The following is a recap from a Bellevue Artificial Intelligence Meetup event hosted by Qubole and held with Expedia on July 20th, 2018. The topics presented relate to Expedia’s Alpha team, a member of their digital email service department.
At Expedia, the Alpha team (A-Team) is a member of the Omni-Channel Communications Team and is responsible for delivering marketing emails to Expedia customers worldwide. Their product drives key insights that leverage user preferences and behaviors as individuals are browsing the Expedia website. As a result, the A-Team can identify trip phases and profile every Expedia customer accordingly. However, this was not the case two years ago before the team moved to big data operations in the cloud.
In early 2017, the team was tasked with delivering more personalized emails to encourage recent customers to purchase full packages (e.g. if someone bought a flight but no hotel, they would get a follow-up email with a hotel offer for that given area). Yet this proved to be quite a challenge, as the team’s underlying operations were in an on-premises Structured Query Language (SQL) data warehouse that could barely scale beyond two million users and had no data science capabilities to add more dynamic features.
The Beginning of Big Data in the Cloud for the Alpha Team
Prior to moving to the cloud, the A-Team was only running on SQL. The solution in place was on-premises and couldn’t handle seasonal spikes or scale on demand when the target audience was wider than usual. Furthermore, the inherent nature of the associated model required highly customized content. The data operation was extremely time-consuming and strained to compute and storage servers.
As a result, the A-Team could not personalize email content on a user-to-user basis. Instead, the small audience (about two million users) were the recipients of relatively similar content that did not increase conversions. The infrastructure also had resource limitations that prevented the team from scaling to include more users in a cost-effective way.
The team recognized these issues of scale and flexibility and was able to test a possible solution by building a POC of their pipeline on Qubole. This provided the opportunity to learn Apache Spark while avoiding the typical mistakes of those new to distributed compute in AWS. The implemented pipeline was built in a Qubole Spark Notebook, and the A-Team immediately began optimizing the code with Python.
Following the POC, the pipeline showed direct business value impacts to revenue growth and costs. The pipeline allowed them to scale to 20 million users per weekday as well as deliver dynamic content, but it remained a relatively expensive operation. The team realized there was still work to be done to truly scale worldwide and deliver personalized emails for each customer without causing costs to skyrocket.
Optimizing Cloud Big Data Operations at Scale
To provide the level of personalization needed to increase user engagement, the A-Team needed to implement customer segmentation into the email pipeline. Getting the necessary level of customer segmentation granularity for Expedia users is quite challenging because of two primary factors: search behavior and booking activities. Therefore, properly profiling these events before segmentation is critical to developing a successful recommendation engine.
To solve this issue, the A-Team experimented with several approaches and technologies — ultimately selecting Qubole Spark, a cloud-based big data platform that provides autoscaling clusters for Spark. Qubole enabled the A-Team to focus on building new value-add features for their customers while addressing the scaling issues of their on-premises systems.
“One of the coolest things about Qubole and Spark clusters is that most Spark cluster users end up using it for analytical purposes, but we actually run production and business-impacting jobs on these clusters.
– Jagannath Narasimhan, Technical Product Manager
With the new big data operations in AWS, the team was able to scale the Qubole pipeline up to 40 million users globally and deliver 500 million emails per month. However, this brought new scalability challenges relating to financial governance as well as stability.
By scaling the Qubole pipeline, the A-Team was able to achieve significant savings on EC2 costs from their 75-node AWS R4 instance-type cluster. Due to Python’s limitations, the pipeline was also facing stability issues with jobs occasionally failing and needing to be rerun. Further optimizations were required both to stabilize the daily production pipelines (to prevent failures that would further drive up costs), as well as improve performance and cloud utilization to save money on existing operations. At this point, the team began investigating the capabilities of Scala.
“One of our biggest blockers, when we were trying to optimize for cost, as we didn’t know how much each of our clusters cost.
– Jagannath Narasimhan
The team embarked on a large stability project to port the code from Python to Scala, as well as optimize the queries. The change enabled them to reduce their cluster size to 25 nodes (a 66 percent reduction). They also moved development to an IDE, which allowed them to reduce additional resource overhead as well as improve their autoscaling approach to inactive clusters.
The Current State of Their Cloud Data Operations
Today the team is directly increasing revenue at Expedia by leveraging Qubole Spark pipelines to send out marketing emails and build user profiles. These emails service users worldwide, as well as provide push notifications to the Expedia mobile app.
Figure 2 (below) shows the data flow of scheduled jobs in Qubole. This is the email pipeline that brings together the customer and content data sources, which are processed through Qubole and then triggers workloads that generate personalized emails for each target customer. Upon delivery, a tracking system granularly monitors any actions taken on the associated email and sends feedback to the A-Team model for further analysis as well as optimization of future campaigns
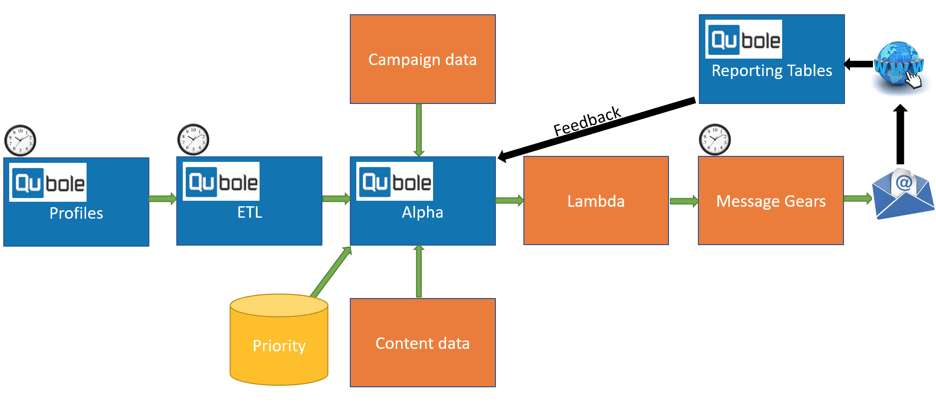
Figure 2: A-Team overall flow
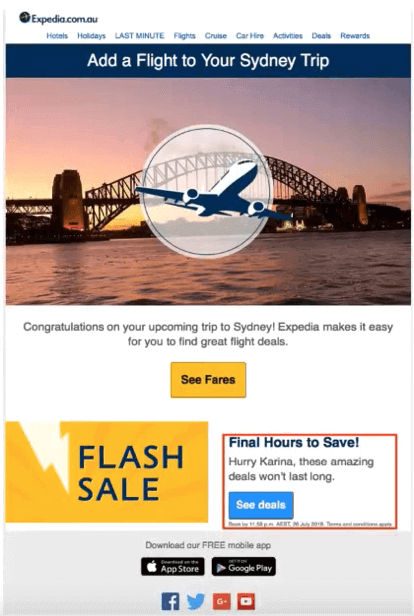
In-house tools, such as Alpha and Ocelot, allow the A-Team to effectively manage and build campaigns — not only for the Expedia brand but for all associated brands — and create separate marketing pipelines as needed. Such tools enable Expedia Managers to store users’ profiles and build content, and later relate content and profiles to perform a scheduled delivery of marketing campaign emails like the one displayed in Figure 1 (see image, above).
Time-sensitive campaign pipelines run on Spark clusters, which utilize scheduled queries that automatically deploy campaigns based on users’ trip phases. Expedia has 35 points of sale (POS) representing diverse geographical areas and countries worldwide (US, LATAM, APAC, EMEA, etc.), so this means processing needs to happen in a number of different regions to meet service level agreements (SLAs). The mix of Qubole Spark and AWS infrastructure allows the team to seamlessly scale-out campaigns and deliver targeted emails to a range of 20 to 40 million customers in a given day.
A parallel Jenkins-powered orchestration allows the customization of each POS through three Qubole clusters that guarantee delivery on specific SLAs. Moreover, a live test cluster guarantees delivery simulation for validation 24 hours before the large-scale operation is run and the marketing campaign is delivered to customers. Testing with production data in this manner allows the A-Team to find and address issues before the actual campaign is launched. (Figure 3, below, shows more detail of this process.)
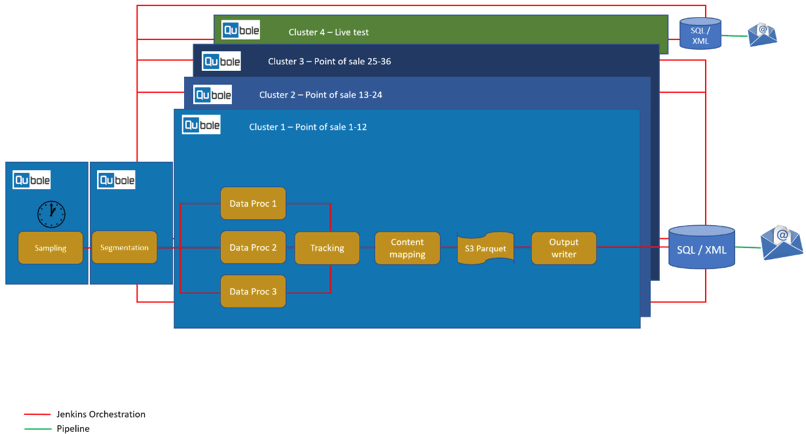
Figure 3: A-Team email pipeline
Conclusion
The A-Team workloads are High Business Impact (HBI), and therefore mission-critical to completing on time. The current architecture, based on all worker nodes being on-demand, guarantees no downtime and effective delivery of marketing campaigns. Moreover, R&D environments are easily accessible by ephemeral ad hoc clusters spin that spin up/down as needed. By doing so, developers have the freedom to develop and test as needed.
By moving to automated Apache Spark workloads with Qubole in AWS, the Alpha data team was able to quickly gain the experience to be ready to use big data in the cloud, while also successfully transitioning their product workloads over in rapid time. This allowed the team to focus on important projects like pipeline optimization, which led to greater user delivery as well as improved stability and cost efficiency of the data operation. Critically, these improvements are helping to drive more revenue for Expedia.
Join Qubole’s future meetups to hear from other customers and learn more about Qubole.



