Machine Learning
As a consumer of goods and services, you experience the results of Machine Learning (ML) whenever the institutions you rely on use ML processes to run their operations. You may receive a text message from a bank requiring verification after the bank has paused a credit card transaction. Or, an online travel site may send you an email that offers personalized accommodations for your next personal or business trip.
Machine Learning Model Deployment
The work that happens behind the scenes to facilitate these experiences can be difficult to fully realize or appreciate. An important portion of that work is done by the data engineering teams that build the data pipelines to help train and deploy those ML models. Once focused on building pipelines to support traditional data warehouses, today’s data engineering teams now build more technically demanding continuous data pipelines that feed applications with artificial intelligence and ML algorithms. These data pipelines must be cost-effective, fast, and reliable regardless of the type of workload and use case.
Data Processing Engine
Due to the diversity of data sources and the volume of data that needs to be processed, traditional data processing tools fail to meet the performance and reliability requirements for modern machine learning applications. The need to build reliable pipelines for these workloads coupled with advances in distributed high performance computing has given rise to big data processing engines such as Hadoop.
Let’s quickly review the different engines and frameworks often used in data engineering aimed at supporting ML efforts:

Apache Hive
Hive is an Apache open-source project built on top of Hadoop for querying, summarizing, and analyzing large data sets using a SQL-like interface. Apache Hive is used mostly for batch processing of large ETL jobs and batch SQL queries on very large data sets as well as exploration on large volumes of structured, semi-structured, and unstructured data.

Apache Spark
Spark is a general purpose open-source computational engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation. Spark is also distributed, scalable, fault tolerant, flexible, and fast.

Presto
Presto is an open-source SQL query engine developed by Facebook. Presto is used for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto was built to provide SQL query capabilities against disparate data sources, which allows Presto users to combine data from multiple data sources in one query.

Airflow
Although technically not a big data engine, Airflow is an open-source tool to programmatically author, schedule, and monitor data workflows. With Airflow, users can author workflows as Directed Acyclic Graphs (DAGs) of tasks. A DAG is the set of tasks needed to complete a pipeline organized to reflect their relationships and interdependencies.
Data Engineering
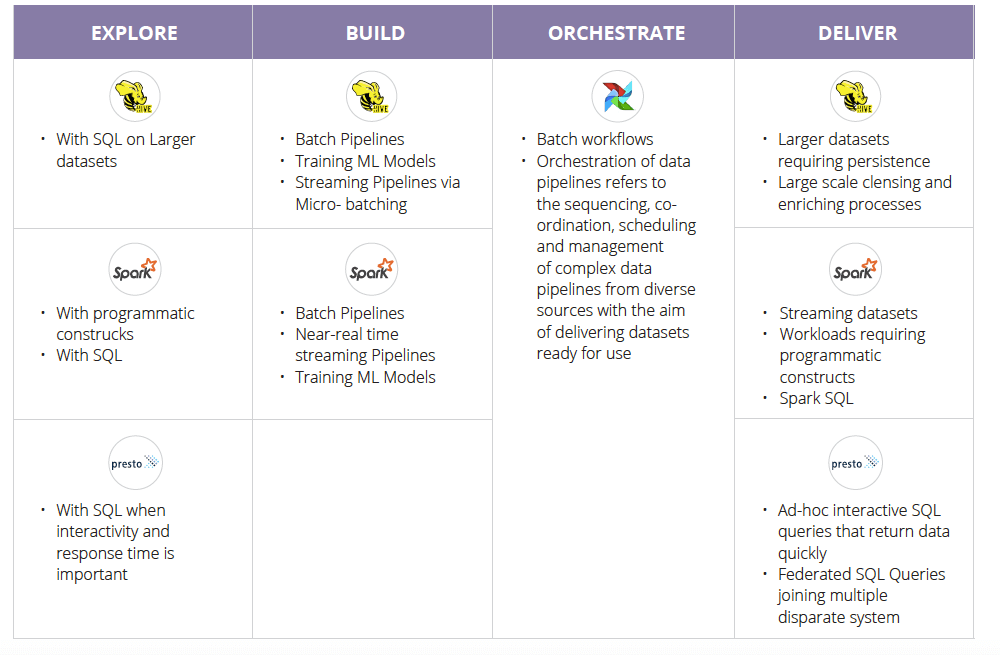
While the typical steps of data engineering may be standardized across industries — data exploration, building pipelines, data orchestration, and delivery — organizations have various workload types and data engineering needs. That’s where support for multiple engines and workloads becomes essential. Let’s talk about which engines are most effective for each stage of the data engineering cycle:
Data Exploration
Data engineering always starts with data exploration. Data exploration involves inspecting the data to understand its characteristics and what it represents. The learnings acquired during this stage will impact the amount and type of work that the data scientist will conduct during their data preparation phase.
Hadoop/Hive is an excellent choice for data exploration of larger unstructured data sets, because of its inexpensive storage and its compatibility with SQL. Spark works well for data sets that require a programmatic approach, such as with file formats widely used in healthcare insurance processing. On the other hand, Presto provides a quick and easy way to access data from a variety of sources using the industry standard SQL query language.
Data Pipelines
Data pipelines carry and process data from data sources to the Business Intelligence (BI) and ML applications that take advantage of it. These pipelines consist of multiple steps: reading data, moving it from one system to the next, reformatting it, joining it with other data sources, and adding derived columns (feature engineering).
When the persistence of large data sets is important, Hive offers diverse computational techniques and is cost effective. Alternatively, Spark offers an in-memory computational engine and may be the better choice if processing speed is critical. Spark also offers the best facilities for near real-time data streaming, allowing engineers to create streaming jobs the same way they write batch jobs. However, micro-batching with Hive may be a workable and more economical option.
Orchestrating Data Pipelines
Orchestration of data pipelines refers to the sequencing, coordination, scheduling, and management of complex data pipelines from diverse sources with the aim of delivering data sets that are ready for consumption either by business intelligence applications and/or data science ML models.
Airflow is natively integrated to work with big data systems such as Hive, Presto and Spark, making it an ideal framework to orchestrate jobs running on any of these engines. As a result, Airflow works well with workloads that follow the batch processing model.
Data Sets
Qubole’s multi-engine platform allows data engineers to build, update and refine data pipelines in order to reliably and cost-effectively deliver those data sets on predefined schedules or on-demand. Qubole provides the ability to publish data through notebooks or templates and deliver the data to downstream advanced analytics and ML applications.
At Qubole we believe your use case should determine the delivery engine. For example, if the information is going to be delivered as a dashboard or the intention is to probe the resulting data sets with low-latency SQL queries, then Presto would be the optimal choice. With Presto, queries run faster than with Spark because there is no consideration for mid-query fault-tolerance. Spark, on the other hand, supports mid-query fault-tolerance and will recover in case of a failure — but actively planning for failure impacts Spark’s query performance, especially in the absence of any technical hiccups.
Machine Learning Data Pipelines
When building a house, you choose different tools for different tasks — because it is impossible to build a house using only one tool. Similarly, when building data pipelines, you should choose the optimal big data engine by considering your specific use case and the specific business needs of your company or department.
Building data pipelines calls for a multi-engine platform with the ability to autoscale. The table below shows how Qubole customers apply different engines to fulfill different stages of the data engineering function when building ML data pipelines:
Most Common Engine and Framework Usage Patterns
Interested in learning more? Check out our upcoming webinar about building scalable ML data pipelines.



