DATA LAKE VS DATA WAREHOUSE
Today, terabytes and petabytes of data are being generated every second, and finding storage solutions for these massive sets of data volumes is of utmost importance. Intricate machines and technologies now collect an incredible breadth of data — over 2.5 quintillion bytes every day! — from equipment sensors, logs, users, consumers, and elsewhere. Data storage isn’t as simple as it once seemed. When it comes to managing and storing data, data managers consider using either data lakes or data warehouses as repositories.
As the volume, velocity, and variety of data increases, the choice of the right data platform to manage data has never felt more important. Should it be the venerable data warehouse that has served our needs until now, or should it be the data lake that promises support for any kind of data for any type of workload?
Here, we take a deep dive into both platforms.
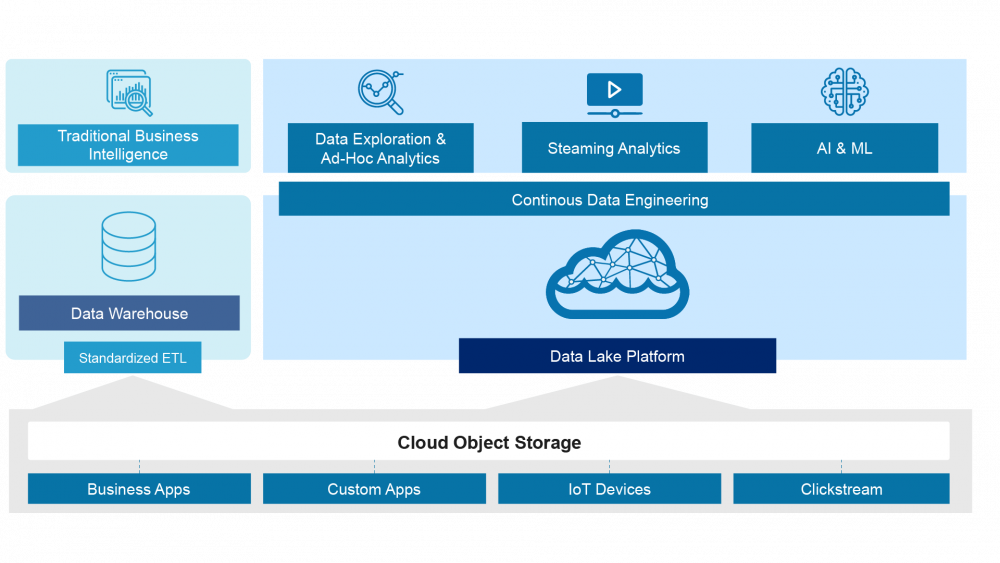
Data Lake Capabilities
A data lake is a central repository that allows you to store all your data – structured and unstructured – in volume. Data typically is stored in a raw format without first being processed or structured. From there, it can be polished and optimized for the purpose at hand, be it a dashboard for interactive analytics, downstream machine learning, or analytics applications.
Think of it this way, a data lake is like a large water body, say a lake in its natural state. The data lake is created with data streaming in from various sources, and then, multiple users can come to the lake to examine it and take samples. The beauty of a data lake is that everyone is looking at and operating from the same data. Eliminating multiple data sources and having a referenceable ‘golden’ dataset in the data lake leads to alignment within an organization because any other downstream repository or technology used to access intelligence in your organization will be synchronized. This is critical. With this centralized source of data, you’re not pulling bits of data from disparate silos; everyone in the organization has a single source of truth.
This model provides near-unlimited capabilities for companies’ analytics lifecycles:
Ingest: Data arrives in any raw format and is stored for future analysis or disaster recovery. Companies typically segment out several data lakes depending on privacy, production access, and the teams that will be leveraging the incoming information.
Store: Data lakes allow a business to manage and organize nearly infinite amounts of information. Cloud object stores (AWS S3, Azure Blob, Google Cloud Storage, etc.) offer high availability access for big data computing at an extremely low cost.
Process: With cloud computing, infrastructure is now simply an API call away. This is when data is taken from its raw state in the data lake and formatted to be used with other information. This data is also often aggregated, joined, or analyzed with advanced algorithms. The data is then pushed back into the data lake for storage and further consumption by business intelligence or other applications.
Consume: When companies talk about having a self-service data lake, Consume is typically the stage in the life-cycle, they are referencing. At this point, data is made available to the business and customers for analytics as their needs require. Depending on the type of complex use cases, end-users may also indirectly or directly use the data in the form of predictions (forecasting weather, financials, sports performance, etc.) or perceptive analytics (recommendation engines, fraud detection, genome sequencing, etc).
Data lakes support native streaming, where streams of data are processed and made available for analytics as it arrives. The data pipelines transform the data as it is received from the data stream and trigger computations required for analytics. The native streaming feature of the data lake makes them highly suitable for streaming analytics.
Data Warehouses Capabilities
The data warehouse, invented in late 1980, was designed for highly structured data generated by business apps. It brings all your data together and stores it in a structured manner. It is typically used to connect and analyze data from heterogeneous sources.
The data warehouse architecture relies on the data structure to support highly performant SQL (Structured Query Language) operations. Data warehouses are purpose-built and optimized for SQL-based access to support Business Intelligence but offer limited functionality for streaming analytics and machine learning. They are constrained by the ETL requirement to pre-process data before storing it.
Data warehouses require sequential ETL to ingest and transform the data before its usage for analytics, and hence they are inefficient for streaming analytics. Some data warehouses support “micro-batching” to collect data often and in small increments. It supports sequential ETL operations, where data flows in a waterfall model from the raw data format to a fully transformed set, optimized for fast performance.
Data warehouse stores the data in a proprietary format. Once the data is stored in the data warehouse, access to this data is limited to SQL and any custom drivers provided by the data warehouse. Some newer data warehouses support semi-structured data such as JSON, Parquet, and XML files; they provide limited support and diminished performance for such data sets compared to structured data sets. Data warehouses do not support the storage of unstructured data.
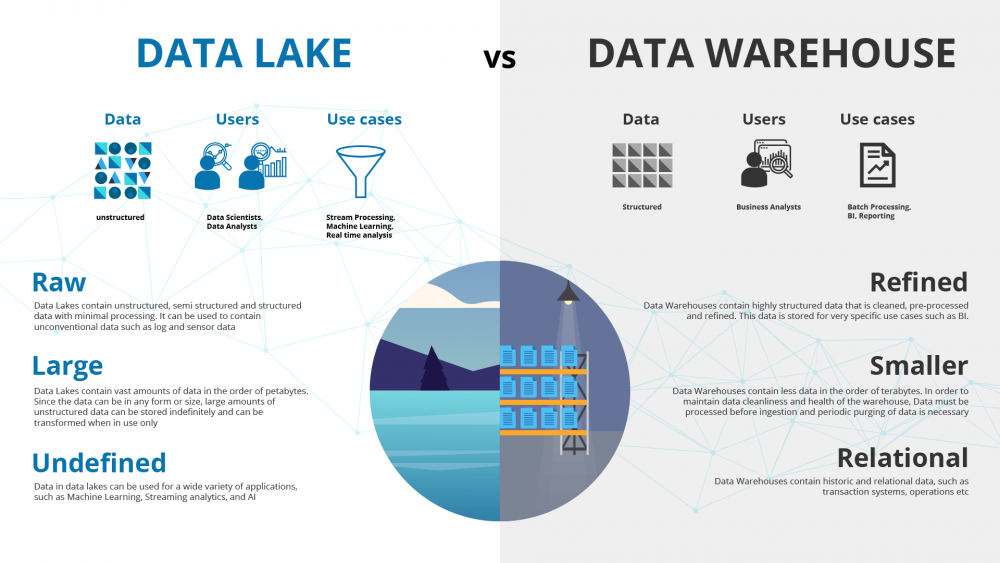
Data Lake vs Data Warehouse
Data warehouses and Business Intelligence tools support reporting and analytics on historical data, while data lakes support newer use cases that leverage data for machine learning, predictions, and real-time analysis.
While some data warehouses extend their SQL-based access to offer machine learning functionality, they do not offer native support to run widely available, programmatic data processing frameworks such as Apache Spark, Tensorflow, and more.
In contrast, data lakes are ideal for machine learning use cases. They provide not only SQL-based access to data but also offer native support for programmatic distributed data processing frameworks like Apache Spark and Tensorflow through languages such as Python, Scala, Java, and more.
Data warehouses require sequential ETL to ingest and transform the data before its usage for analytics, and hence they are inefficient for streaming analytics. Some data warehouses support ‘micro-batching’ to collect data often and in small increments. This stream-to-batch conversion increases the time between the arrival of data to its use for analytics making data warehouses inadequate for many forms of streaming analytics.
Data lakes support native streaming where streams of data are processed and made available for analytics as it arrives. The data pipelines transform the data as it is received from the data stream and trigger computations required for analytics. The native streaming feature of the data lake makes them highly suitable for streaming analytics.
Data warehouses support sequential ETL operations, where data flows in a waterfall model from the raw data format to a fully transformed set, optimized for fast performance.
In contrast, Data lakes are exceptionally strong for use cases that require continuous data engineering. In data lakes, the waterfall approach of ETL is replaced by iterative and continuous data engineering. The raw data that lands in a data lake can be accessed and transformed iteratively via SQL and programmatic interfaces to meet the changing needs of the use case. This support for continuous data engineering is critical for interactive analytics and machine learning.
Data warehouse stores the data in a proprietary format. Once the data is stored in the data warehouse, access to this data is limited to SQL and any custom drivers provided by the data warehouse. Some data warehouses can store XML, ORC, and Parquet files; however, these files are vendor locked and available through access mechanisms supported by the data warehouse.
Learn more about the difference between the two platforms in the infographic below:
Debunking The Top 3 Myths About Data Lakes and Data Warehouses
Let’s tackle some common myths about two popular types of data storage:
Myth #1: You Only Need One Or The Other
Nowadays, you often hear people talk about data lakes and data warehouses as if businesses must choose one or the other. But the reality is that data lakes and data warehouses serve different purposes. While both provide storage for data, they do so using a different structure, support different formats, and are optimized for different uses. Often, a company may benefit from using a data warehouse as well as a data lake.
Data warehouses best serve businesses looking to analyze operational systems data for business intelligence. Data warehouses work well for this because the stored data is structured, cleaned, and prepped for analysis. Alternatively, data lakes allow businesses to store data in any format for virtually any use, including Machine Learning (ML) models and big data analysis.
Myth #2: Data Lakes Are Niche; Data Warehouses Aren’t
Artificial intelligence (AI) and ML represent some of the fastest-growing cloud workloads, and organizations are increasingly turning to data lakes to help ensure the success of these projects. Because data lakes allow you to store virtually any type of data (structured and unstructured) without first prepping or cleaning, you’re able to retain as much potential value as possible for future, unspecified use. This setup is ideal for more complex workloads like machine learning models where the specific data types and uses have yet to be determined.
Data warehouses may be the more well-known of the two options, but data lakes (and similar types of storage infrastructure) are likely to continue rising in popularity in conjunction with data workload trends. Data warehouses work well for certain types of workloads and use cases, and data lakes represent another option that serves other types of workloads.
Myth #3: Data Warehouses Are Easy To Use, While Data Lakes Are Complex
Data lakes require the specific skills of data engineers and data scientists (or experts with similar skill sets) to sort and make use of the data stored within. The unstructured nature of the data makes it less readily accessible to those without understanding how the data lake works.
However, once data scientists and data engineers build data models or pipelines, business users can often leverage integrations (custom or pre-built) with popular business tools to explore the data. Likewise, most business users access data stored within data warehouses through connected business intelligence (BI) tools like Tableau and Looker. With the help of third-party BI tools, business users should be able to access and analyze data, whether that data is stored in a data warehouse or a data lake.
Data Processing
In an episode of Open Data Lake Talks, John Riwerts, Vice President – Engineering at Acxiom, talks about data lakes and data warehouses and whether we should look at collisions or synergies when thinking about them. Try to minimize the impact of the three slowest things in your data platform – people, network, and disk operations. While people can never be as fast as computers, he describes the other two as physics problems. To reduce the impact of these problems, avoid duplicating data all over the place, invest in the platform’s ability to read and process data from different locations, including transactionally, pub/subsystems, and data warehouse systems, without having to move that day. John also recommends the use of data processing engines such as Apache Spark to build data pipelines. John’s principles for building a modern data platform are
- Keep it simple. Don’t over-architect or over-engineer it
- Use the right tool for the right job.
- Let the use case determine what you should be using.
- Use the cloud to scale.
- Separate data from context. This will enable the use of data for multiple use cases
Data Lakes and Data Warehouses: Use Cases
Data Lake has emerged as a robust platform that businesses can use to manage, mine, and monetize vast stores of unstructured data for competitive advantage. As a result, the rate of adoption of Data Lake platforms by companies has increased dramatically.
In this rush to leverage big data, there has been a misconception that Data Lake is meant to replace the data warehouse, when in fact, Data Lake is designed to complement traditional relational database management systems (RDBMS).
Data warehouses work well for certain types of workloads and use cases, and data lakes represent another option that serves other types of workloads.
According to John Riwerts, use cases should drive the data platform architecture. “If your use case needs the speed, has a known data model, is fully structured, or pretty close to it, then a SQL data warehouse will suffice. However, if you need just in time flexibility to model your data and use it for multiple workloads, you should use a data lake,” Riwerts opines.
He believes in a best-of-breed solution that relies on multiple technologies, including a data warehouse and data lake. Ultimately his choice balances the complexity and TCO of managing multiple technologies with the ability to run a larger variety of workloads in a performant and cost-effective manner.
What Does the Future Hold?
We are at a point now where we will be able to use data not only to review the past but understand the present and even to predict the future. The data and tools will continuously evolve to help us get there in almost real-time.
“Separate data from context. Data coming in doesn’t necessarily have a context of what you want to use with it. So, separate the idea of getting data to a location prior to figuring out what you want to do with it. Because in all reality, you’re going to have multiple uses of that data. And so, you never know what you may use that data for. So, if you start with just getting the data in first, and then figuring out what you want to do with it, it generally leads to a more positive outcome with that data,” John explains.
Debanjan Saha, VP and GM of Data Analytics services at Google Cloud, believes that the convergence of data warehouses and data lakes will happen in the near future.
“The data warehouse vendors are gradually moving from their existing model to the convergence of data warehouse and data lake model. Similarly, the vendors who started their journey on the data lake-side are now expanding into the data warehouse space,” Debanjan said in his keynote address at the Data Lake Summit.
He further added, “Convergence is happening from both sides. For instance, BigQuery is now letting organizations query data on Amazon S3. Similarly, data lake platforms like Databricks and Qubole are now decisively moving towards data warehousing use cases. You can have managed storage with ACID properties, transactional consistency, snapshot, etc., and integrate the query engine more with the storage management and create a lake house paradigm for their customers. We are doing the same thing with Dataproc. For example, with Dataproc, you can run SQL engines and use data in BigQuery. Convergence between data lake and data warehouse is not just in talks but in reality.”


