BIG DATA IN DATA LAKES
Big data has become an essential requirement for enterprises looking to harness their business potential. Today both large and small businesses enjoy greater profitability and competitive edge through the capture management, analysis of vast volumes of unstructured data. However, all organizations have realized they require a modern data architecture for going to the next level. This need has led to the emergence of data lakes.
According to Dr. Kirk Borne, Principal Data Scientist & Data Science Fellow, Booz Allen Hamilton:
“The biggest challenge of Big Data is not volume, but data complexity or data variety. Volume is not the problem because the storage is manageable. Big Data is bringing together all the diverse and distributed data sources that organizations have across many different sources of data. Data silos inhibit data teams from integrating multiple data sets that (when combined) could yield deep, actionable insights to create business value. That’s what a data lake can do.”
Watch his keynote session from the Data Lake Summit here
Data Lakes
A data lake includes all data sources, unstructured, semi-structured, from a wide variety of data sources, which makes it much more flexible in its potential use cases. Data lakes are usually built on low-cost commodity hardware, making it economically viable to store terabytes and even petabytes of data.
Moreover, data lake provides end-to-end services that reduce the time, effort, and cost required to run Data pipelines, Streaming Analytics, and Machine Learning workloads on any cloud.

Ad hoc Analytics
For ad hoc and streaming analytics, the Qubole cloud data lake platform lets you author, save, collaborate, and share reports and queries. You can develop and deliver ad-hoc SQL analytics through optimized ANSI/ISO-SQL (Presto, Hive, SparkSQL) and third-party tools such as Tableau, Looker, and Git native integrations. The data lake platform helps you build streaming data pipelines, combining with multiple streaming and batch datasets to gain real-time insights.

Machine Learning
For machine learning, the data lake provides capabilities to build, visualize, and collaborate on machine learning models. Qubole’s machine learning specific capabilities such as offline editing, multi-language interpreters, and version control deliver faster results. You can leverage Jupyter or Qubole notebooks to monitor application status and job progress, and use the integrated package manager to update the libraries at scale.

Data Engineering
For data engineering, the data lake automates pipeline creation, scale, and monitoring. You can easily create, schedule, and manage workloads for continuous data engineering. Use the processing engine and language of choice like Apache Spark, Hive, Presto with SQL, Python, R, Scala.
Cloud Data Lake
While early data lakes were built on-premises, organizations are moving their data lakes to the clouds as infrastructure-as-a-service offerings grow increasingly popular. In an on-premises data lake, organizations commonly need to manage both the hardware infrastructure and software side. If their data volumes grow beyond the capacity of the hardware they’ve to purchase, then companies have no choice but to buy more computing power themselves. In cloud data lakes, organizations are able to pay for only the data storage and compute they need. This means they are able to scale up or down as their data requires. This scalability has been a huge success in Big Data’s adoption, driving the increased popularity of data lakes.
Data Lake Scalability
Data lakes can ingest volume, variety, and velocity of data and stage and cataloged them centrally. Data is then made available for various analytics applications, at any scale, in a cost-efficient manner. The cloud data lake a centralized repository that stores large amounts of structured, semi-structured, or unstructured at any scale. The primary purpose of a data lake is to make organizational data from different sources accessible to various end-users like business analysts, data engineers, data scientists, product managers, executives, etc., to enable these personas to leverage insights in a cost-effective manner for improved business performance. In order to fully realize the cost advantages of a cloud data lake, the big data workflow needs to be architected to take advantage of the separation of compute and storage. However, the challenge is to have a system that can help different big data workloads autoscale according to the nature of their workloads.
Data Lakes for Big Data
The cloud’s architecture leads to six main advantages for big data workloads:
Big Data Infrastructure
A big data infrastructure on the cloud adapts seamlessly to changing workloads and business requirements. The cloud elasticity allows data teams to focus more on managing data and spend less time managing the data platform. Qubole Data Service provides additional elasticity by offering complete cluster lifecycle management to scale clusters up and down to match query workloads automatically.
The cloud also allows you to select the instance type best suited for a given workload and gives you access to an assortment of different engines – Apache Hive, Spark, Presto, and more – depending on the use case.

Cloud Architecture
The cloud architecture also creates great agility. While on-premises solutions frequently require six to nine months to implement, Qubole users can begin querying their data in an average of 2.8 days. With such a low startup time, business teams are able to allocate their time and resources to building applications, running queries, and extracting actual business value. The cloud also allows teams to iteratively determine the best performance and cost and adjust accordingly. With the help of cloud, teams can adjust and optimize the configuration, such as the machine type or cluster size. On-premises solutions do not give this option, which means they’re stuck with what they bought and deployed.

Cloud Computing Costs
Big data workloads are compute-intensive and can handle bursty workloads. The cloud architecture can scale as needed, allowing businesses to only pay for compute space when required. Whereas on-premises solutions, organizations have to buy infrastructure (build capacity) for peak usage.
Organizations using the AWS platform can save a lot of money by incorporating Qubole’s automated spot instances. Qubole customers run nearly half their workloads using spot instances, which is 80 percent lower in cost.
Cloud Security
It’s a commonly held myth that the cloud is less secure as compared to on-premises solutions. However, the cloud is often the more secure option. Cloud provides typically dedicated much more time and resources to security and is able to adopt best practices faster.
Geographic Reach
The cloud allows organizations a choice in where they can store their data. This decision can be based on factors such as overall convenience, where the data originates from, and any legal issues with how the data is being used.
Disaster Recovery
The cloud is more fault-tolerant and resilient than on-premises solutions. It allows enterprises to recover more quickly in the event of a disaster. If there’s a node failure or issue with a cluster, teams can seamlessly provision a new node or spin up a cluster in an alternate location. By automating this process, data teams spend less time on maintenance and can focus more on business needs.
Big Data Processing Tools
For those who would like to get better acquainted with Big Data—in particular the devices that can help organizations extract value and competitive advantage from massive sets of structured and unstructured information—here’s a guide to some prominent big data processing tools.

Hadoop
Hadoop has evolved into a foundational big data analytics tool. Using commodity hardware and open-source software, Hadoop’s Distributed File System (HDFS) facilitates the storage, management and rapid analysis of vast datasets across distributed clusters of servicers. Hadoop has many features that make it an attractive big data processing powerhouse for organizations—features such as flexibility to handle multiple data formats, scalability to accommodate very large workloads, and affordability that allows organizations with modest budgets to reap big data benefits.
NoSQL
Not Only SQL (NoSQL) is a database technology that runs on the Hadoop analytics platform. NoSQL database solutions allow businesses to be more flexible and agile at storing, retrieving, and analyzing massively large volumes of disparate and complex data, and doing so at lightning-fast speeds.


Hive
Hive was designed by two Facebook data scientists in 20028 to automatically translate SQL-like queries into MapReduce jobs on Hadoop—all through the use of a language called HiveQL. As a result, Hive transformed Hadoop by placing serious analytics power in the hands of key decision makers within organizations who didn’t have PHD’s in data science. In cases where summarizing, querying, and analyzing large sets of structured data is not time sensitive, Hive is more than up to the task.
Spark
Spark supports operations such as SQL queries, streaming data, and complex analytics, i.e.,machine learning and graph algorithms.Spark also enables these multiple capabilities to be combined seamlessly into a single workflow. And since Spark is one hundred percent compatible with Hadoop’s Distributed File System (HDFS), HBase, and any Hadoop storage system, virtually all of an organization’s existing data is instantly usable in Spark.


Presto
Presto is a massively scalable, open-source, distributed query machine that enables fast interactive analysis of vastly large data sets. Running exclusively in memory, Presto can run simple queries on Hadoop in a few milliseconds, while more complex queries take only a few minutes. Shown to be more than seven times more efficient on the CPU than Hive, Presto can merge multi-source data into a single query, thus providing analytics across an entire organization. Running interactive analytic queries on data sources ranging from gigabytes to hundreds of petabytes is the main use case for Presto—a tool that has transformed the Hadoop ecosystem.
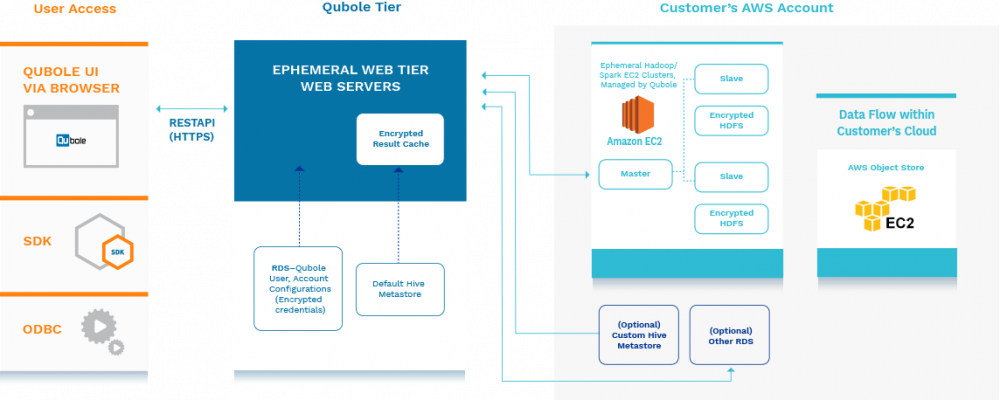
Qubole
Multiple storage options
- AWS S3 Object Store
- Google Cloud Storage
- Azure Data Lake and Blog
- Connect Data Warehouse and NoSQL database (on-premises or in cloud)
For more details, click on the respective pages for Qubole on Amazon Web Services, Google Cloud, or Microsoft Azure; or sign up for Qubole’s 30-day free trial.
Cluster Management
- Automated cluster management for ease of administration and enable self-service access to users through various interfaces.
- Managed autoscaling for Spark, Hadoop and Presto workloads.
Cloud Performance and Governance
- Performance and stability monitoring of pipelines and jobs
- Alerting on production jobs to ensure consistent uptime
- Insights on how your teams are working with your data and tables to figure out where to optimize processes
- Recommendations to improve performance of existing workloads and table formats for analytics


