What Is Apache Airflow?
Apache Airflow is an open-source tool to programmatically author, schedule, and monitor data workflows. With Airflow, users can author workflows as Directed Acyclic Graphs (DAGs) of tasks. A DAG is the set of tasks needed to complete a pipeline organized to reflect their relationships and interdependencies. Airflow’s rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed. Airflow connects out-of-the box with multiple data sources, and it can send an alert via email or Slack when a task completes or fails.
Because workflows are defined as code, they become more maintainable, version-able, testable, and collaborative. Airflow is distributed, scalable, and flexible, which makes it well suited to handle the orchestration of complex business logic. Apache Airflow follows the following principles:
- Dynamic: Airflow pipelines are configured as code (Python), allowing for dynamic pipeline generation. This allows for users to write code that instantiates pipelines dynamically.
- Extensible: Easily define your own operators and executors, and extend the library so it fits the level of abstraction that suits your environment.
- Elegant: Airflow pipelines are lean and explicit. Parameterizing your scripts is built into the core of Airflow using the Jinja templating engine.
- Scalable: Airflow has a modular architecture and uses a message queue to communicate with and orchestrate an arbitrary number of workers.
How Is Airflow Used?
Apache Airflow is used for the scheduling and orchestration of data pipelines. Orchestration of data pipelines refers to the sequencing, coordination, scheduling, and management of complex data pipelines from diverse sources. These data pipelines deliver data sets that are ready for consumption either by business intelligence applications and/or data science ML models that support big data applications.
Efficient, cost-effective, and well-orchestrated data pipelines help data scientists come up with better-tuned and more accurate Machine Learning (ML) models, because those models have been trained with complete data sets and not just small samples. Airflow is natively integrated to work with big data systems such as Hive, Presto, and Spark, making it an ideal framework to orchestrate jobs running on any of these engines. Organizations are increasingly adopting Airflow to orchestrate their ETL/ELT jobs.
Hundreds of organizations, including Adobe, Airbnb, Astronomer, Etsy, Google, ING, Lyft, NYC City Planning, Paypal, Polidea, Qubole, Quizlet, Reddit, Reply, Solita, Square, Twitter, and United Airlines, to name a few. A more complete list of known users can be found here.
Airflow on Qubole
With Airflow on Qubole, you can author, schedule, and monitor complex data pipelines. Eliminate the complexity of spinning up and managing Airflow clusters with one-click start and stop. Furthermore, seamless integrations with Github and AWS S3 ensure your data pipeline runs as smoothly as possible. Also, with Qubole-contributed features such as the Airflow QuboleOperator customers have the ability to submit commands to Qubole, thus giving them greater programmatic flexibility.
What’s New with Airflow on Qubole
Qubole continues to push the limits of possibility in the big data and cloud computing spaces. Cutting-edge innovation and broad industry expertise are critical components of Qubole’s mission to make big data on the cloud accessible and affordable for all enterprises. In our latest release we introduced the following features that make using Qubole Airflow even easier:
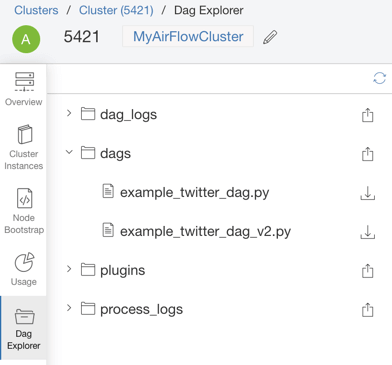
DAG Explorer
For the continuous development, integration, and deployment of Airflow DAGs, Qubole has introduced tooling to upload Airflow Python DAG files to Amazon S3, edit them in place, and periodically sync them with Airflow clusters (in the background). You can also download other relevant Airflow files such as process and log files from the Airflow cluster page. This aids the quick, iterative development of complex workflows and keeps the files in sync. More information can be found here.
 Airflow on Anaconda Configuration
Airflow on Anaconda Configuration
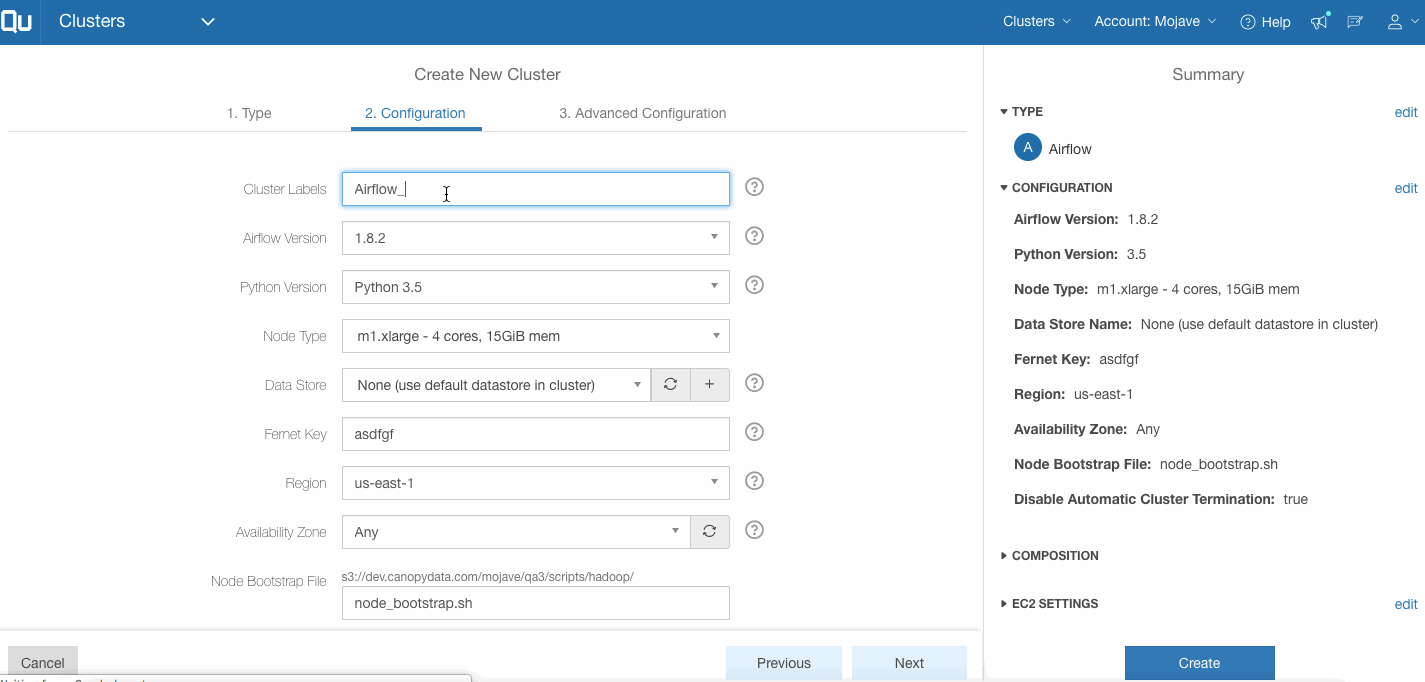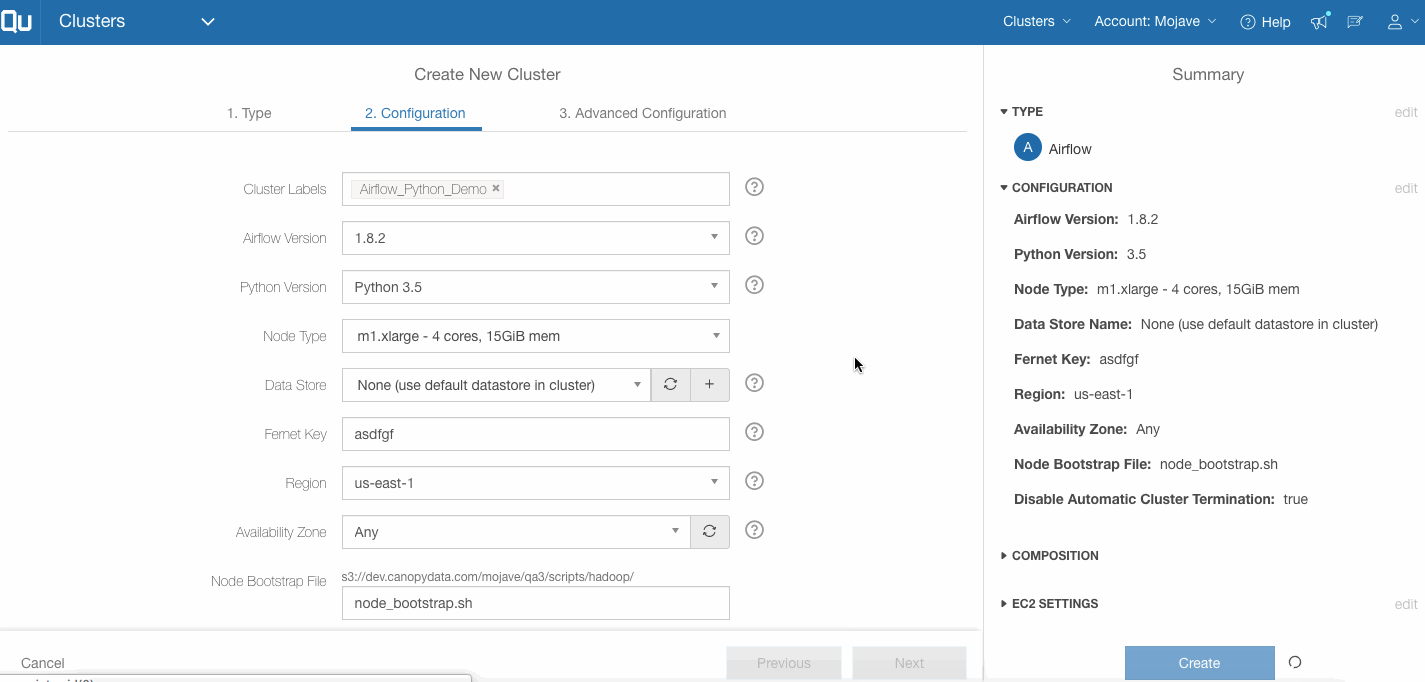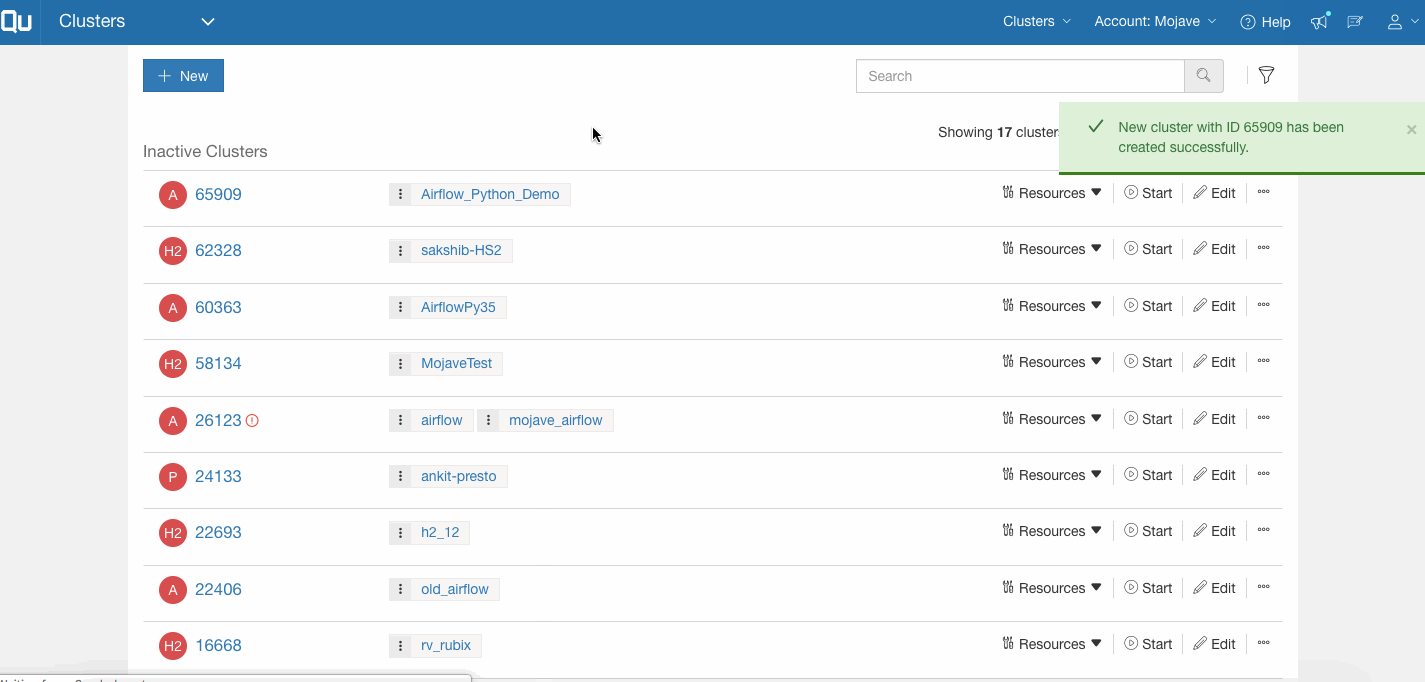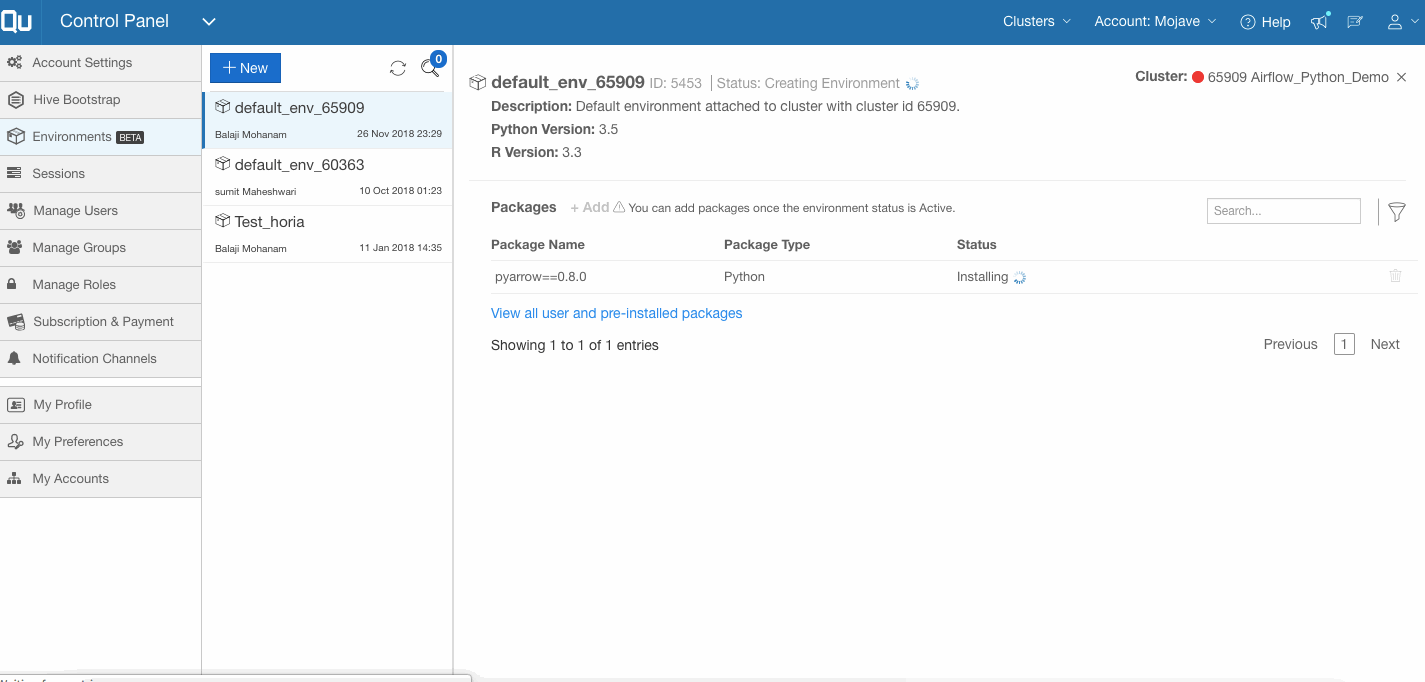
Airflow on Anaconda Virtual Environment
You can now run Airflow on an Anaconda virtual environment. Users have the option of choosing the Python version while creating an Airflow cluster. Selecting Python 3.5 triggers the Airflow setup on the Anaconda environment along with support for package management (ability to install/uninstall packages on the cluster from the Qubole UI) for the cluster. More information can be found here.
 Airflow on Anaconda Configuration
Airflow on Anaconda Configuration
At Qubole, not only are we a provider, but also a big consumer of Airflow as well. For example, our whole Insight and Recommendations platform is built around Airflow only, where we process billions of events every month from hundreds of enterprises and generate insights for them on big data solutions like Apache Hadoop, Apache Spark, and Presto. We are very impressed by the simplicity of Airflow and ease at which it can be integrated with other solutions like clouds, monitoring systems or various data sources.
– Sumit Maheshwari, Engineering Manager at Qubole.
To learn more about how our customers leverage Qubole, download our white paper on Big Data Engineering for Machine Learning.



