
Hive on Hadoop makes data processing so straightforward and scalable that we can easily forget to optimize our Hive queries. Well-designed tables and queries can greatly improve your query speed and reduce processing costs. This article includes five tips, which are valuable for ad-hoc queries, to save time, as much as for regular ETL (Extract, Transform, Load) workloads, to save money. The three areas in which we can optimize our Hive utilization are:
- Data Layout (Partitions and Buckets)
- Data Sampling (Bucket and Block sampling)
- Data Processing (Bucket Map Join and Parallel execution)
We will discuss these areas in detail below. Also watch our webinar on the topic given by Ashish Thusoo, co-founder of Apache Hive, and Sadiq Sid Shaik, Director of Product at Qubole. Based on the data set we use, Qubole can improve your data set, as illustrated in the example below.
The data consists of three tables. The table Airline Bookings All contains 276 million records of complete air travel trips from an origin to a destination with an itinerary identifier as a key. The second table Airline Bookings Origin Only contains the data for the first leg of an itinerary only and also has the itinerary’s identifier as a key. The last table is the ‘Census’ containing population information for each US state.
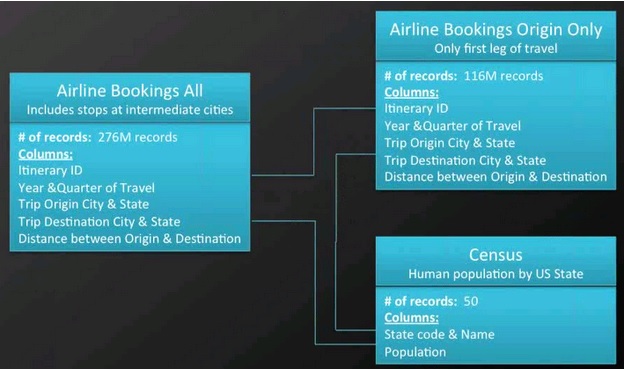
This example data set demonstrates Hive query language optimization.
Tip 1: Partitioning Hive Tables Hive is a powerful tool to perform queries on large data sets and it is particularly good at queries that require full table scans. Yet many queries run on Hive have filtering where clauses limit the data to be retrieved and processed, e.g. SELECT * WHERE state=’CA’. Hive users tend to have or develop domain knowledge and understand the data they work with and the queries commonly executed or scheduled. With this knowledge, we can identify common data structures that surface in queries. This enables us to identify columns with (relatively) low cardinalities like geographies or dates and high relevance to key queries.
For example, common approaches to slice the airline data may be by origin state for reporting purposes. We can utilize this knowledge to organize our data by this information and tell Hive about it. Hive can utilize this knowledge to exclude data from queries before even reading it. Hive tables are linked to directories on HDFS or S3 with files in them interpreted by the metadata stored with Hive. Without partitioning, Hive reads all the data in the directory and applies the query filters to it. This is slow and expensive since all data has to be read. In our example, common reports and queries might be generated on an origin-state basis.
This enables us to define at the creation time of the table the state column to be a partition. Consequently, when we write data to the table the data will be written in sub-directories named by state (abbreviations). Subsequently, query filtering by origin state, e.g. SELECT * FROM Airline_Bookings_All WHERE origin_state = ‘CA’, allows Hive to skip all but the relevant sub-directories and data files. This can lead to a tremendous reduction in data required to read and filter in the initial map stage. This reduces the number of mappers, IO operations, and time to answer the query.
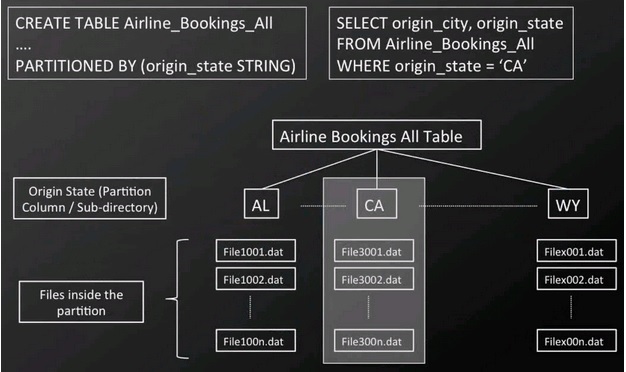
Example Hive table partitioning It is important to consider the cardinality of a potential partition column and avoid fragmenting the data too much. Itinerary ID would be a very poor choice for partitioning. Queries for single itineraries by ID would be very fast but any other query would require parsing a huge amount of directories and files incurring serious overheads.
Additionally, HDFS uses a very large block size of usually 64 MB or more which means that each file, even with only a few bytes of data, will have to allocate that block size on HDFS. This can potentially fill the file system up with a large number of files carrying barely any actual data.
Tip 2: Bucketing Hive Tables Itinerary ID is unsuitable for partitioning as we learned but it is used frequently for join operations. We can optimize joins by bucketing ‘similar’ IDs so Hive can minimize the processing steps, and reduce the data needed to parse and compare for join operations. Itinerary IDs, of course, have no real similarity and we only need to achieve that the same itinerary IDs from two tables end up in the same processing bucket.
A simple trick to do this is to hash the data and store it by hash results, which is what bucketing does.
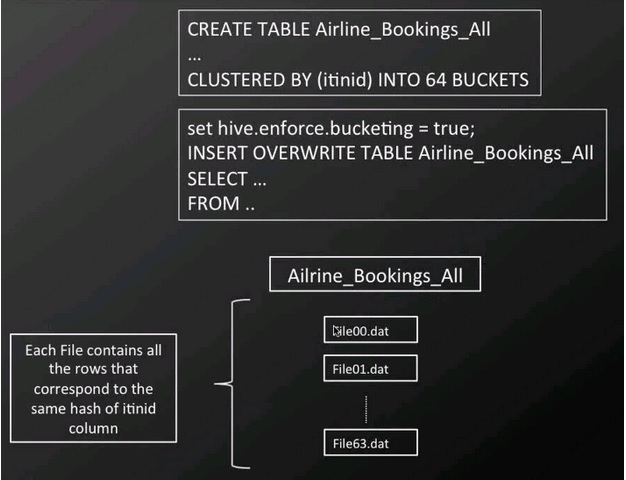
Example Hive query table bucketing Bucketing requires us to tell Hive at table creation time by which column to cluster and into how many buckets. We also have to ensure the bucketing flag is set (SET hive.enforce.bucketing=true;) every time before we write data to the bucketed table.
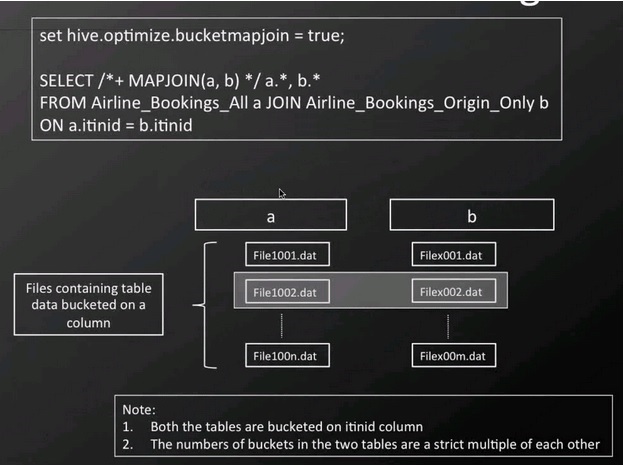
Importantly, the corresponding tables we want to join have to be set up in the same manner with the joining columns bucketed and the bucket sizes being multiples of each other to work. The second part is the optimized query for which we have to set a flag to hint to Hive that we want to take advantage of the bucketing in the join (SET hive.optimize.bucketmapjoin=true;).
The SELECT statement then can include a MAPJOIN statement to ensure that the join operation is executed at the map stage by combining only a few relevant files in each mapper task in a distributed fashion from the two tables instead of parsing the full tables. Example Hive MAPJOIN with bucketing.
Tip 3: Bucket Sampling Once our tables are set up with these buckets we can address another important use case. We often want to query large table joins for a sample. We may want to try out complex queries or explore the data, and we want to do this iteratively, swiftly, and not process the whole data set.
This is particularly difficult because of the joining of the tables since only very little data may overlap on independent samples from two tables. Ideally, we would want to sample the relevant data on both tables and join it, i.e. ensure that we sample the same itinerary IDs from both tables and not sets with no or little overlap.
The bucketing on the join column enables us to join specific buckets from two tables with data overlapping on the join column. Effectively, we execute exactly one part of the complete join operation and only incur the cost of it. The hashing function on the ID has the additional benefit of a (somewhat) random nature providing a representative sample.
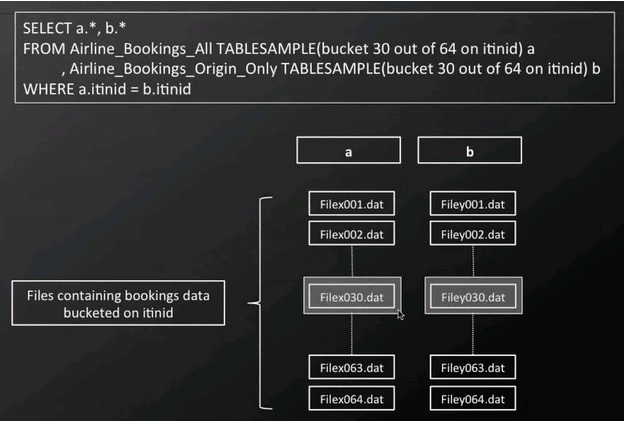
Example Hive TABLESAMPLE on bucketed tables
Tip 4: Block Sampling Similarly, to the previous tip, we often want to sample data from only one table to explore queries and data. In these cases, we may not want to go through bucketing the table, or we have the need to sample the data more randomly (independent from the hashing of a bucketing column) or at decreasing granularity.
Block sampling provides a powerful syntax to define various ways of sampling the data in a table with the TABLESAMPLE statement. We can use it to sample a certain percentage, a number of bytes, or rows of data. We can use sampling to approximate information like the average distance between the origin and destination of our itineraries.
A query using 1% of the data using TABLESAMPLE(1 PERCENT) on a large table will give us a near-perfect answer and use up to only a hundredth of the resource and return the result one to two magnitudes faster. In exploratory work or for metrics this approach can be an extremely efficient and effective alternative to processing all of the data. The beauty of this solution is that we can scale the sample size with our data size. If we were to explore at Tera- or Petabytes of data we could sample a fraction of percent and get the same actionable information in minutes or less which would otherwise take hours to receive.
Tip 5: Parallel Execution Hadoop can execute map-reduce jobs in parallel and several queries executed on Hive make automatically use of this parallelism. However, single, complex Hive queries commonly are translated to a number of map-reduce jobs that are executed by default sequentially. Often though some of a query’s map-reduce stages are not interdependent and could be executed in parallel.
They then can take advantage of spare capacity on a cluster and improve cluster utilization while at the same time reducing the overall query execution time. The configuration in Hive to change this behavior is merely switching a single flag SET hive.exce.parallel=true;.
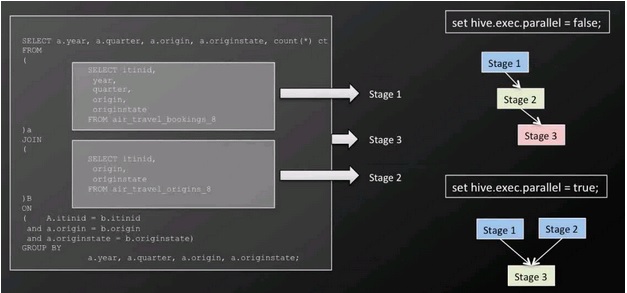
Example of Hive parallel stage execution of a query In our example in the image above we can see that the two sub-queries are independent and when we enable parallel execution are processed at the same time.
In our example, this reduced the execution time by 50%! Conclusion The five presented tips in this article can easily be applied by anyone using Hive to improve processing and query speed and reduce resource consumption. You can, of course, use them with the Qubole platform and are welcome to try it out.



