This is a guest post authored by Mikhail Stolpner, Solutions Architect, Qubole
Planning XGBoost cluster
This planning guide covers a scenario when there is a need to run an XGBoost job that must complete in a certain timeframe. In this scenario, we can assume that the load requirement is known ahead of time.
Before we move to describe an approach how to configure such a cluster, we will overview Spark resource allocation.
Resource Allocation
This section explains the relationship between Cluster Node, Spark Executor, Task, XGBoost Worker, and Node.
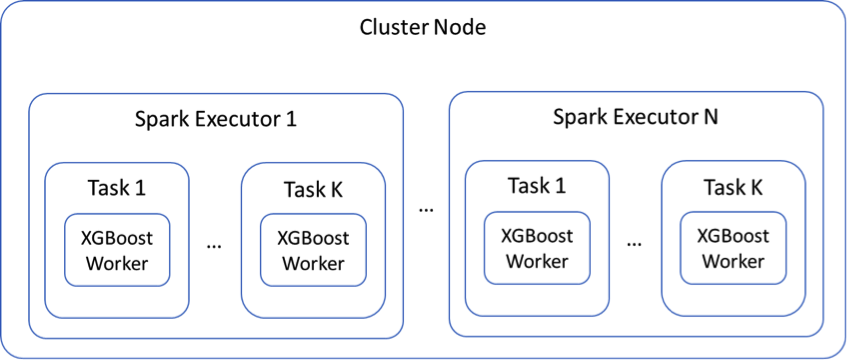
The diagram bellows depicts a composition hierarchy in a single node of a Spark cluster running XGBoost. A Cluster Node runs one or more Spark Executors. Each Spark executor runs in its own JVM. Each Spark Executor can run multiple Spark Tasks. XGBoost workers are executed as Spark Tasks. The total number of XGBoost Workers in a single Cluster Node is the number of Executors N times the number of Tasks per Executor K or N * K.
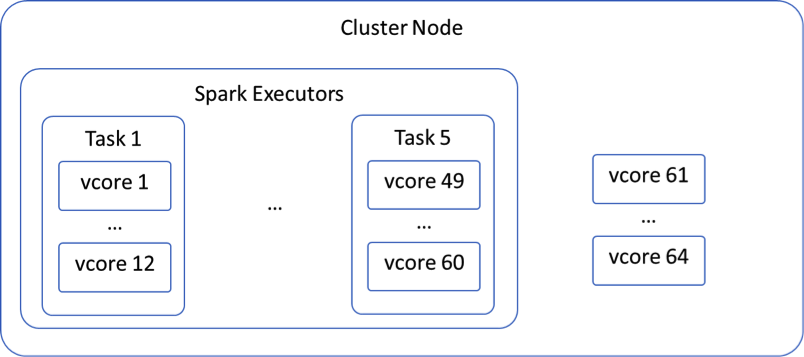
Yarn manages the resources of the Qubole Spark Cluster. When we start a new job, Yarn is trying to fit our requirements on Vcores and memory into available nodes. If a node has 64 Vcores and our tasks are configured to utilize 12 Vcores each, Yarn will only be able to fit 5 of these tasks into a single node, leaving 4 Vcores unused, as shown in the diagram below. The same logic applies to memory.
Yarn will try to start as many Executors as specified in spark.executor.instances (see table below in Spark Configuration section) and will try to scale out to spark.qubole.max.executors if needed.
It’s important to note, that Yarn will start a single ApplicationMaster on one of the Slave Nodes. The ApplicationMaster process will take one vcore leaving this Slave Node with one vcore less than all other Slave Nodes. It will reduce the number of Executors that Yarn will be able to allocate for this node.
Spark Driver will be running on the Master Node.
Tuning Parameters
With systems as complex as XGBoost running on Spark cluster, it’s very difficult to precisely predict the best environment configuration. It’s usually the best approach to try a few different configurations and pick the one that your specific code works the best on.
There are 3 areas of configuration variables that you can change to formulate your environment: Cluster Configuration, Spark Configuration, and XGBoost Configuration. We go into details on each of these areas below.
Cluster Configuration
Remember, each cluster will always have a single Master Node and a specified number of Slave Nodes. In the Qubole Cluster Configuration, you can choose node instance type for both Master Node and Slave Nodes. A node instance type will determine how much memory and how many Vcores a single node will have. You can also choose a minimum and a maximum number of nodes for Slave Nodes. However, for this scenario, we recommend using the same number for both min and max as the load is known ahead of time, and auto-scaling is not required. A combination of these factors will determine how many Vcores and how much memory will be available on your Spark cluster.
It’s also important to note that you can decide on your Cluster Composition by choosing between “On-Demand”, “Spot”, and “Spot Block”. Choosing “Spot Block” over “On-Demand” will not impact performance, but it may significantly reduce your cost. While choosing “Spot” may help to further reduce the cost, we do not recommend it in this scenario as “Spot” nodes may be taken away in the middle of the process. It will increase the run time of the process overall.
Spark Configuration
Among many Spark parameters, we are mostly interested in the following:
| PARAMETER | DESCRIPTION |
| spark.task.cpus | Defines a number of Vcores allocated to each Spark Task. It can be set in an interpreter. |
| spark.executor.cores | Defines the number of Vcores allocated for each Spark Executor. It can be set in an interpreter. |
| spark.executor.instances | Defines a number of Executor instances Spark will start. It can be set in an interpreter. |
| spark.qubole.max.executors | Defines a maximum number of Executor instances Spark will scale to. It can be set in an interpreter. |
| spark.executor.memory | Defines the amount of memory available for each Spark Executor. It can be set in an interpreter. |
XGBoost Configuration
There are only two parameters we will configure in XGBoost.
| PARAMETER | DESCRIPTION |
| nThread | Defines a number of cores utilized by each XGBoost Worker. Cannot be more than a spark.executor.cores. Remember, the XGBoost worker runs as a Spark Task. |
| numWorkers | Defines the total number of XGBoost Workers. |
General Rules
Every XGBoost job is unique and may perform well on differently configured clusters. Below are some guidelines that will help you to configure your environment.
- Plan your cluster. Think of how many Executors you would like each node to run, how many Spark Tasks you would like each Executor to contain, and what it means in terms of Vcores and memory on each Node.
- Remember, that one vcore on one Slave Node will be taken by ApplicationMaster. If you have 10 nodes in your cluster with 64 Vcores each and you set the spark.executor.cores to 64, Yarn will not be able to place any Executor container on the node with ApplicationMaster, completely losing this node with the rest of the 63 Vcores for the actual job. However, if you configure a cluster with 1000 nodes, it may be worth wasting one node.
- Yarn will only be able to create as many Executors, Tasks, etc, as many resources it has. If you see that it did not create as many Executors as you expected, it’s an indication that there are not enough resources to support your desired configuration.
- (Vcores on a single node) / (spark.executor.cores) = number of executors that can be allocated on a single node.
- (spark.executor.cores) / (spark.task.cpus) = number of tasks (or XGBoost workers) that can be allocated on a single executor.
- A maximum number of XGBoost workers you can run on a cluster = number of nodes * a number of executors run on a single node * a number of tasks (or XGBoost workers) run on a single executor.
- Keep nThread the same as a spark.task.cpus. A good range for nThread is 4…8.
- Set spark.executor.cores to double of nThread.
- While it seems that the better allocation and utilization of the resources you achieve the better the performance will be, it’s not always the case. Different codes will benefit from different configurations. The configuration that shows less utilization than others can actually run your code faster. To summarize, it’s beneficial to start from a configuration that allocates as many resources as possible. However, do not assume it’s the best you can get, keep experimenting until you achieve your goal.
- There is a memory overhead at all levels – OS, Spark, and Yarn. You need to take this into consideration when allocating memory for Executors with spark.executor.memory. If you simply divide all memory available into a number of Executors you want to run on a single node, Yarn will not be able to start so many Executors due to overhead.
Setting Up XGBoost Cluster
Build XGBoost JARs:
You can build XGBoost JAR files with the following script:
wget https://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo sed -i s/\$releasever/6/g /etc/yum.repos.d/epel-apache-maven.repo yum install -y apache-maven git clone --recursive https://github.com/dmlc/xgboost cd xgboost make -j4 export JAVA_HOME=/usr/lib/jvm/java-openjdk/ cd jvm-packages mvn package
At this point, you have your XGBoost JARs ready to deploy to the Spark cluster.
Operationalizing XGboost with Bbootstrap
Place JARs (xgboost4j-0.7.jar, xgboost4j-spark-0.7.jar) on the S3 bucket
Please refer to this document for more details.
Create a bootstrap script to copy JARs to the Spark library:
hadoop dfs -get s3://bucket/xgboost4j-0.7.jar /usr/lib/spark/lib/ hadoop dfs -get s3://bucket/xgboost4j-spark-0.7.jar /usr/lib/spark/lib/
Note, you can also use s3cmd to copy files from S3.
Executing Notebooks
You will need to set all parameters mentioned in the Spark Configuration section in an Interpreter bound to your notebook: spark.executor.cores, spark.executor.instances, spark.qubole.max.executors, spark.executor.memory.
You will also need to configure XGBoost in your code. Below is a quick example of how that can be done:
val params = List( "nthread" -> 4).toMap val xgboostModel = XGBoost.train(rdd, param, numIterations, numWorkers, useExternalMemory=false)
Tools on the Qubole Platform
Qubole offers an extensive set of tools that can help you monitor and tune your Spark jobs. We will review them in this section.
Resource Manager
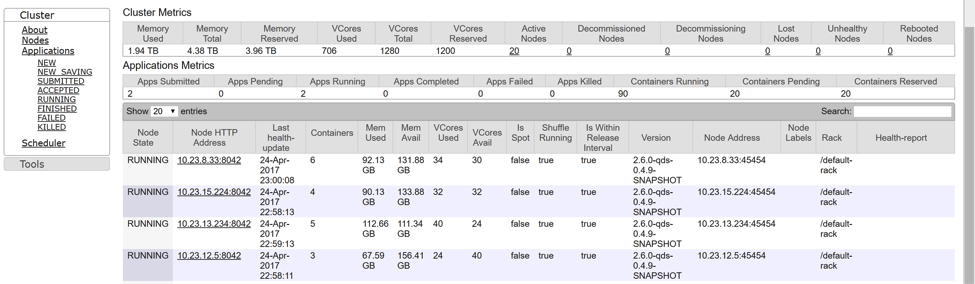
Resource Manager is a Yarn UI and it shows resource allocation. Note, that resource allocation does not reflect actual load. However, you cannot load your resources at a high level if you do not allocate them right.
The nodes page on the Resource Manager is a great tool to find out how resources have been allocated on your nodes. Remember, you need to start a Spark job before you can see any report on this tool.
To navigate to Resource Manager, open the Clusters page, hover over Resources to the right from your cluster, and click Resource Manager. Then clink on the Nodes link on the left.
Ganglia
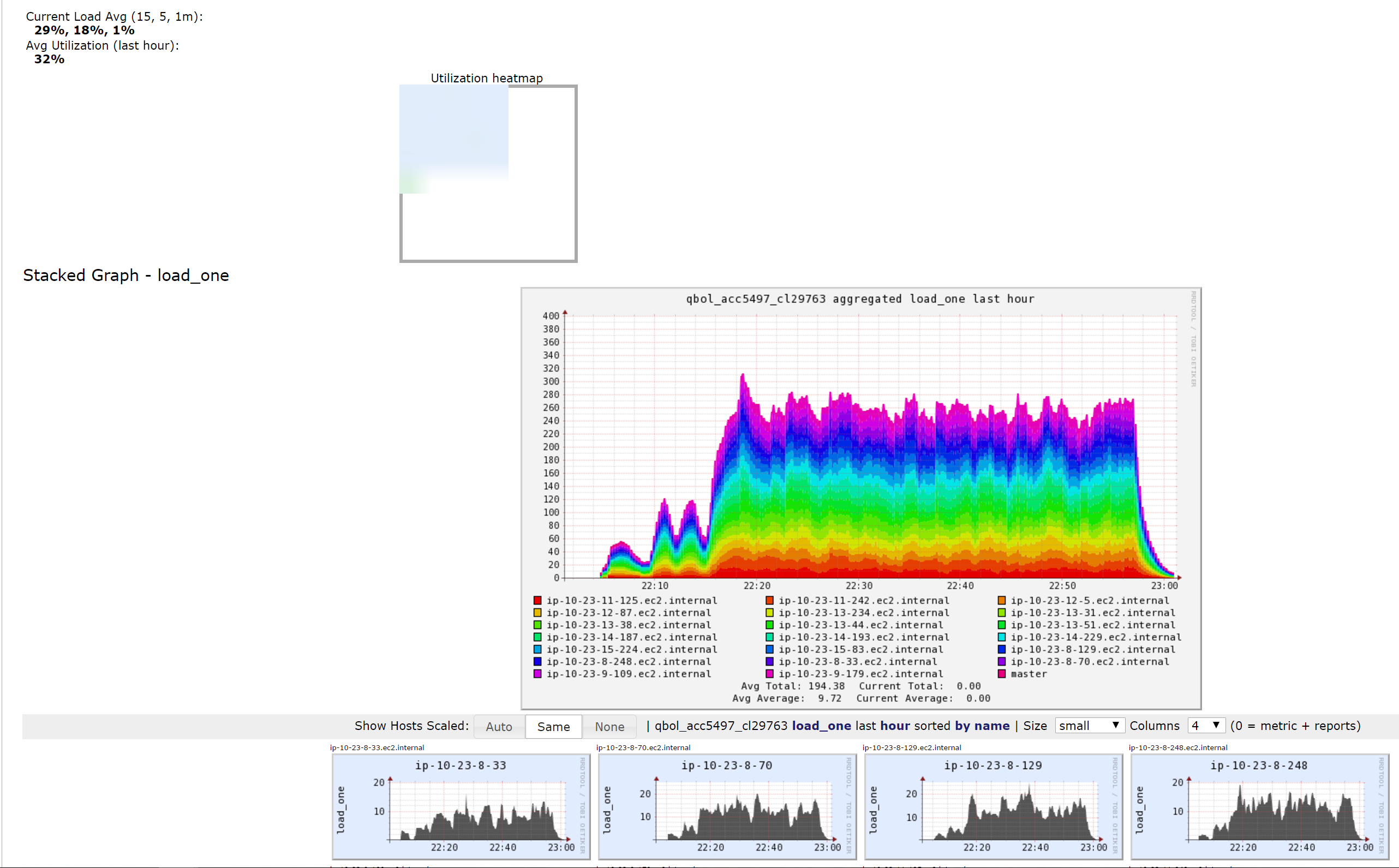
Ganglia is a monitoring tool and it shows actual load as opposed to resource allocation. You can start from Utilization Heatmap and drill down to many metrics available.
To navigate to Ganglia, open the Clusters page, hover over Resources to the right from your cluster, and click Ganglia.
Spark Application Master
ApplicationMaster is available through a link on the Resource Manager. Once you are on that page, click on the link that is to the right of your application. It will bring Spark Application Master UI.
Click on Stages. It will show you completed and active stages. Very helpful combined with Ganglia, as it shows which step of your process utilizes resources at what level. It is very interesting to see that different overall configurations can improve some parts of your process but not others.
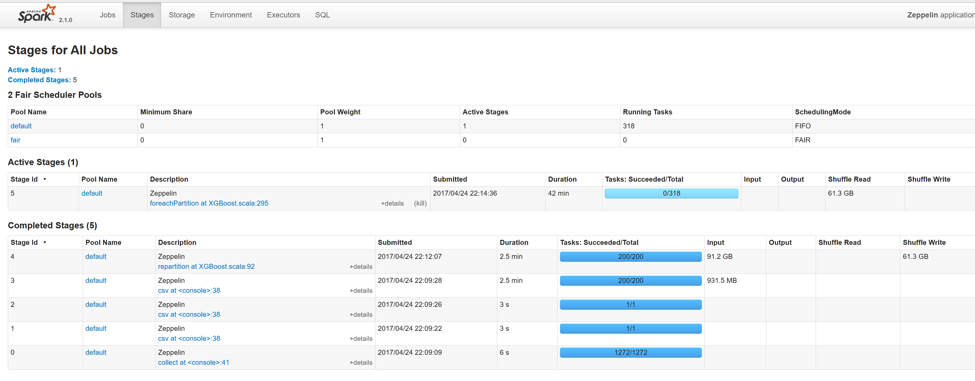
Study Case
We experimented with a Notebook outlined below and measured the performance of the last step – the training process.
sc.parallelize(Seq("")).map(x => {
import ml.dmlc.xgboost4j.scala.{Booster, DMatrix}
}).collect()
//Load data into RDD
val trainingRDD = spark.read.csv(“S3://bucket/”)
// Prepare parameters
val params = List("nthread" -> 4).toMap
val iterations = 200
val workers = 78
// Train the model
val xgboostModel = XGBoost.train(trainingRDD, params, iterations, workers, useExternalMemory=true)The notebook processed 1TB of data. As you can see from the table below, the most optimal runs (highlighted) have an average load of 75% and a relatively small number of workers spark.task.cpus = 4 is also equal to nThread, and a spark.executor.cores double of nThread. This data can give you a starting point for your experiments. This cluster was configured to utilize AWS instances with 64 Vcores.
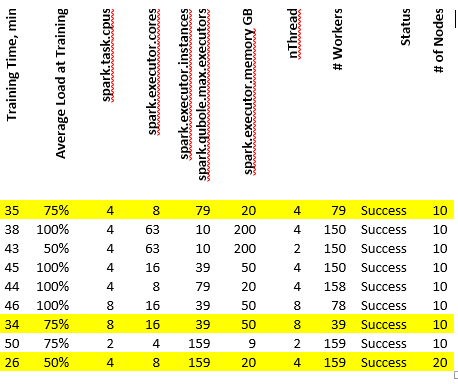
Let’s examine the first configuration in this table. With 8 Vcores per Executor, 64 Vcores on a node, and 10 nodes in total, it may look as if we should have 80 Executors. However, spark.executor.instances are set to 79. That’s because we lose one vcore on one Node to ApplicationMaster and Yarn can only allocate 7 Executors instead of 8 on that Node.
References
Explore the references below to dig deeper into various areas of Spark, Yarn, Qubole.
https://docs.qubole.com/en/latest/user-guide/clusters/configuring-clusters.html
https://docs.qubole.com/en/latest/user-guide/clusters/node-bootstrap.html#nodebootstrapscript
https://docs.qubole.com/en/latest/user-guide/spark/index.html
https://docs.qubole.com/en/latest/user-guide/spark/debugging-spark.html
https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
https://hortonworks.com/blog/apache-hadoop-yarn-concepts-and-applications/
https://xgboost.readthedocs.io/en/latest/tutorials/aws_yarn.html



