Total Cost of Ownership Comparison
Looking to optimize the cost of your big data platform and find the best price? Consider the following factors:
- Cloud is almost always more cost-efficient than on-premise deployment
- How you deploy in the cloud can make a big difference in your total cost of ownership
- Cloud-native features can make a dramatic difference in TCO
Three reasons why big data in the cloud is more cost-efficient than on-premise?
- Pay for what you use vs Pay for peak workload
- Opex vs Capex
- Lower DevOps / DataOps Cost
Cloud vs On-Premises TCO
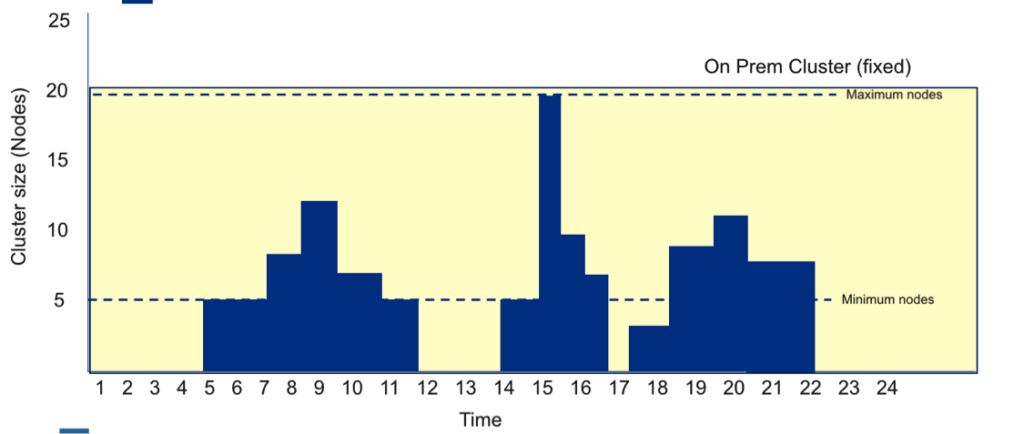
On-premise deployments typically have higher TCO because you have to provision your infrastructure to accommodate your peak workload. This can lead to significant waste due to unutilized infrastructure. The yellow area below represents an idle infrastructure that you paid for but aren’t currently using.
On-Premises (Cloudera, Hortonworks, MapR)
| Cloud (Cloudera Altus, Amazon EMR, HDInsights, Databricks, Qubole)
| |
| Infrastructure (hardware/software) | Upfront hardware/software CapEx plus ongoing operations OpEx | Pay as you use OpEx |
| DevOps / DataOps | In-house expertise or external consultants required for deployment and operations | DataOps expertise is required for operations only |
| Upgrades / Expansion | Same as deployment | Elastic |
| Deployment time | Slow | Instant |
| Pricing Model | High CapEx plus high OpEx | Pay as you use Opex |
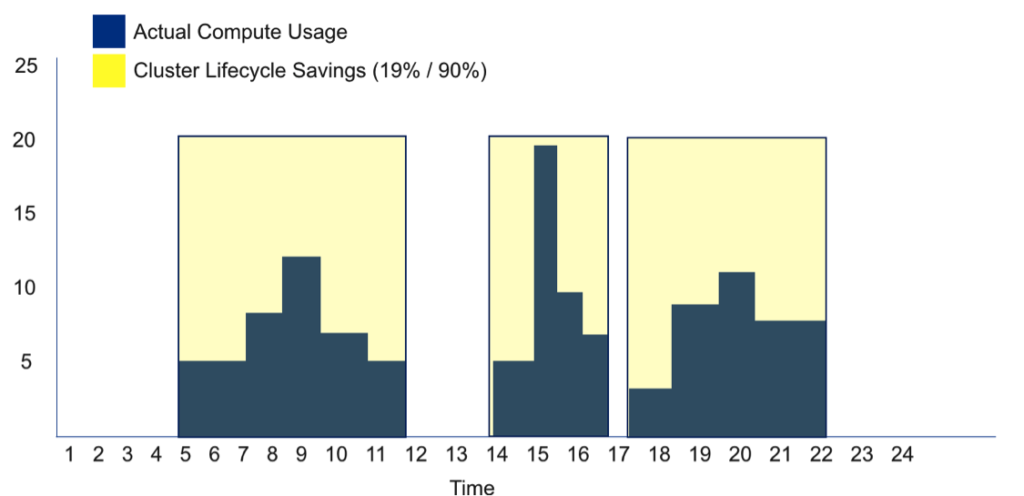
TCO for cloud-based big data is typically at least 19% lower than on-premise and can be as high as 90%.
Consider your deployment model
There are a number of ways to deploy big data in the cloud: Static “always-on” clusters, big-data-as-a-service, and “serverless” systems are the most popular. The deployment model can have a big impact on TCO. Static clusters reduce the upfront CapEx costs and time-to-market but fail to take full advantage of the elasticity benefits of the cloud. Cluster lifecycle management is one way to leverage the cloud to reduce TCO. Serverless systems offer great flexibility and lower administrative overhead but they compromise on capacity and control. They’re best used for smaller ad hoc workloads.
There are two ways to benefit from the elasticity of the cloud. Both involve optimizing the use of compute because in the cloud compute and storage are de-coupled and compute is expensive while storage is cheap.
- Cluster lifecycle management makes clusters ephemeral – they get created when needed and terminated when not in use, automatically. By eliminating compute costs when no workloads are running, you can reduce TCO substantially (see diagram, below)
- Auto-Scaling can add nodes to a running cluster as needed. Big data workloads can be “bursty” so a statically sized cluster can create lots of wasted compute time. With auto-scaling, you can dynamically add nodes to a running cluster to increase capacity as needed. Some solutions can auto-scale down as well – removing idle nodes when possible to reduce TCO even further.
| Static clusters in the cloud (Apache, Cloudera, Hortonworks) | Big-data-as-a-service (Qubole, Databricks, EMR, HDInsights) | Serverless (Athena, BigQuery) | |
| Cluster lifecycle management | No | Yes | N/A |
| Autoscaling | No | Yes | Yes |
TCO for big data-as-a-service is typically at least 48% lower than other cloud deployment models and can be as high as 90%.
Cloud-native Optimizations
Just because you deploy in the cloud doesn’t automatically mean you are taking maximum advantage of the cloud and optimizing TCO.
Cluster lifecycle management and auto-scaling improve TCO by reducing the amount of idle (wasted) infrastructure.
Get started with Qubole today.


