true | If true, YARN schedules continuously (instead of only on node heartbeats). All nodes are iterated periodically (by default every 5 ms) and multiple containers can be assigned to a single node in one iteration. |
| yarn.scheduler.fair.continuous-scheduling-packed | true | If true and if continuous scheduling is enabled (see above), container packing feature is enabled. |
| yarn.scheduler.fair.continuous-scheduling-packed.high.memory.threshold | 60 (percent) | Threshold memory utilization above which nodes are considered to be high usage.
|
| yarn.scheduler.fair.continuous-scheduling-packed.min.nodes | 5 (nodes) | Container packing is turned off if the current cluster size is below this value and the minimum cluster size. The user can raise this value to prevent packing from kicking in at small cluster sizes. |
| yarn.scheduler.fair.locality-delay-node-ms | 6 (ms) | This has to be set to a value larger than the continuous scheduling frequency (controlled by yarn.scheduler.fair.continuous-scheduling-sleep-ms, default 5ms). This makes sure that we first try to schedule any container requests containing locality preferences on preferred nodes in the Medium Usage Set before trying (in a separate continuous scheduling iteration) on non-preferred nodes (in the other sets). |
| yarn.scheduler.fair.continuous-scheduling-sleep-ms | 5 (ms) | This is the frequency of scheduling the container. |
Case Studies
Customers who adopted this feature all report cost savings.
Hike.in a mobile app that enables its users to communicate with each other, uses Qubole to do data processing. They have been using this feature since December 2016.
We compared the node usage in one of their clusters with an r3.4xlarge instance type between before and after container packing is enabled:
| Before (Nov 14-28, 2016) | After (Mar 1-15, 2017) | |
| Total nodes provisioned | 125 | 937 |
| Total node hours consumed | 6925 | 5232 |
This result shows that there was substantial increase in downscaling and upscaling frequency (more often to trigger removing or adding nodes in the cluster, thus the increased number of total nodes provisioned) after container packing was enabled. Total node hours are reduced.
Traveloka, an online travel agency aggregator company, is running Hadoop2 ETL clusters in Quoble using r3.2xlarge instance type with minimum/maximum worker nodes set to 25/200. After turning on container packing, they see the cluster utilization is now around 75 to 80 percent, much more than before.
“Qubole’s container packing has helped us reduce our EC2 costs by enabling a lazy upscale and an aggressive downscale without compromising on performance.” — Endy Lambey, Data Governance, Operations, and Architecture at Traveloka
Conclusion
Container packing is a novel non-uniform resource allocation strategy for YARN that helps to reduce the cost of running elastic Hadoop/Spark clusters by allowing more aggressive downscaling and increasing hardware utilization. We are currently in the process of rolling this feature out to all customers gradually, which is part of our upcoming Cloud Agents (Workload-Aware Autoscaling). In the meantime, customers can enable it manually by setting the first two options to true in their Hadoop overrides in the Cluster Configuration section of the Qubole UI.
For more information and updates, see Qubole’s online documentation.
References
[1] Industry First Auto-Scaling Hadoop Cluster: https://www.qubole.com/blog/product/industrys-first-auto-scaling-hadoop-clusters/



