It is common knowledge that data lakes offer the right architecture to support multiple use cases and tools but can be operationally complex to implement and manage. Qubole provides an open data lake platform that enhances and greatly simplifies data lake projects. Our customers and users operate on petabyte-scale data lake footprints where data analytics challenges are amplified. For users doing data discovery and ad hoc analytics, the right dataset can be hard to find, get access to, and then prepare, and mine for insights. Furthermore, a data warehouse is not an obvious alternative because the data isn’t available there and due to the limited choice of tooling.
In this blog post, we will introduce Qubole’s Workbench application that facilitates self-service data discovery and reduces time-to-insight by allowing users to discover datasets, write queries, analyze results, and share insights. Workbench also provides debug aids such as exact error surfacing and links to troubleshooting guides while working with data processing technologies. Workbench is generally available with Qubole release 59 and documentation for the same is available here. While many tools are available for querying and visualization, Workbench is a unique application as it allows users to easily connect and explore datasets in the data lake using multiple big data engines, and debug in a self-service way.
Qubole Workbench is offered as part of Qubole’s open data lake platform. Admins can easily roll out Workbench to their users and express fine-grained application and data access controls. Qubole uses a SaaS delivery model to provide frequent updates and patches.
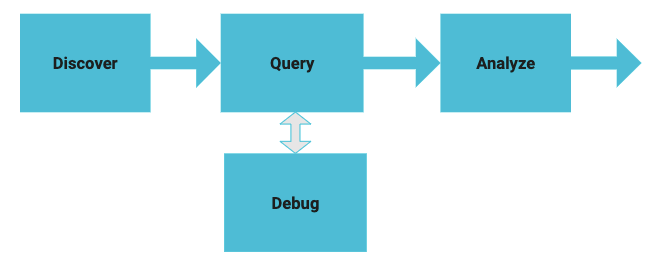
Diagram 1 — Self-service process for data discovery
Workbench includes the following features:
- Discover
- Connect to Hive metastore and other 3rd party data sources.
- Search and browse schema using the table explorer widget.
- Preview data, table info, statistics
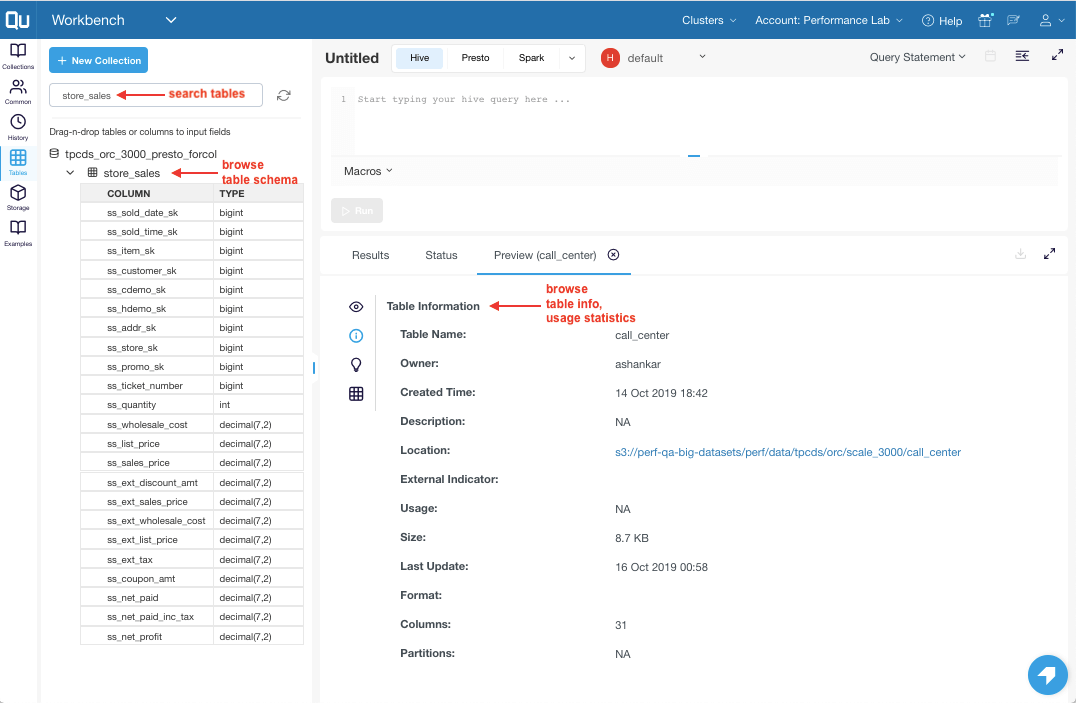
Image 1: Key information aids in the discovery stage
- Query
- Compose SQL and NoSQL queries using the composer.
- Choose from any of the supported analytical engines such as Presto, Spark, Hive, and more.
- Use collections to organize your work as you iteratively build toward the final query.
- View query history, search, and reuse.
- Schedule queries and put workflows into production.
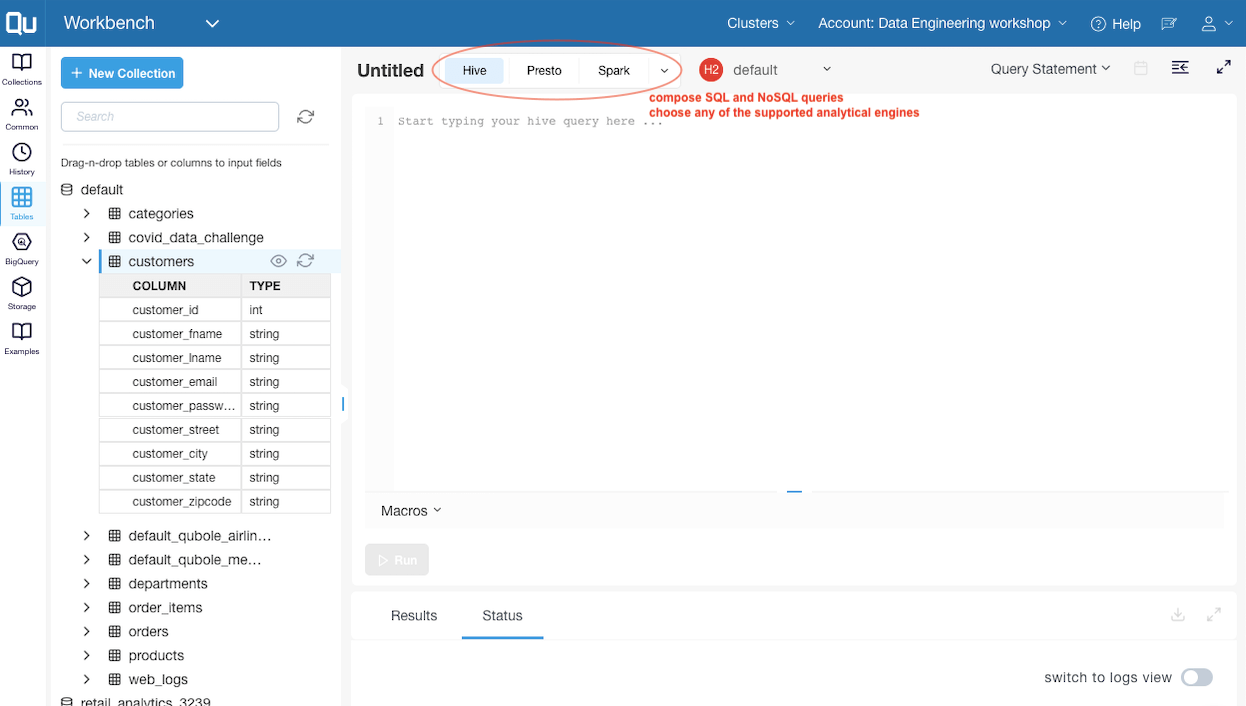
Image 2: Compose SQL and NoSQL queries
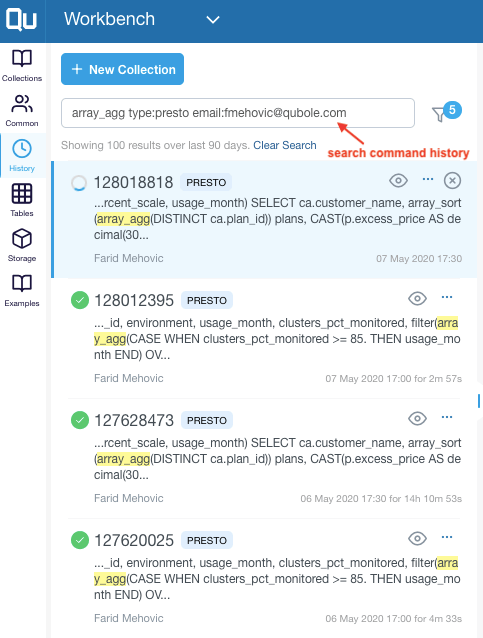
- Analyze
- Download results as csv, tsv.
- Download large results (known to work for 10’s terabytes) as a single file.
- Share query and table permalinks.
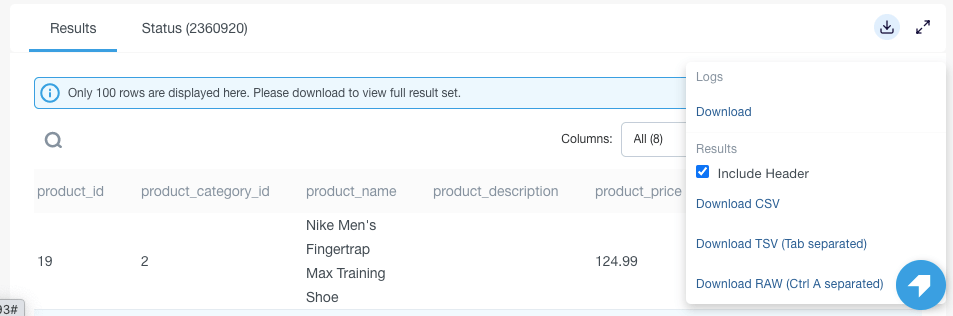
Image 5: Download results as CSV, TSV
- Debug
- Check live cluster health prior to submitting queries.
- See the exact error message and troubleshooting links.
- Get query-specific tips.
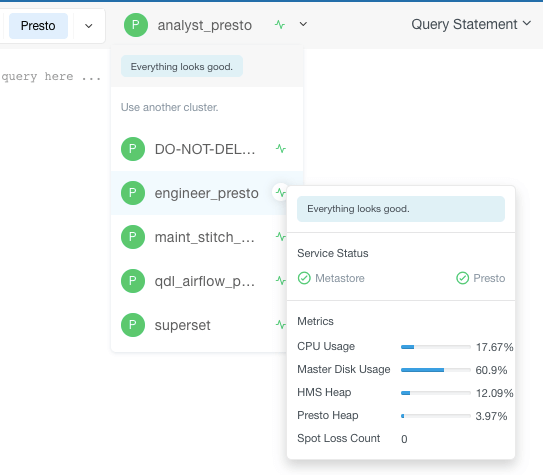
Image 6: Check live cluster health
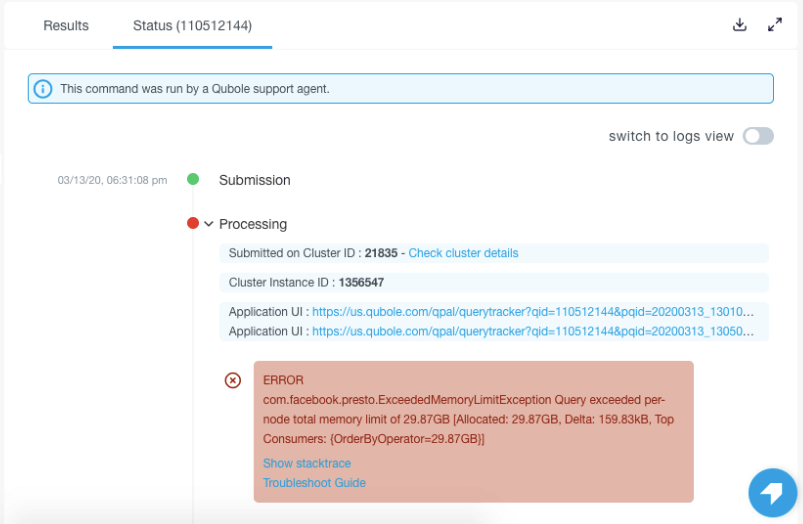
Image 7: Troubleshoot using exact error messages in the status tab
By interacting with our customers and the beta user community, we get a front-row seat to witness the real problems users encounter while performing data discovery on petabyte-scale datasets. We are thankful to many of them for their valuable feedback, direction, and active participation in the beta program. Workbench is used today by data practitioners – both analysts & scientists – working in multiple areas such as customer micro-segmentation, gaming analytics, fraud detection, and digital ad operations. Key benefits for customers are greater productivity, faster time to value, and the ability to support a greater number of end-users.
Below are resources to help you learn more about Qubole Workbench,
You can also sign up for a free trial of Qubole here – https://www.qubole.com/free-trial/.



